Инструкция по настройке и работе с key collector
Содержание:
- Парсинг
- Сбор семантики
- Время запуска программы
- Настройки в зависимости от размера семантики
- Как снять позиции сайта в Кей Коллекторе
- Почему лучше не собирать все маски в единой группе?
- Аналоги Key Collector
- Главное меню программы
- Выполнение поиска и работа с результатами
- Работа с пользовательскими группами
- Минусация
- Создание структуры
- Переименование и цветовая маркировка
Парсинг
Далее переходим к следующему шагу — жмём «Начать сбор»:
Обратите внимание: если перед добавлением слов в проект вы отключали удаление знака «+», то перед парсингом нужно вернуть его обратно. Если, конечно, вы не хотите, чтобы слова попадали в «вордстатовском» виде, например, «купить шкаф +в москве +на таганке».
И снова о важности распределения масок на группы: пока программа готовит группы «велик» и «велек», мы уже работаем с группой «велосипед»
Профит!
И снова о важности распределения масок на группы: пока программа готовит группы «велик» и «велек», мы уже работаем с группой «велосипед». Профит!
После минусовки рекомендуем «спарсить» ядро ещё несколько раз, так как у каждой собранной ключевой фразы могут быть вложенные фразы, которые не «спарсились» на первом круге. Собранное «отминусованное» ядро в таком случае будет новым списком масок.
Повторно следует «парсить» не все слова, а только высоко- и среднечастотные запросы, так как в низкочастотных вложенных запросов почти не будет.
Чтобы понять, как много вложенных запросов у конкретного слова, можно снять его частотность в широком и в точном соответствии, а затем поделить широкое на точное. Чем больше соотношение, тем больше в ключевике вложенных фраз. Это такой себе «коэффициент замусоренности». Также вложенные запросы можно почистить через прогнозатор «Яндекс.Директа». Кому как удобнее.
А после завершения парсинга не забудьте прогнать полученные фразы через инструмент KC «Анализ неявных дублей». Он поможет найти в списке дубли в стиле «купить велосипед москва» и «купить велосипеды в москве» — и удалить их по заданным условиям.
В следующей части статьи мы расскажем, как отминусовать ненужные слова, сгруппировать нужные, перенести данные в Excel и подготовить объявления для «Яндекс.Директа» или Google AdWords.
Авторы статьи:Анастасия Якунина, production-менеджер в Adventum,Артур Семикин, performance-менеджер в Adventum.
Читайте далее: Как проработать семантическое ядро с помощью Key Collector. Часть 2
Сбор семантики
Вот мы и перешли к самому вкусному. Собирать ключи можно из левой и правой колонок Вордстата. Как вы наверняка знаете, в левой показываются запросы с вхождением ключевого слова. В правой же – похожие запросы.
В этом материале мы рассмотрим именно сбор из левой колонки. Итак, нажимаем на красную иконку, после чего у нас открывается такое окно.
Здесь мы можем ввести все ключевые слова, которые нам нужны. Их можно разбить на вкладки и группы. Ключи можно вводить вручную, а можно просто выгрузить из файла.
После нажатия кнопки “Начать сбор” программа начнет свою работу. В зависимости от настроек и количества ключей этот процесс может занять определенное время. Иногда и по несколько часов. В конечном итоге вы получите список всех ключевых слов и фраз из левой колонки Вордстата.
Далее мы можем снять более точную частотность, потому как та, что будет доступна сразу после сбора, – ложная. Не стоит ей доверять и уж тем более делать какие-то выводы.
При сборе из правой колонки порядок действий тот же самый. Только ключей получится больше, в силу того, что в таблицу попадут все “похожие”.
Частотность
После сбора самой семантики, вы можете собрать частотность. Причем базовая частотность не даст нам особо полезной информации, поэтому нас интересует частотности с вхождением конкретных слов (“ “) и с точным вхождением (“!”)
Для сбора всех видов частотностей мы можем использовать одну кнопку.
Съем более точных частотностей позволит вам получить наиболее правильные статистические данные о количестве запросов в Яндексе. Базовая вариация не отражает истинную суть, и чаще всего при составлении семантического ядра она игнорируется.
Именно сбор частотности в конечном итоге позволяет вам кластеризовать семантическое ядро по запросам: ВЧ, СЧ и НЧ. Исходя из этих данных, сеошники могут разделять ключи по группам, создавая для каждой отдельной статьи свою небольшую базу из тайтла и нескольких ключевых слов. Далее эта информация передается копирайтерам для написания статей. Сейчас такой способ является наиболее популярным при работе с информационными сайтами.
Сезонность
Сезонные запросы – это ключи, которые актуальны в какое-то время года или в какое-то конкретное время. Если вы собираете семантику для магазина с пляжными товарами, то вам нужно брать в расчет наибольший спрос, а именно в летнее время.
Сбор сезонности позволит вам определить, какие запросы в какое время пользуются наибольшей популярностью. Чтобы собрать эту информацию с помощью Кей Коллектора, найдите в меню иконок кнопку “Сбор ключевых слов и статистики”.
После завершения процесса на примере графика вы сможете увидеть популярность того или иного запроса в какой-то конкретный месяц.
Вы можете получить данные по неделям, а не по месяцам, как это представлено на скриншоте. Для настройки используйте все ту же кнопку “Сбор ключевых слов и статистики”, она раскрывается, там вы и найдете соответствующий пункт.
При необходимости вы можете посмотреть более подробную информацию. Для этого просто кликните на нужной ячейке.
Время запуска программы
Программа является модульной, и при запуске подгружает все доступные и активированные пользователем модули, загружает их настройки и внедряет их в интерфейс.
Вы можете значительно сократить время запуска программы и общую производительность при выполнении базовых операций при работе с фразами, если выключите заведомо ненужные модули в «Настройках — Модули. Изменения вступят в силу после перезагрузки программы.
Советуем выключать только те модули, функциями которых вы совершенно точно не планируете пользоваться, т.к. процесс включения и отключения модулей довольно неудобный (требуется перезапуск). А цель оптимизации не усложнить работу с программой, а наоборот — сделать ее быстрее.
Настройки в зависимости от размера семантики
Настройки для небольшой семантики (от 0 до 1 000 ключей).
Дальше все настройки зависят от того какая скорость сбора семантика вам требуется, если семантика небольшая, то и времени на ее парсинг уйдет немного.
Тогда можно обойтись добавлением одного (не основного!) аккаунта Яндекса для парсинга и можно приступать.
-
Выбираем пункт меню Yandex.Direct
-
Жмем кнопку «Добавить строку»
-
Вводим логин и пароль от аккаунта Яндекса
-
Нажимаем на кнопку пуск для проверки работоспособности аккаунта
И Жмем сохранить изменения
Настройки Yandex Direct в Key Collector
Настройки для средних и больших семантик (более 1 000 ключей)Сначала теория
Для настройки парсинга средних или больших семантических ядер потребуется расширить количество потоков и соответственно количество аккаунтов Яндекс Директ для ускорения сбора ключевых фраз.
Принцип сбора заключается в том, что Key Collector используя добавленные в него аккаунты Яндекса, обращается к yandex wordstat и постранично копирует все выданные запросы по ключевой фразе (если страница полная, то запросов в левой колонке ровно 50)
далее уходит в ожидание на 25-30 секунд, для избежания бана аккаунта и после этого еще раз обращается уже к следующей странице, либо к следующей фразе. В итоге получается 100 запросов в минуту, не считая перехода на другое ключевое слово, т.е. примерно 6 000 запросов в час.
Следовательно, если требуется собрать большие семантики на 10 000 – 20 000 слов потребуется от 2 часов и более.
А если у вас сразу несколько тематик и количество ключевых фраз более 100 000? На их сбор уйдет слишком много времени.
Для увеличения скорости требуется увеличивать количество потоков, при этом скорость увеличивается ровно во столько раз сколько будет добавлено потоков.
Для этого потребуется равное количество Яндекс аккаунтов и готовых прокси серверов. Их можно приобрести на специальных площадках. В среднем, цена за один прокси + один аккаунт Яндекса — 100 рублей в месяц.
Мы используем 10 прокси и соответственно 10 аккаунтов Яндекса.
Это примерно 1 000 запросов в минуту.
Перейдем к настройке
Заходим в настройки Yandex.Wordstat и отключаем галочку напротив «Использовать основной Ip-адрес»
Здесь же выставляем количество потоков равное количеству доступных нам прокси и аккаунтов Яндекса.
Если вы приобрели 10 прокси и 8 Яндекс аккаунтов, то выставляйте 8 потоков, чтобы не повышать шансы блокировки Яндекс аккаунтов.
Настройка Yandex Wordstat в Key Collector
Для дальнейшей настройки переходим во вкладку Яндекс директ.
Жмем по кнопке добавить списком и вносим сюда все аккаунты по шаблону логин:пароль.
Настройки Яндекс Директ в Key Collector часть 1
После внесения списка аккаунтов требуется их проверить на работоспосоность:
-
Пролистываем настройки чуть ниже.
-
Нажимаем на зеленую кнопку запустить — все рабочие аккаунты отобразятся как зеленые, нерабочие красные.
-
Выставляем количество потоков
-
Снимаем галочку с использования основного ip-адреса.
Настройки Яндекс Директ в Key Collector
Переходим во вкладку «Сеть»
Вкладка Сеть настройки Key Collector
-
Здесь ставим галочку на пункте «Использовать прокси-серверы»
-
Далее нажимаем кнопку «Добавить из буфера»
Настройки Сети Key Collector
Копируем сюда прокси по шаблону адрес:порт@логин:пароль.
Настройка прокси кей коллектор
После добавления проверяем прокси также, как и с Яндекс директом, красные не рабочие, зеленые в полном порядке.
Нажимаем кнопку сохранить изменения.
Проверка прокси в кей коллектор
С настройками закончили. Данных настроек вполне хватит для сбора семантики и ее частотности. На свой страх и риск можно также протестировать настройки паузы между запросами для увеличения скорости сбора.
Как снять позиции сайта в Кей Коллекторе
Key Collector дает возможность проводить сбор позиций вашего ресурса по выбранным ключевым запросам в поисковых системах Google и Яндекс.
Для сбора позиций вам потребуется:
- Выбрать необходимые запросы.
-
В строке, расположенной в верхнем правом углу вбить URL проверяемого сайта.
- Затем в нижней панели настроить региональность.
- После чего нажать на иконку «сбор позиций сайтов в поисковой системе Яндекс или Гугл».
Также сервис может демонстрировать историю изменения позиций ресурса в поисковой выдаче. То есть вы можете наблюдать за ростом или падением сайта и проводить анализ исходя из увиденных данных. Для этого:
- Зайдите в настройки.
- Выберите «Парсинг».
- Затем кликните на «Общие».
- Выберите режим сбора «Отмеченные строки».
- После чего выделите запросы по которым вы хотите обновить сведения.
- Запустите сбор.
Новые сведения будут расположены в правой части ячейки. Если ресурс поднялся в поисковой выдаче, то цифра будет демонстрироваться в зеленом окрасе. При отрицательной динамике, цифра будет окрашена в красный и демонстрироваться со знаком минуса. Также вы можете просматривать данные показатели в виде графика или таблицы.
Если вам потребуется, вы можете экспортировать в Excel полученные сведения. Иконка для переноса данных, находится под строкой для ввода URL ресурса.
Экспорт собранных позиций сайта из Key Collector в Excel
Почему лучше не собирать все маски в единой группе?
Во-первых, при большом количестве масок Key Collector работает медленно (но в разы быстрее, чем человек). Когда у вас «спарсится» первая подгруппа, вы уже сможете с ней работать — минусовать, группировать, анализировать. Параллельно будут собираться и остальные подгруппы. Этот подход здорово экономит время, когда нужно оперативно «спарсить» маски.
Во-вторых, если ядро новое и незнакомое, вы не знаете, как поведёт себя та или иная маска. Некоторые из них (на вид безобидные ) могут оказаться чертовски мусорными. Например, при сборе РК по видеонаблюдению в маске «камера школа» мы нашли уйму порно и куда меньше запросов о видеонаблюдении. Если решите собирать всё в одной группе, а в список попадёт такая маска, у вас в один лист «спарсится» 10 000 слов, 5000 которых будут мусорными.
В результате вам придётся несколько часов вычищать неподходящие фразы. Разумнее парсить в разные группы — тогда маска «камера школа» будет стоять особняком.
Другая крайность: масок очень много (больше 200–300). Раскидывать их по отдельным группам долго, да и нагрузка на программу неоправданно высокая. В таком случае создаём отдельную группу не под одну, а под несколько масок, желательно близких по смыслу. Обычно это столбцы или строки из нашей матрицы масок. Для этого приёма необходимо выбрать способ группировки (например, по столбцам):
Затем копируем заголовки групп и вставляем их в инструмент сбора Key Collector, жмём «Распределить все фразы по одноимённым группам» — и получаем список выбранных групп:
Удаляем из них первые слова (это просто названия столбцов) и вставляем сами группы:
Важный момент. Если используете в списке масок операторы или минус-слова, перед добавлением этих слов в Key Collector проверьте в настройках, не включено ли автоматическое удаление символов:
В противном случае фраза «Шкаф +в Москве — холодильный» отправится на парсинг как «Шкаф в Москве холодильный».
Аналоги Key Collector
Существует несколько программ, схожих с Кей Коллектором по своему функционалу и свойствам, вот перечень некоторых из них:
- SLovoeb — бесплатная копия KC, в которой срисован даже дизайн. Основные отличия заключаются в том, что Слово*б имеет ряд ограничений в плане количества опций. А именно, потенциал программы сопряжен с поисковыми системами Рунета, такими как Яндекс. Прочие настройки и опции почти ничем не отличаются от KC.
- Rush Ananlytics — программа, направленная на сбор аналитических сведений по ключевым словам. С ее помощью вы можете проводить сбор и дальнейшую кластеризацию запросов в группы. Данный сервис интегрирован с Вордстатом, следовательно, он может собирать сведения из WordStat и находить схожие по значению запросы. Затем вы можете группировать ключевые фразы исходя из полученных сведений по выдаче поисковой системы. К тому же с его помощью можно снимать позиции сайта в поисковой выдаче Гугл и Яндекс.
- Мутаген — очень простой и понятный в использовании сервис. С его помощью вы сможете без труда спарсить ключевые фразы для сайта по которым большое количество запросов и почти нет конкуренции. Расчет количества конкурентов происходит исходя из ТОП 30 ресурсов. Численность показов рассчитывается за последние 30 дней. Следовательно, используя данную программу, вы будете располагать актуальными сведениями.
Главное меню программы
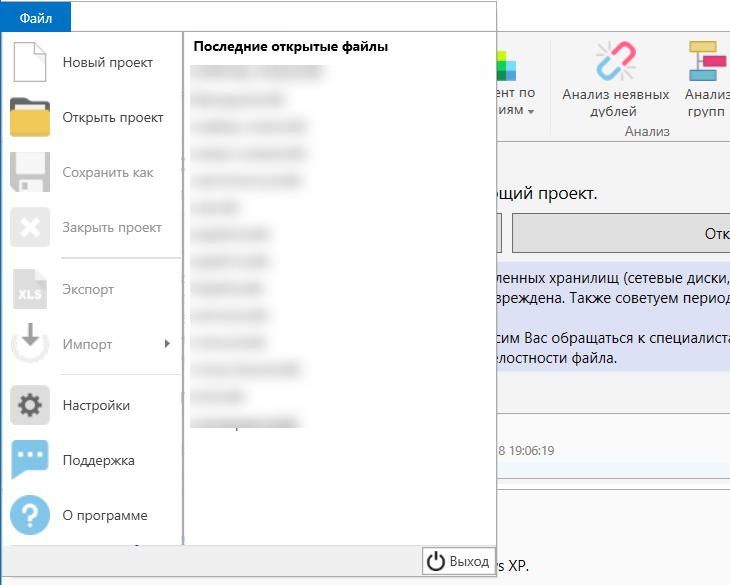
Для того, чтобы попасть в меню нам нужно в верхнем правом углу выбрать “Файл”.

Добро пожаловать в Key Collector!
В появившемся меню вы можете создать новый файл или открыть уже ранее существующий проект, импортировать данные из другого проекта или файла в формате CSV.
Загрузка проекта
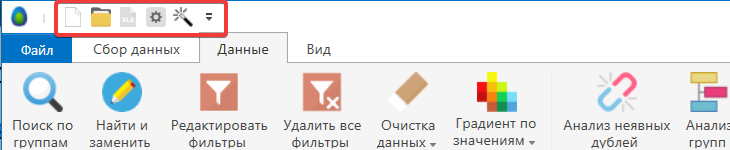
Меню быстрого доступа
Используя меню быстрого доступа вы можете добавить наиболее часто используемые кнопки.
Меню быстрого доступа
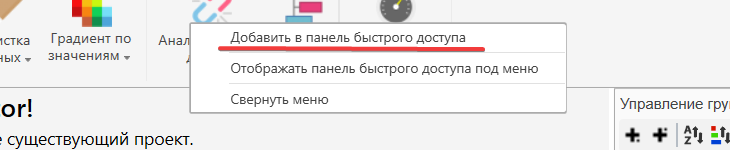
Для добавления новых элементов нужно правой кнопкой мышки нажать на интересующий значок. После чего в появившемся окне выбрать пункт “Добавить в панель быстрого доступа”
Добавить в палень быстрого доступа
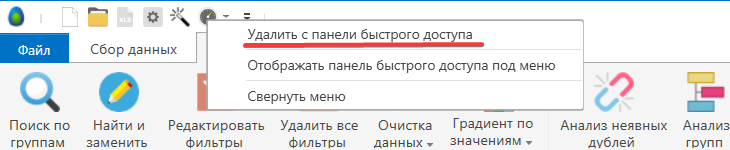
Теперь данный элемент будет добавлен в меню. Если вы захотите удалить кнопку из меню быстрого доступа, тогда проделайте аналогичные действия: нажмите правой кнопкой мышки на иконку и дальше в меню выберите “Удалить с панели быстрого доступа”.
Удалить с панели быстрого доступа
Основная рабочая область
Основную рабочую область используют для отображения пользовательских групп и экрана приветствия после запуска программы. В ней вы можете ознакомиться со свежими новостям относительно программы, увидеть статистику хода выполнения работы и т.д.
Область новостей, журнала событий и статистика

Область новостей, журнала событий и статистика
Данная вкладка предназначена для:
-
Отображения журнала событий.
-
Получения последних новостей программы.
-
Просмотра статистики по текущему выполнению задач.
-
Просмотра дополнительных данных статистики: отображение списка релевантных страниц, графиков истории позиций, сезонности, поисковой выдачи и тд.
Под просмотром дополнительной статистики имеется в виду просмотр тех данных, которые не могут быть показаны в стандартных таблицах и выводятся для каждой фразы в отдельности. К дополнительной статистике принадлежит:
-
Просмотр количества акноров с помощью сервиса Solomono. Используем кнопку “Количество анкоров Solomono”.
-
Просмотр с помощью графика или в виде таблицы истории позиций. Для этого нажимаем “Позиция Yandex” и “Позиция Google”.
-
Просмотр состава поисковой выдачи по какому-либо запросу: адреса страниц, заголовки, сниппеты. Для этого используем «Кол-во вхождений в заголовок «, «Кол-во вхождений в заголовок » и «Кол-во вхождений в заголовок «.
-
Просмотр релевантных страниц — колонки «Рел. страница » и «Рел. страница «.
-
Просмотр частотности слов по месяцам для Google Adwors — колонка «Частотность (регионы) »
-
Просмотр частотности для Yandex Wordstats по неделям и месяцам. Для этого переходим в раздел «Сезонность «.
Для того, чтобы увидеть данную статистику надо выбрать нужную фразу и перейти во вкладку “Дополнительная статистика”. В этом меню будет доступна интересующая подвкладка с дополнительной статистикой.
Отображение вкладок можно настроить на свое усмотрение. Для этого надо зажать левую кнопку мышки на заголовок с вкладкой и перетащить в нужную сторону.

Отображение вкладок
Панель состояния
Панель состояния нужна для показа информации о количестве отмеченных строк и информацию об использовании автоматической капчи.

Панель состояния
Выше выделена кнопка принудительного обновления содержимого активной таблицы.
Выполнение поиска и работа с результатами
Итак, после выбора группы минус-слов, формирования списка минусации и установки настроек вы можете выполнить поиск.
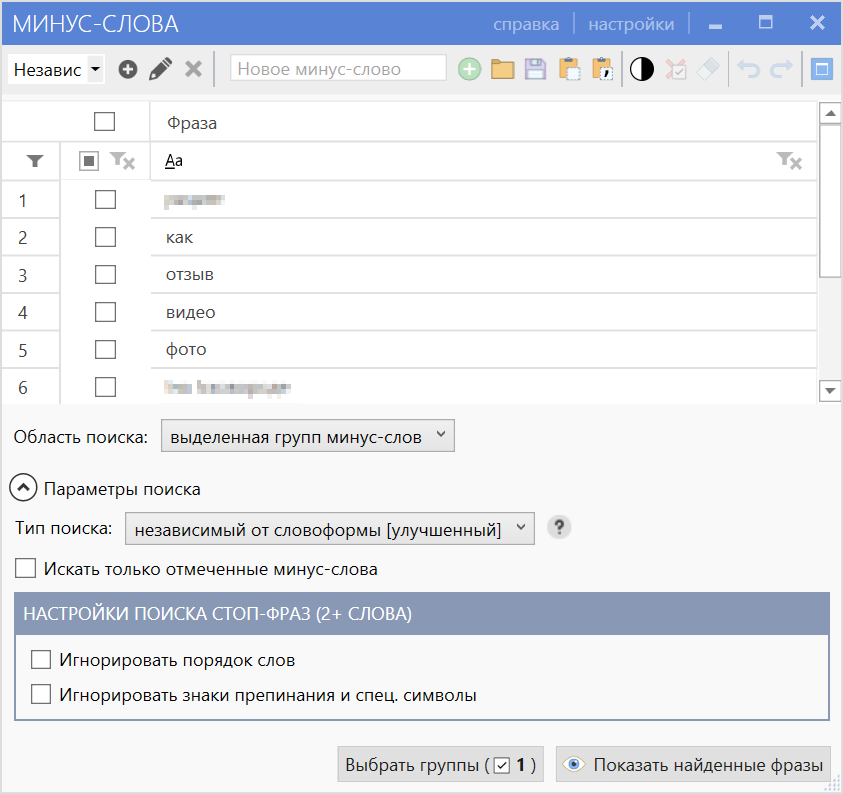
По завершении поиска открывается временная мультигруппа с результатами.
В ленте инструментов при этом будет добавлена контекстная вкладка «Предпросмотр», которая позволит управлять временной мультигруппой.
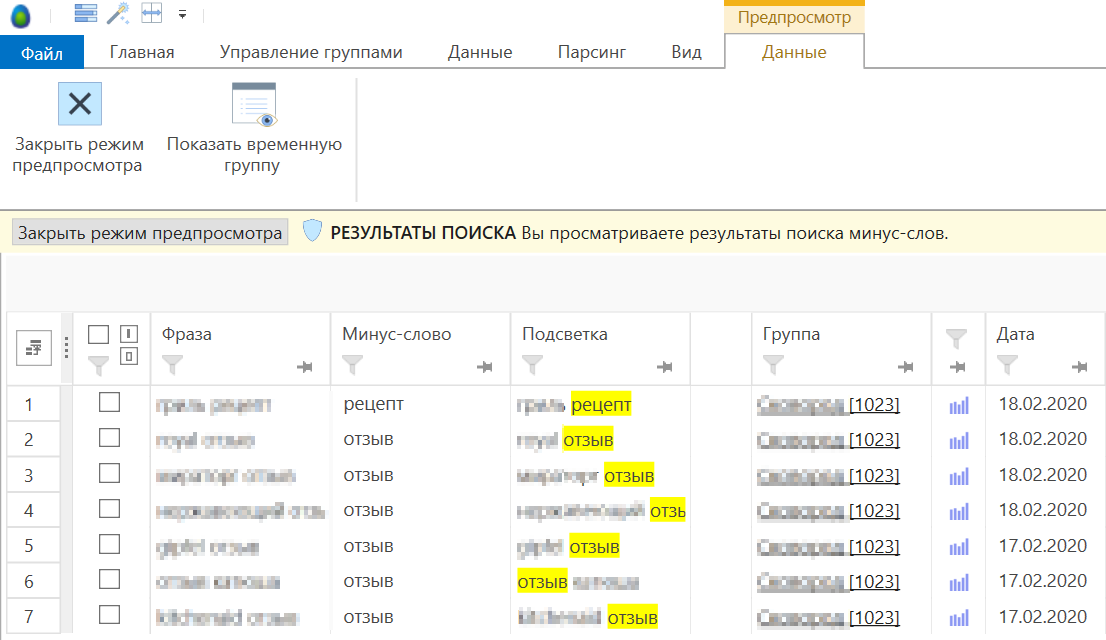
Таблица результатов содержит колонку подсветки, где отображается подсказка по найденному минус-слову в исходной фразе, а само найденное минус-слово отображается в колонке «Минус-слово».
Вы можете работать с результатами поиска в мультигруппе как с обычной мультигруппой: сортировать данные, применять фильтры, отмечать и удалять строки, запускать парсинг и т.д.
В колонке«Группа»отображается название целевой группы, где была найдена фраза из указанных групп-источников. Вы можете перейти внутрь этой целевой группы, зажав клавишуCtrlи кликнув по ее названию.
Работа с пользовательскими группами
В Key Collector можно создавать пользовательские группы. Каждая группа будет содержать свою собственную таблицу с данными. Вы можете переносить или копировать ключевые слова из одной группы в другую с помощью специального инструмента.
Создание новой группы
Для создания новой группы можно воспользоваться одной из двух кнопок с изображением плюсика. Они находятся в панели управления. Или вы можете воспользоваться сочетанием быстрых клавиш Ctrl + T.

Создание новой группы
Если в вашем проекте группы имеют определенную вложенность, тогда новую группу можно создать сразу внутри другой группы. Для этого выделим первоначальную группу и нажмем на инструмент “Создать новую группу внутри”. Для удобства можете воспользоваться клавишами Ctrl + Shift + T
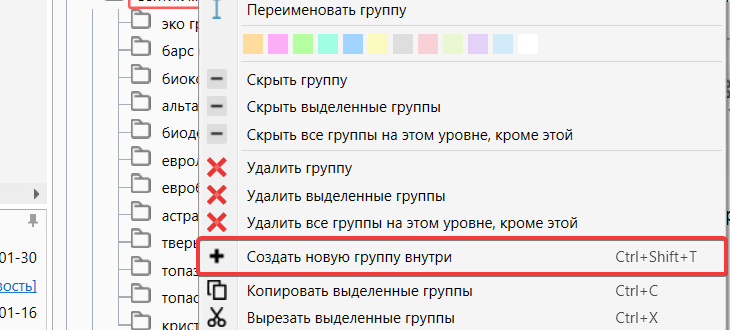
Создать новую группу внутри
Новую группу объявлений можно создать с помощью альтернативного способа. Для этого перейдем в раздел “Сбор данных”, после чего выбираем инструмент “Перенос фраз в другую группу” и в нем уже выбираем “Создать новую группу”

Создаем новую группу
Перемещение группы
В Key Collector реализован удобный механизм переноса групп. С помощью него можно выстроить такую цепочку вложенности, с которой удобнее всего работать. Для того, чтобы сделать надо выделить одну или несколько групп, зажать левую кнопку мышки и перенести в нужное место.
Перемещение группы
Переименование группы
Вы можете переименовать название групп. Для этого надо два раза кликнуть левой кнопкой мышки по ее заголовку. В появившейся строке задайте нужное имя. Для отмены можете нажать клавишу Esc, для сохранения изменений — клавишу Enter.
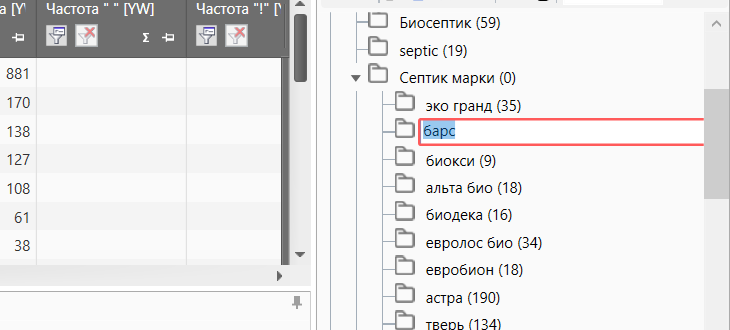
Переименование группы ч.1
Другим способом переименовать группу можно с помощью нажатия правой клавиши мышки и выбрать соответствующий пункт.

Переименование группы ч.2
Сортировка групп
В Key Collector можно сортировать группы используя названия или цвет заголовка.
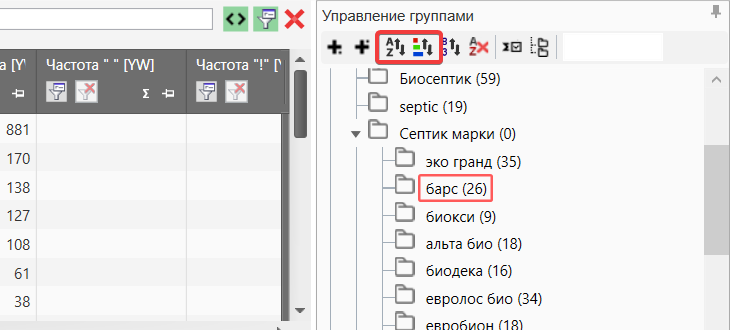
Сортировка групп
Данная функция находится в разделе управления группами. Очень удобный инструмент, если вы хотите сделать сортировку.
Удаление группы
Для того, чтобы удалить группы нужно выбрать соответствующий пункт, который показан на скриншоте ниже. Можно выделить несколько групп используя быстрые клавиши CTRL или SHIFT
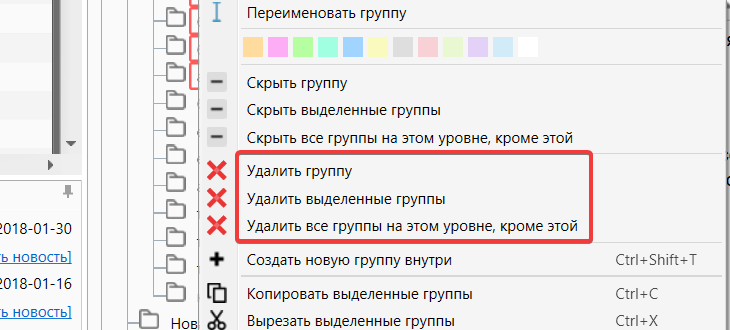
Удаление группы
Группы, которые вы удалите сперва будут скрыты. Данная функция полезна, если в процессе работы вы передумали удалять группу. Данные группы будут автоматически удалены по завершении работы Кей Коллектра.
Сокрытие группы
Для удобства реализована функция “Скрыть группы”. С помощью нее вы можете скрывать ненужные пользовательские группы.

Сокрытие группы
Для того, чтобы заново отобразить скрытые ранее группы, нужно нажать на иконку в разделе “Управления группами”.
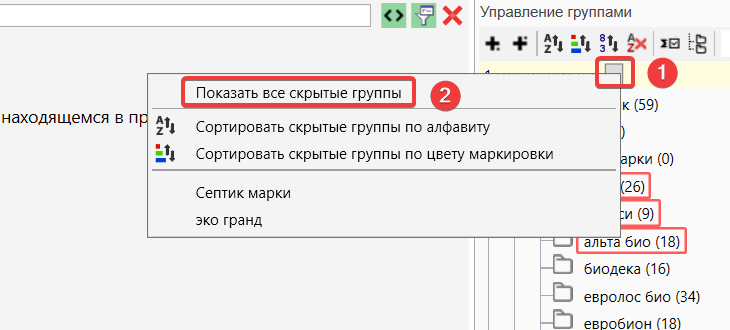
Показать все скрытые группы
Колорирование группы
Вы можете назначить для каждой группы свой цвет. Для этого надо выбрать соответствующий цвет в палитре расположенной в контекстном меню.Нажимаем правой кнопкой мышки на нужную группу и выбираем цвет.
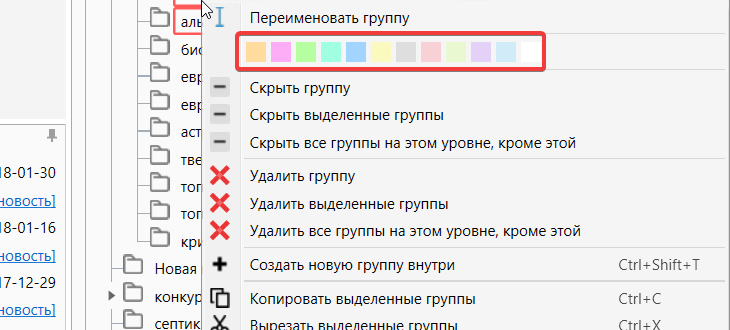
Колорирование группы
Минусация
Для того, чтобы очистить от ненужных слов собранные поисковые запросы потребуется:
Зайти во вкладку «Данные»
Нажимаем на кнопку «Анализ групп»
Анализ групп в Кей Коллектор
С помощью инструмента анализ групп можно быстро как разгруппировать, так и определить минус слова из собранных ключевых фраз.
Инструмент разбивает полученные ключевые фразы на отдельные слова и объединяет фразы в которых они присутствуют.
Разберем на примере:
Анализ групп в Key Collector
На скриншоте показан анализ групп по натяжным потолкам.
Напротив каждого слова проставлено количество фраз встречаемых с этим словом и суммарная их частотность.
Представим, что в дальнейшем нам потребуется создать кампанию на поиске.
Мы видим, что в верху списка есть слово фото, явно это свидетельствует о том, что человек ищет не рекламный запрос в поиске а именно фотографии с натяжными потолками. Напрямую по этому запросу рекламироваться нет особого смысла, а следовательно фото мы должны отправить к минус словам.
Минус слово в Key Collector
Для этого напротив слова ставим галочку и продолжаем поиск таких слов.
Когда запросов много советую сначала выстроить таблицу по частотности и отметить самые высокочастотные минус слова, дальше сортировать по алфавиту и пробежаться по всему списку, лучше пару раз.
После определения всех минус-слов, нажимаем правой кнопкой мыши по одному из отмеченных и выбираем пункт «Отправить 1-е слово из определений целиком отмеченных групп в окно стоп-слов»
Добавление фразы в окно стоп-слов
В открывшемся окне снимаем галочки с тех слов, которые попали сюда по ошибке. Советую снять галочки со всех слов и заново отметить те слова, которые требуется занести в минусы.
Жмем «Добавить в стоп-слова»
Окно стоп-слов в Кей коллектор
После добавления фраз в стоп-слова сворачиваем анализ групп.
Переходим во вкладку «Сбор данных», затем нажимаем на кнопку перенос фраз в другую группу и выбираем папку корзина.
Добавления фраз в корзину Key collector
Не удаляйте ненужные ключевые фразы, а перемещайте их в корзину, потом всегда можно запарсить новые слова с учетом уже собранных или же слова могут подойти для РСЯ.
Разгруппировка
Заключительным этапом перед экспортом работы в Key Collector будет разгруппировка ключевых фраз.
Для разгруппировки отлично подойдет карта мыслей, которую мы составляли в самом начале.
Легче всего начинать с общих названий услуг.
К примеру:
- Глянцевый
-
Матовый
Многоуровневый
- Тканевый
- Пвх
Дальше разгруппируйте еще более точней
- Глянцевый
- кухня
- ванная
- гостинная
- спальня
- Матовый
- кухня
- ванная
- гостиная
- спальня
И так далее, главное помнить, что в Яндексе статус «Мало показов» распространяется на группу объявлений и появляется при общей частотности группы меньше 20, из этого правила группируйте низкочастотные запросы с небольшим запасом на группу.
Для Google AdWords низкочастотные запросы не подойдут, так как там статус присваивается для ключевого слова, а не группы.
Для начала разгруппировки заходим в «Анализ Групп»
Отмечаем нужное нам слово галочкой и нажимаем правой кнопкой мыши по нему.
Выбираем пункт предпоследний пункт выпадающего меню.
Разгруппировка слов в Key Collector
В нашей группе автоматически создается новая папка с названием слова, которые мы выбрали и все слова, в которых это слово входило перенеслись в эту группу.
После разгруппировки основной группы переходим к тем, которые мы создали и также их дробим на подгруппы.
Таким образом, нам будет проще прописать текст объявлений в будущем.
По такому аналогу и распределяем на группы всё семантическое ядро.
В дальнейшем, названия этих папок будут служить нам как названия групп объявлений как в Директе так и в AdWords.
Создание структуры
Результаты группировки могут быть перенесены в проект через создание структуры.
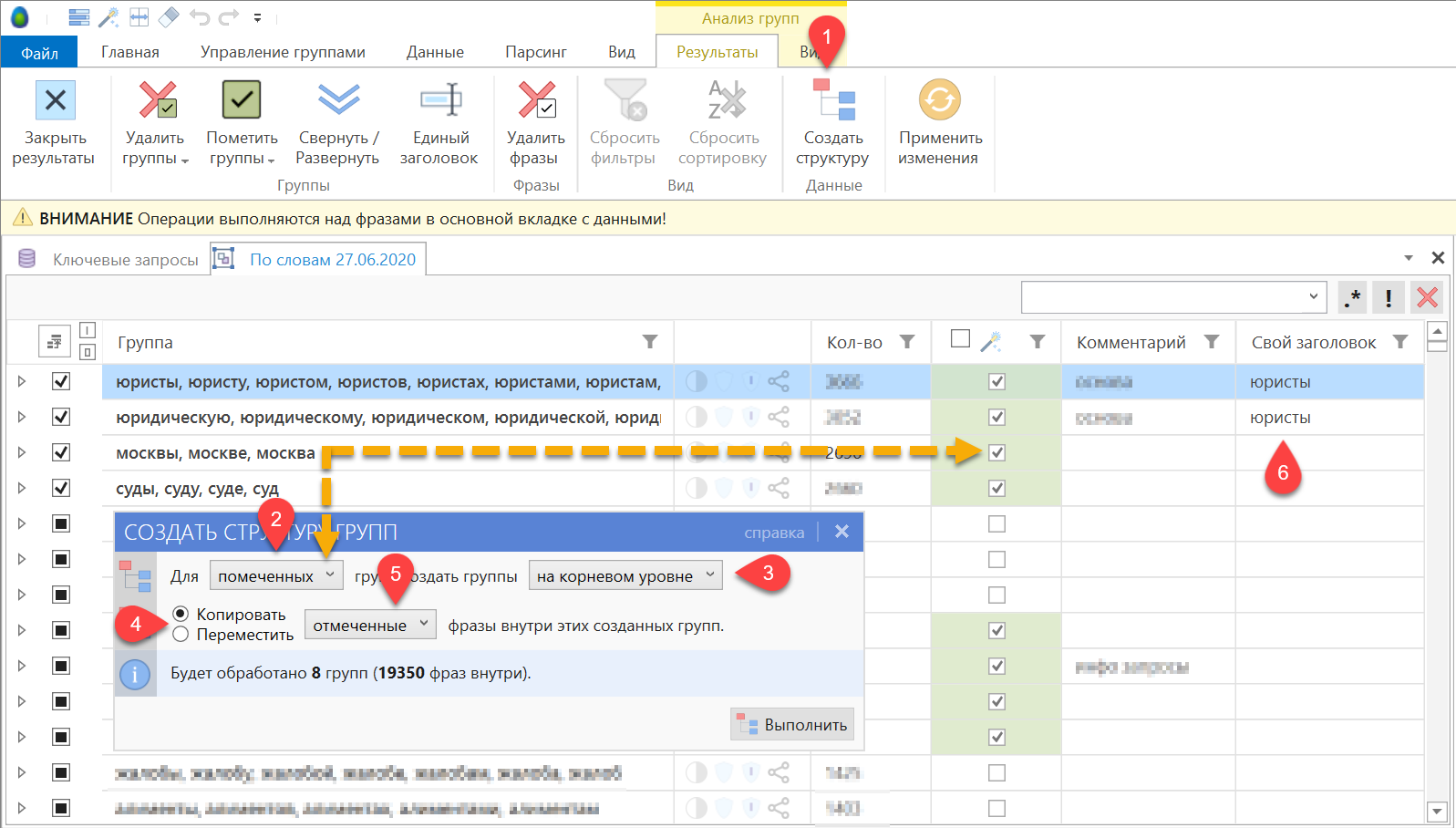
Шаг 1. Нажмите кнопку «Создать структуру» на панели инструментов. Откроется окно параметров выполнения операции.
Шаг 2. Структура может быть создана для помеченных или выделенных групп. Как правило, удобней работать с помеченными группами. находится справа от названия группы, помеченные группы подсвечиваются зеленым цветом (см. скриншот).
Не перепутайте колонку пометки групп и колонку группового статуса отметки фраз внутри группы!
Шаг 3. Выбранные на шаге 2 группы могут быть созданы на корневом уровне проекта или внутри активной группы. Выберите подходящий режим.
Шаг 4. Выберите тип операции: копирование или перенос. При переносе одна и та же фраза может быть перенесена только единожды, т.е. она не будет продублирована во все целевые группы.
Шаг 5. Выберите источник фраз: только отмеченные фразы или все фразы сформированной группы.
Шаг 6. Для достижения эффекта этот шаг нужно выполнять в самом начале перед вызовом инструмента создания структуры. По умолчанию группы создаются в проекте с автоматически сформированными заголовками, однако вы можете переопределить заголовок группы на свой более подходящий. Если несколько групп будут иметь одинаковый заголовок, то их фразы попадут в общую группу с определенным самостоятельно заголовком (дублирования групп не произойдет).
Переименование и цветовая маркировка
Для переименования группы дважды кликните по ее заголовку или воспользуйтесь соответствующим пунктом в контекстном меню.
Для массового редактирования заголовков можно воспользоваться функциями в меню «Формат заголовков» на вкладке «Управление группами».
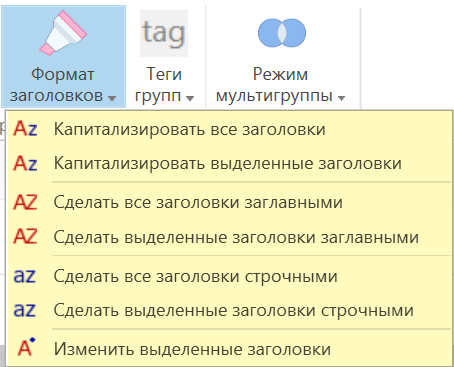
Вы также можете помечать цветами заголовки групп. Для пометки нескольких выделенных групп зажмите клавишу Ctrl.
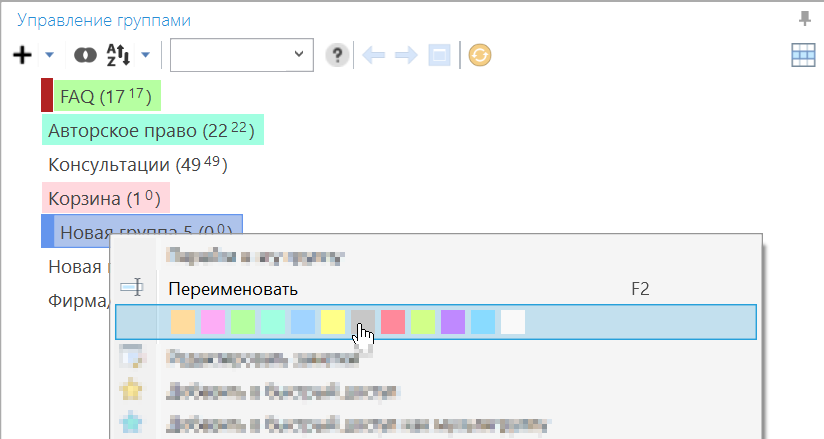
В «Настройках — Интерфейс — Управление группами» можно задать список цветов в формате цветов HTML (HEX ARGB).
Массовое переименование групп по маске
Функция изменения выделенных групп позволяет массово изменить заголовки выделенных групп по заданному пользователем шаблону. Например, можно не только назначить нескольким группам новый единый заголовок, но и сохранить в нем значения прошлых заголовков.
Группы «кастрюли», «сковородки», «чашки» могут быть переименованы в «кастрюли Москва», «сковородки Москва», «чашки Москва» (в существующему заголовку добавлено слово «Москва»). Или же можно выполнить замену части заголовка: «кабель 2.5», «провод 2.5» на «кабель 1.75», «провод 1.75» (выполнена замена 2.5 на 1.75).
Простые замены
Простая замена может использовать в маске макрос {HEADER}, который вставит на место {HEADER} прошлое значение заголовка группы.
Например, маска «купить {HEADER} Москва» превратит группы «носки», «колготки» в «купить носки Москва», «купить колготки Москва».
Слайсинг в стиле numpy
Помимо простой замены с сохранением полного прошлого заголовка иногда требуется модифицировать прошлый заголовок: отрезать какую-то его часть с начали или конца, использовать какую-то информацию из середины и т.п.
Для этих нужд используется широко известный синтаксис слайсинга в numpy (библиотека Python), поэтому если вы его освоите, то это пригодится не только при работе с Key Collector, но и для решения других задач.
Вы можете извлекать наборы символов (подстроки), задавая границы и длину строк с начала или с конца. Приведем несколько примеров.
Отрезать начало строки — {HEADER}N:
Можно указать индекс начала строки N с начала или с конца.
- {HEADER}4: — взять подстроку, начиная с 4-го символа с начала и до конца
- мск интернет —> интернет
- {HEADER}-5: — взять подстроку, начиная с 5-го символа с конца и до конца
-
блин 25 кг
—> 25 кг
Отрезать конец строки — {HEADER}:M
Можно указать индекс конца строки M с начала или с конца.
- {HEADER}:8 — взять подстроку, начиная с начала и до 8-го символа
- интернет мск —> интернет
- {HEADER}:-6 — взять подстроку, начиная с начала и заканчивая 6-м символом с конца
- саженцы москва —> саженцы
Взять из середины строки — {HEADER}N:M
Здесь можно указать индекс начала N и конца M подстроки. Аналогично можно указывать индексацию с начала или с конца строки, но индекс конца M должен быть расположен в абсолютном значении дальше индекса начала N.
- {HEADER}4:6 — взять подстроку, начиная с 4-го символа и заканчивая 6-м символом
- 122.65 частота —> 65
Функции замены
Поддерживается функция замены значения в заголовке на новое значение REPLACE(«old»;»new»). Использовать дополнительную индексацию или маску в параметрах функции не допускается (т.е. в кавычках должны быть заданы обычные слова или части слов.
- REPLACE(«мск»;»спб») — заменить в заголовке «мск» на «спб»
- ворота мск —> ворота спб
Также поддерживается расширенная функция замены по регулярному выражению REPLACERG(«pattern»;»replacement»). Опытные пользователи могут выполнять более сложные замены, используя синтаксис регулярных выражений.




