Игра в прятки с оптимизатором. гейм овер, это cte postgresql 12
Содержание:
- 8.1.3. Floating-Point Types
- 4KB
- Групповые привилегии
- Hello Postgres
- Собираем метрики
- Сообщество PostgreSQL
- Повышение производительности
- вести и отставать
- Настройка запросов
- datagrip
- Расширения базы данных
- Утилиты (программы) PosgreSQL:
- Установка RedHat Enterprise Linux 8 (RHEL 8.4). Подключение RHEL8 к домену Active Directory. Запуск терминального клиента.
- Запуск скрипта из файла
- Инициализация структуры БД
- Наивно используем полнотекстовый поиск
- Установка платформы 1С 8.3.20.1363 и более старших версий на RHEL8 и любые другие rpm-based linux. Решение проблемы установки меньших версий 1С8.3 (webkitgtk3) на RHEL 8 / CentOS 8 / Fedora Linux
- Создаем собственные типы
8.1.3. Floating-Point Types
The data types real and double precision are inexact, variable-precision
numeric types. In practice, these types are usually
implementations of IEEE
Standard 754 for Binary Floating-Point Arithmetic (single and
double precision, respectively), to the extent that the
underlying processor, operating system, and compiler support
it.
Inexact means that some values cannot be converted exactly
to the internal format and are stored as approximations, so
that storing and retrieving a value might show slight
discrepancies. Managing these errors and how they propagate
through calculations is the subject of an entire branch of
mathematics and computer science and will not be discussed
here, except for the following points:
-
If you require exact storage and calculations (such as
for monetary amounts), use the numeric type instead. -
If you want to do complicated calculations with these
types for anything important, especially if you rely on
certain behavior in boundary cases (infinity, underflow),
you should evaluate the implementation carefully. -
Comparing two floating-point values for equality might
not always work as expected.
On most platforms, the real type has a
range of at least 1E-37 to 1E+37 with a precision of at least 6
decimal digits. The double precision type
typically has a range of around 1E-307 to 1E+308 with a
precision of at least 15 digits. Values that are too large or
too small will cause an error. Rounding might take place if the
precision of an input number is too high. Numbers too close to
zero that are not representable as distinct from zero will
cause an underflow error.
In addition to ordinary numeric values, the floating-point
types have several special values:
Infinity-InfinityNaN
«infinity»»negative infinity»»not-a-number»UPDATE
table SET x = 'Infinity'
PostgreSQL also supports
the SQL-standard notations float and
float(p)
for specifying inexact numeric types. Here, p specifies the minimum acceptable
precision in binary
digits. PostgreSQL accepts
float(1) to float(24) as selecting the real type, while float(25) to
float(53) select double
precision. Values of p
outside the allowed range draw an error. float with no precision specified is taken to mean
double precision.
4KB
Типично мы пишем вот такой цикл, чтобы получать данные из базы:
Внутри драйвера мы получаем данные, накапливая их в буфер размером 4KB. порождает поход в сеть и наполняет буфер. Если буфера не хватает, то мы идём в сеть за оставшимися данными. Больше походов в сеть – меньше скорость обработки. С другой стороны, так как предел буфера – 4KB, не забьём всю память процесса.
Но, конечно, хочется выкрутить объём буфера на максимум, чтобы уменьшить кол-во запросов в сеть и снизить latency нашего сервиса. Добавляем такую возможность и попробуем выяснить ожидаемое ускорение на синтетических тестах:
Видно, что большой разницы по скорости обработки нет. Почему так?
Оказывается, мы упираемся в размер буфера на отправку данных внутри самого Postgres. Этот буфер имеет размер в 8KB. Используя можно увидеть, что ОС возвращает байта в системном вызове read. А это подтверждает размером пакетов.
Tom Lane (один из основных разработчиков ядра Postgres) это комментирует так:
Andres Freund (разработчик Postgres от EnterpriseDB) считает, что буфер в 8KB не лучший вариант реализации на сегодняшний день и нужно тестировать поведение на других размерах и с другой конфигурацией сокета.
Отдельно надо вспомнить, что у PgBouncer тоже есть буфер и его размер можно конфигурировать параметром .
Групповые привилегии
Роль получает привилегии своих групповых ролей. Нужно ли ей будет для получения привилегий выполнять SET ROLE зависит от атрибута роли, который мы можем указать при создании роли, как было показано на предыдущем уроке:
- INHERIT – атрибут роли, который включает автоматическое наследование привилегий;
- NOINHERIT – атрибут роли, который требует явное выполнение SET ROLE.
В 13 PostgreSQL при инициализации кластера создаются следующие роли вместе с суперпользователем postgres:
- pg_signal_backend – право посылать сигналы обслуживающим процессам, например можно вызвать функцию pg_reload_conf() или завершить процесс с помощью функции pg_terminate_backend();
- pg_read_all_settings – право читать все конфигурационные параметры, даже те, что обычно видны только суперпользователям;
- pg_read_all_stats – право читать все представления pg_stat_* и использовать различные расширения, связанные со статистикой, даже те, что обычно видны только суперпользователям;
- pg_stat_scan_tables – право выполнять функции мониторинга, которые могут устанавливать блокировки в таблицах, возможно, на длительное время;
- pg_monitor – право читать и выполнять различные представления и функции для мониторинга. Эта роль включена в роли pg_read_all_settings, pg_read_all_stats и pg_stat_scan_tables;
- pg_read_server_files – право читать файлы в любом месте файловой системы, куда имеет доступ postgres на сервере. А также выполняя копирование и другие функции работы с файлами;
- pg_write_server_files – право записывать файлы в любом месте файловой системы, куда имеет доступ postgres на сервере. А также выполнять копирование и другие функции работы с файлами.
- pg_execute_server_program – право выполнять программы на сервере (от имени пользователя, запускающего СУБД).
Hello Postgres
Официальный образ Постгреса очень продвинутый и позволяет настраивать множество параметров. Для быстрого старта большинство из них можно оставить как есть, но вот пароль суперпользователя придётся задать явно:
Эта команда запустит нам контейнер PostgreSQL в фоновом (detached) режиме и присвоит ему имя habr-pg:
 Контейнер с PostgreSQL, запущенный в Docker
Контейнер с PostgreSQL, запущенный в Docker
Классно, не правда ли? А что мы можем делать с этой базой данных? К сожалению, на текущий момент не так уж и много. Через интерфейс Docker можно запустить CLI, подключиться к контейнеру и уже оттуда запустить, например, psql:
Далее я буду использовать сокращенный вариант этой команды:
И тут мы сталкиваемся с первой проблемой: что вернёт нам запрос , выполненный в консоли? Мы не указали явным образом версию БД, которую хотим использовать. Давайте это исправим:
Теперь вопросов об используемой версии БД не возникает, но работать с ней по-прежнему не очень удобно. Нам нужно сделать эту БД доступной извне, чтобы к ней могли подключаться приложения и IDE. Для этого нужно выставить наружу порт:
Отлично! С этого момента к базе данных можно подключиться, например, из IntelliJ IDEA:
 Настройка подключения к БД в IntelliJ IDEA
Настройка подключения к БД в IntelliJ IDEA
Сейчас мы используем пользователя и базу данных в контейнере, создаваемых по умолчанию, я же предпочитаю указывать их явно. Финальная версия команды для запуска будет иметь вид:
psql можно запустить так:
И соответствующий compose-файл:
Собираем метрики
На самом деле лить счетчики по всем запросам в мониторинг достаточно дорого. Мы решили, что нас интересует только TOP-50 запросов, но нельзя просто взять top по total_time, так как если у нас появится новый запрос, его total_time еще долго будет догонять старые запросы.
Мы решили брать top по производной (rate) total_time за минуту. Для этого раз в минуту агент вычитывает pg_stat_statements целиком и хранит предудущие значения счетчиков. По каждому счетчику каждого запроса вычисляется rate, потом мы пытаемся дополнительно объединить одинаковые запросы, которые pg посчитал разными, их статистики суммируются. Дальше берем top, по ним делаем отдельные метрики, остальные запросы суммируем в некий query=»~other».
В итоге мы получаем 11 метрик для каждого запроса из топа. Каждая метрика имеет набор уточняющих параметров (меток):
- postgresql.query.time.cpu (мы просто вычли из total_time времена ожидания диска для удобства)
- postgresql.query.time.disk_read
- postgresql.query.time.disk_write
- postgresql.query.calls
- postgresql.query.rows
- postgresql.query.blocks.hit
- postgresql.query.blocks.read
- postgresql.query.blocks.written
- postgresql.query.blocks.dirtied
- postgresql.query.temp_blocks.read
- postgresql.query.temp_blocks.written
Сообщество PostgreSQL
PostgreSQL располагает весьма активным и организованным сообществом, всегда готовым прийти на помощь. За последние 8 лет сообщество выпустило восемь основных версий. Разработчикам рассылаются объявления в еженедельном бюллетене.
Существуют десятки списков рассылки, сгруппированных по категориям, например: пользователь, разработчик, ассоциация. В качестве примеров упомянем списки pgsql-general, psql-doc и psql-bugs. Для начинающих особенно важен список pgsql-general. В нем обсуждаются любые вопросы, касающиеся установки, настройки, основ администрирования, возможностей PostgreSQL, ведутся дискуссии на общие темы — в общем, всё, кроме ошибок.
Сообщество PostgreSQL поддерживает службу агрегирования блогов Planet PostgreSQL. Некоторые разработчики и компании с ее помощью делятся своими знаниями и опытом.
Повышение производительности
По словам разработчиков, новая версия PostgreSQL работает гораздо продуктивнее предшественниц. В отдельных тестах удалось добиться двукратного ускорения обработки данных. Кроме того, оптимизация управления данными в бинарных деревьях привела к уменьшению раздувания индексов в таблицах, где они часто обновляются.
Свежий релиз поддерживает конвейерную обработку запросов к базе данных. Это потенциально улучшит производительность приложений при соединениях с высокой задержкой и рабочих нагрузок с множеством мелких операций записи (INSERT / UPDATE / DELETE). Так как конвейерная обработка запросов – по сути, клиентская функция, ее можно использовать с любой современной базой данных PostgreSQL с клиентом версии 14 или драйвером, созданным с версией 14 интерфейса libpq.
Распределенные базы данных также должны выиграть от перехода на PostgreSQL 14. В новой версии при использовании логической репликации может передавать подписчикам выполняющиеся транзакции, и если они достаточно крупные, вы получите выигрыш в скорости. Наконец, появился вакуумный «аварийный режим»: он предотвратит зацикливание идентификатора транзакции.
Параллелизм запросов можно использовать в сторонних оболочках (wrappers). Пока эта возможность реализована в postgres_fdw, которая взаимодействует с другими базами данных PostgreSQL, но в будущем войдет в число основных компонентов системы. К слову, с postgres_fdw теперь можно проводить массовую вставку данных в сторонние таблицы и импортировать целые разделы с помощью директивы IMPORT FOREIGN SCHEMA.
В PostgreSQL 14 появилась расширенная статистика для выражений. А сохраненные процедуры, которые позволяют управлять транзакциями в блоке кода, теперь умеют возвращать данные через OUT-параметры.
вести и отставать
Функции lead () и lag () перемещают строки в наборе результатов. Типичный вариант использования — рассчитать разницу в производстве в разные годы:
Прежде чем рассчитывать изменение вывода, давайте посмотрим, что делает функция lag (). Как видите, столбец перемещен на одну строку вниз. Данные, подлежащие перемещению, определяются ORDER BY. Следующий расчет прост:
Функция lag () имеет два параметра. Первый — это отображаемый столбец. Второй параметр сообщает PostgreSQL, сколько строк вы хотите переместить. Функция lead () перемещается вверх:
Конечно, lag () и lead () также принимают отрицательные значения. Функция lag () также может перемещать всю строку:
Однако при этом PostgreSQL объединяет всю строку в один столбец, с которым сложно работать. Мы можем использовать круглые скобки и *:
Какая от этого польза? Его можно использовать для проверки того, были ли данные вставлены несколько раз — он может обнаруживать повторяющиеся строки:
Настройка запросов
Заметка о кеше данных и издержках
ИндексыИсключите последовательное сканирование (Seq Scan), добавив индексы (если размер таблицы не мал)
При использовании многоколоночного индекса убедитесь, что вы обращаете внимание на порядок, в котором вы определяете включенные столбцы — Дополнительная информация
Попробуйте использовать индексы, которые очень избирательны к часто используемым данным. Это сделает их использование более эффективным.
Условие ГДЕИзбегайте LIKE
Избегайте вызовов функций в условии WHERE
Избегайте больших условий IN()
JOINыПри объединении таблиц попробуйте использовать простое выражение равенства в предложении ON (т.е
a.id = b.person_id). Это позволяет использовать более эффективные методы объединения (т. Е. Hash Join, а не Nested Loop Join)
Преобразуйте подзапросы в операторы JOIN, когда это возможно, поскольку это обычно позволяет оптимизатору понять цель и, возможно, выбрать лучший план.
Правильно используйте СОЕДИНЕНИЯ: используете ли вы GROUP BY или DISTINCT только потому, что получаете дублирующиеся результаты? Это обычно указывает на неправильное использование JOIN и может привести к более высоким затратам
Если план выполнения использует Hash Join, он может быть очень медленным, если оценки размера таблицы неверны. Поэтому убедитесь, что статистика вашей таблицы точна, пересмотрев стратегию очистки (vacuuming strategy )
По возможности избегайте коррелированных подзапросов; они могут значительно увеличить стоимость запроса
Используйте EXISTS при проверке существования строк на основе критерия, поскольку он подобен короткому замыканию (останавливает обработку, когда находит хотя бы одно совпадение)
Общие рекомендацииДелайте больше с меньшими затратами; Процессор быстрее чем операции ввода/вывода (I/O)
Используйте Common Table Expressions и временные таблицы, когда вам нужно выполнить цепочечные запросы.
Избегайте операторов LOOP и предпочитайте операции SET
Избегайте COUNT (*), поскольку PostgresSQL для этого выполняет сканирование таблиц ()
По возможности избегайте ORDER BY, DISTINCT, GROUP BY, UNION, поскольку это приводит к высоким начальным затратам
Ищите большую разницу между оценочными и фактическими строками в выражении EXPLAIN. Если счетчик сильно отличается, статистика таблицы может быть устаревшей, а PostgreSQL оценивает стоимость с использованием неточной статистики. Например: Расчетное количество строк составило 93, а фактическое — 2203. Поэтому, скорее всего, это плохое решение плана. Вы должны пересмотреть свою стратегию очистки (vacuuming strategy) и убедиться, что ANALYZE выполняется достаточно часто.
datagrip
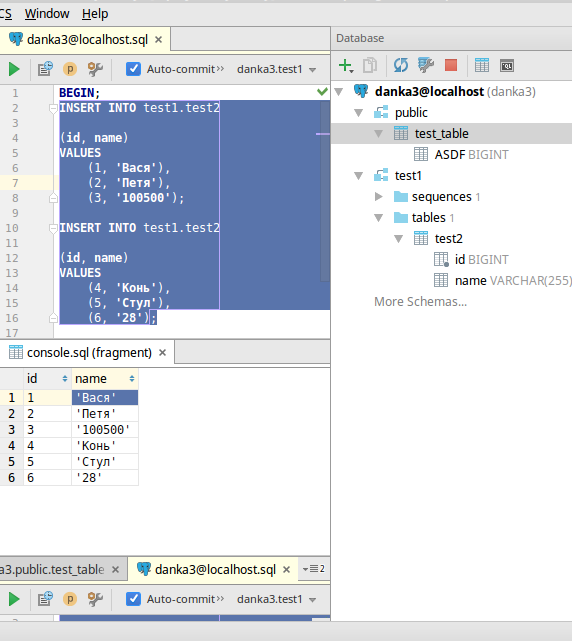 IDE для баз. Несмотря на то, что продукт относительно свежий, он уже используется повсеместно. В основном за счет того, что сразу встроен в мегапопулярные продукты от компании JetBrains: IntelliJ IDEA, PyCharm, PhpStorm и т.д.
IDE для баз. Несмотря на то, что продукт относительно свежий, он уже используется повсеместно. В основном за счет того, что сразу встроен в мегапопулярные продукты от компании JetBrains: IntelliJ IDEA, PyCharm, PhpStorm и т.д.
Собственно, эта его встроенность одновременно является и главной киллер-фичей продукта: вы редактируете, например, php-код, в котором есть строка с sql-запросом, и внезапно понимаете, что IDE вам подсказывает (прямо в вашем коде) синтаксис SQL, названия таблиц и их полей, подчеркивает красненьким, если что-то написано не так, форматирует SQL и многое-многое другое. Конечно, в этом же IDE можно делать и то, что умеют другие GUI для баз: просматривать списки таблиц и других сущностей, отдельно делать запросы, экспорт таблиц в разные форматы и многое другое.
Из особенностей я бы отметил следующие вещи:
- можно выделить несколько insert’ов и нажать «Edit as table» (см. картинку). После чего отредактировать это в удобном табличном виде вместо sql-синтаксиса, причем там же можно добавлять строки, колонки, экспортировать в csv и т.д.
- Можно сравнивать результаты двух запросов. Это полезно, когда пытаешься упростить сложный запрос, и при этом ничего не сломать.
- встроенность в код проработана не до конца. К примеру, при переименовывании в каком-либо интерфейсе колонки таблицы, IDE не находит нужные строки с SQL в коде (при этом автокомплит в этих строках работал), и наоборот, находит какую-то чушь.
- Визуальной разработки не очень много. Т.е. вы можете сделать таблицу, но view уже не можете. Если таблица содержит какие-то id с foreign key (допустим, ссылка на некий словарь), хотелось бы при в вводе данных в таблицу выбирать значения из словаря, а не вбивать айдишки.
- Если посмотреть таблицу в какой-нибудь из схем, то Datagrip посылает запрос set search_path = имясхемы, что приводит к плохим последствиям, если используется pgbouncer (а он используется почти всегда в случае с php или когда много серверов), так что для dev-разработки лучше использовать разные подключения: для работы кода — через pgbouncer, для ide — напрямую к базе.
Datagrip активно развивается, в частности, исправлены некоторые раздражающие баги с подсветкой синтаксиса.
В целом хороший современный инструмент, рекомендую.
Расширения базы данных
К базам данных PostgreSQL можно подключать расширения.
Подключение расширений к базе данных
К каждой базе данных расширения подключаются отдельно.
Чтобы подключить расширение, в панели управления:
- Перейдите в раздел Облачная платформа ⟶ Базы данных.
- Выберите нужный кластер и на его странице откройте вкладку Базы данных.
- В карточке нужной базы данных в блоке Расширения нажмите кнопку Добавить.
- Выберите в списке расширение и сохраните изменения.
Зависимые расширения
Некоторые расширения зависят от других (являются зависимыми) — они не будут работать, если не подключить расширения, от которых они зависят. При подключении к базе данных зависимого расширения автоматически будет подключено то, от которого оно зависит.
Зависимое расширение можно удалить отдельно. Чтобы удалить расширение, от которого зависит другое, нужно сначала удалить зависимое.
Зависимые расширения указаны в списке ниже.
Список расширений
Доступные расширения, в том числе зависимые:
- address_standardizer;
- address_standardizer_data_us;
- ;
- bloom;
- btree_gin;
- btree_gist;
- citext;
- cube;
- dict_int;
- dict_xsyn;
- earthdistance, зависит от расширения cube;
- fuzzystrmatch;
- hstore;
- intarray;
- isn;
- jsquery;
- lo;
- ltree;
- ;
- pg_partman;
- pg_repack;
- pg_stat_kcache, зависит от расширения pg_stat_statements;
- pg_stat_statements;
- pg_trgm;
- pgcrypto;
- pgrouting, зависит от расширения postgis;
- pgrowlocks;
- postgis;
- , зависит от расширения postgis;
- postgis_topology, зависит от расширения postgis;
- postgres_fdw;
- seg;
- tablefunc;
- unaccent;
- uuid-ossp;
- xml2;
- ip4r;
- pgTAP;
- prefix;
- rum.
Утилиты (программы) PosgreSQL:
- createdb и dropdb – создание и удаление базы данных (соответственно)
- createuser и dropuser – создание и пользователя (соответственно)
- pg_ctl – программа предназначенная для решения общих задач управления (запуск, останов, настройка параметров и т.д.)
- postmaster – многопользовательский серверный модуль PostgreSQL (настройка уровней отладки, портов, каталогов данных)
- initdb – создание новых кластеров PostgreSQL
- initlocation – программа для создания каталогов для вторичного хранения баз данных
- vacuumdb – физическое и аналитическое сопровождение БД
- pg_dump – архивация и восстановление данных
- pg_dumpall – резервное копирование всего кластера PostgreSQL
- pg_restore – восстановление БД из архивов (.tar, .tar.gz)
Примеры создания резервных копий:
Создание бекапа базы mydb, в сжатом виде
pg_dump -h localhost -p 5440 -U someuser -F c -b -v -f mydb.backup mydb
Создание бекапа базы mydb, в виде обычного текстового файла, включая команду для создания БД
pg_dump -h localhost -p 5432 -U someuser -C -F p -b -v -f mydb.backup mydb
Создание бекапа базы mydb, в сжатом виде, с таблицами которые содержат в имени payments
pg_dump -h localhost -p 5432 -U someuser -F c -b -v -t *payments* -f payment_tables.backup mydb
Дамп данных только одной, конкретной таблицы. Если нужно создать резервную копию нескольких таблиц, то имена этих таблиц перечисляются с помощью ключа -t для каждой таблицы.
pg_dump -a -t table_name -f file_name database_name
Создание резервной копии с сжатием в gz
pg_dump -h localhost -O -F p -c -U postgres mydb | gzip -c > mydb.gz
Список наиболее часто используемых опций:
- -h host — хост, если не указан то используется localhost или значение из переменной окружения PGHOST.
- -p port — порт, если не указан то используется 5432 или значение из переменной окружения PGPORT.
- -u — пользователь, если не указан то используется текущий пользователь, также значение можно указать в переменной окружения PGUSER.
- -a, —data-only — дамп только данных, по-умолчанию сохраняются данные и схема.
- -b — включать в дамп большие объекты (blog’и).
- -s, —schema-only — дамп только схемы.
- -C, —create — добавляет команду для создания БД.
- -c — добавляет команды для удаления (drop) объектов (таблиц, видов и т.д.).
- -O — не добавлять команды для установки владельца объекта (таблиц, видов и т.д.).
- -F, —format {c|t|p} — выходной формат дампа, custom, tar, или plain text.
- -t, —table=TABLE — указываем определенную таблицу для дампа.
- -v, —verbose — вывод подробной информации.
- -D, —attribute-inserts — дамп используя команду INSERT с списком имен свойств.
Бекап всех баз данных используя команду pg_dumpall.
pg_dumpall > all.sql
Восстановление таблиц из резервных копий (бэкапов):
psql — восстановление бекапов, которые хранятся в обычном текстовом файле (plain text);
pg_restore — восстановление сжатых бекапов (tar);
Восстановление всего бекапа с игнорированием ошибок
psql -h localhost -U someuser -d dbname -f mydb.sql
Восстановление всего бекапа с остановкой на первой ошибке
psql -h localhost -U someuser —set ON_ERROR_STOP=on -f mydb.sql
Для восстановления из tar-арихива нам понадобиться сначала создать базу с помощью CREATE DATABASE mydb; (если при создании бекапа не была указана опция -C) и восстановить
pg_restore —dbname=mydb —jobs=4 —verbose mydb.backup
Восстановление резервной копии БД, сжатой gz
gunzip mydb.gz psql -U postgres -d mydb -f mydb
Установка RedHat Enterprise Linux 8 (RHEL 8.4). Подключение RHEL8 к домену Active Directory. Запуск терминального клиента.
Операционная система – это один из краеугольных камней в фундаменте организации. От нее напрямую зависит надежность и безопасность корпоративной IT-инфраструктуры. Red Hat Enterprise Linux разработана с учетом всех требований и особенностей коммерческой эксплуатации Linux в производственной среде. Она проста в администрировании и управлении при развертывании приложений в физических, виртуальных и облачных средах. Обеспечивает высокую производительность и доступность приложений, а также обладает достаточной гибкостью, чтобы поддерживать рост организации и внедрение новых решений. Red Hat Enterprise Linux ценят за надежность, безопасность, стабильность, высокую производительность и масштабируемость, которые платформа предоставляет организациям. Клиентские решения Red Hat Enterprise Linux переносят эти инновации на рабочий стол.
Запуск скрипта из файла
Сперва проверим, что с переменными окружения всё впорядке.
Для этого введём
в консоль psql.exe нажмём Enter и проверим что bash не жалуется на неизвестную команду.
Если жалуется — прочитайте мои советы в статье
Пишем скрипт
script.sql
Применим этот скрипт к базе данных
HeiHei_ru_DB
У меня postgres запущен локально на порту 5433. У Вас может быть
на 5432 — проверьте.
cat script.sql | psql.exe -h localhost -p5433 -U postgres HeiHei_ru_DB
Password for user postgres:
CREATE TABLE
Саме время сделать что-то более близкое к реальному скрипту
На поля таблицы нужно ввести некоторые ограничения и добавить им свойств.
Теперь запустим этот скрпит уже не в тестовую а в рабочую базу данных
heihei (которая совпадает с названием сайта HeiHei.ru,
но если написать .ru будет синтаксическая ошибка ERROR: syntax error at or near «.»)
cat booking_sites.sql | psql.exe -h localhost -p5433 -U postgres heihei
Password for user postgres:
CREATE TABLE
Инициализация структуры БД
К текущему моменту мы научились запускать в контейнере необходимую нам версию PostgreSQL, переопределять суперпользователя и создавать базу данных с нужным именем.
Это хорошо, но чистая база данных вряд ли будет сильно полезна. Для работы/тестов/экспериментов нужно наполнить эту базу таблицами и другими объектами. Разумеется, всё это можно сделать вручную, но, согласитесь, гораздо удобнее, когда сразу после запуска вы автоматически получаете полностью готовую БД.
Разработчики официального образа PostgreSQL естественно предусмотрели этот момент и предоставили нам специальную точку входа для инициализации базы данных — docker-entrypoint-initdb.d. Любые *.sql или *.sh файлы в этом каталоге будут рассматриваться как скрипты для инициализации БД. Здесь есть несколько нюансов:
-
если БД уже была проинициализирована ранее, то никакие изменения к ней применяться не будут;
-
если в каталоге присутствует несколько файлов, то они будут отсортированы по имени с использованием текущей локали (по умолчанию en_US.utf8).
Инициализацию БД можно запустить через однострочник, но в этом случае требуется указывать абсолютный путь до каталога со скриптами:
Например, на моей машине это выглядит так:
В качестве обходного варианта можно использовать макрос, на лету определяя рабочую директорию, и запускать команду из каталога со скриптами:
Использование docker-compose файла в этом случае более удобно и позволяет указывать относительные пути:
Здесь хотелось бы акцентировать ваше внимание на одной простой вещи, о которой уже говорил в предыдущей статье: при создании миграций БД для ваших приложений отдавайте предпочтение чистому (plain) SQL. В этом случае их можно будет переиспользовать с минимальными затратами
Наивно используем полнотекстовый поиск
Как гласит документация, для полнотекстового поиска требуется использовать типы и . Первый хранит текст документа в оптимизированном для поиска виде, второй — хранит полнотекстовый запрос.
Для поиска в PostgreSQL есть функции , , . Для ранжирования результатов есть . Их использование интуитивно понятно и они хорошо описаны в документации, поэтому на подробностях их использования останавливаться не будем.
Традиционный поисковый запрос с помощью них будет выглядеть так:
Мы вывели id-ы документов, в тексте которых есть слово «запрос», и отсортировали их по убыванию релевантности. Кажется, всё хорошо? Нет.
У подхода выше есть много недостатков:
- Мы не используем индекс для поиска.
- Функция ts_vector вызывается для каждой строки таблицы.
- Функция ts_rank вызывается для каждой строки таблицы.
Это все приводит к тому, что поиск выполняется реально долго. Результаты на боевой базе:
420 секунд! На один запрос!
Ещё база генерит множество ворнингов вида . В этом ничего страшного нет. Причина в том, что в моей базе лежат документы, созданные в WYSIWYG-редакторе. Он вставляет множество всюду, где можно, и их бывает по 54 тысячи штук подряд. Postgres слова такой длины игнорирует и пишет ворнинг, который нельзя отключить.
Попробуем исправить все замеченные проблемы и ускорить поиск.
Установка платформы 1С 8.3.20.1363 и более старших версий на RHEL8 и любые другие rpm-based linux. Решение проблемы установки меньших версий 1С8.3 (webkitgtk3) на RHEL 8 / CentOS 8 / Fedora Linux
Начиная с версии платформы 1С 8.3.20.1363 реализована программа установки компонентов системы «1С:Предприятие» для ОС Linux. Теперь любой пользователь Линукс может без проблем установить 1С на свою любимую систему. Попытка установки 1С:Предприятия 8.3 меньших версий, чем 1С 8.3.20.1363 на RedHat Enterprise Linux 8 / CentOS 8 / Fedora не увенчается успехом, произойдет ошибка: Неудовлетворенные зависимости: libwebkitgtk-3.0.so.0()(64bit) нужен для 1c-enterprise-8.3.18.1128-training-8.3.18-1128.x86_64. Конфликт заключается в том, что 1С требует устаревшую версию пакета libwebkitgtk-3.0.so.0()(64bit), запрещенную из-за проблем безопасности, и не может работать с актуальной версией пакета webkit2gtk3. Гуглить в интернете можно долго, хочу поделиться с Вами уже найденным рабочим решением в конце данной статьи.
Создаем собственные типы
Собственные типы можно создавать тремя способами. Во-первых, если вы знаете язык Си, то вы можете создать базовый тип, наравне с каким-нибудь int или varchar. Пример из мануала:
Т.е. создаете пару функций, которые умеют делать из cstring ваш тип и наоборот. После чего можно использовать этот тип, например, в объявлении таблицы:
Второй способ — это композитный тип. Например, для хранения комплексных чисел:
И потом использовать это:
Третий вид типа, который вы можете создать — это доменный тип. Доменный тип — это просто алиас к существующему типу с другим именем, т.е. именем, соответствующим вашей бизнес-логике.
us_postal_code — это более семантично, чем некий абстрактный text или varchar.




