30+ парсеров для сбора данных с любого сайта
Содержание:
- Обработка результатов#
- Какими бывают подсказки
- Представление результатов#
- Как получить список поисковых подсказок
- Бесплатные парсеры
- Поищите XHR запросы в консоли разработчика
- Парсеры поисковых систем#
- Парсите HTML теги
- Реклама в поисковых подсказках Яндекс: преимущества
- Как правильно использовать long tail запросы в статье
- Виды парсеров по сферам применения
- Как осуществить наиболее эффективный сбор?
- Как собрать long tail запросы, 8 простых шагов
- Как происходит формирование поисковых подсказок (ПП) в Яндексе и Гугле
- P. S. Помните о сезонности
- Парсеры параметров сайтов и доменов#
Обработка результатов#
A-Parser позволяет обрабатывать результаты непосредственно во время парсинга, в этом разделе мы привели наиболее популярные кейсы для парсера SE::Yandex::Suggest
Опция Парсить до уровня (Parse to level)
Опция указывает парсеру переходить по соседним страницам сайта в глубину до указанного уровня, например:
- Если указан 1-ый уровень то парсер перейдёт по всем ссылкам указанным на исходной странице
- Если указан 2-ой уровень то парсер перейдёт по всем ссылкам указанным на исходной странице + по всем ссылкам собранным со страниц на первом уровне
- и т.д.
Простыми словами — это минимальное число кликов между исходной страницей и конечной
Т.к. на соседних страницах скорее всего будут ссылки на исходную страницу или повторы ссылок, то для того чтобы парсер не зациклился, и не ходил по кругу, необходимо обязательно включать уникальность запросов (Unique queries)

Скачать пример
eJx1VFtv2jAU/iuRhdRVYohSeFjeKBrSJlZYaR8m4MGrD5FXx85sh1FF+e89xwlJ
WOmL5XP7zncudsE8dy9uZcGBdyzeFCwLdxaz9dc4/sW1gGMcr/MkAeejz9GKWweR
N5GCA6gIjjzNFLA+y8hgCWNzKRQ9BOx5rvBWMP+aAaYwB7BWCgqXAuW9sSn3SCC4
sQNXObn1Ko0bVPZPVz1XgW63+uqalR3AzEuj3QkvcFoQ0RbtZlh+TEDZTtrRaMLK
3a7P6vTzkJ34ZDeDuk2Ncc0P8GioBhnacYpB6Z6noQrBPZD1VMb1wB8JgQshiTZX
VQbqYZv1Scu/gY7zVuoE/VG0EtzcmhTVHgIIKV9PDDesF2SGMHmI/1nFsNjbHPrM
Ids5Ry6iMey5cmiRHiz3xi7rTsYFM3qqVOhi6xbg73KpBM58usegb3XgZZflO4yy
qbCbCufxzyKHBiVId8sfbZQwC5Ng4dpg2Uqm0qPsZibXNJshKl8AsqZt9+SWGgtN
mhq5zo67n4Gm4bdTm2at6qyMs8mcK5+N3stkWS/UyTPXj/jAlnpm6JlQXTpXCqfi
4KHdkKmrx0BCS/D/4FlIgbSal8S8Mcp9X1dUMytxAydEMMVOdrPWkM9cqaeHRdfC
2o1CYZsPx+MhnbeTcB937pU+nONRFAQIpwjn79Z8+6XSM0rpITG4i9iQctf8E82X
U1z8LeKixFH/cavKm/pCvqjDBjucIz7k8g0dHqJw
Скопировать
Фильтрация результатов (использование минус-слов)
Использовав минус-слова возможно стразу убирать реультаты которые вам не нужны.
Аналогично используя фильтр можно и оставлять только те результаты которые содержат нужные слова.

Скачать пример
eJx1VFtv0zAU/iuVNWlMGlWvEuStq6gEKutYuwfU9sFrToKZYwfbKZ1C/jvHl1zK
yot1rt+5uySG6hf9oECD0STaliR3NInI+lMUfacihlMUrYs0BW1673sLxg2oHpxo
lnMgtySnSoOyvttLLmgRQ0ILjlRJzGsOCC2PoBSLrTuLkU+kyqjBwM6MHCkvrNmV
l+i+17+7vtIedLcT1zek6gDmhkmhazyX0xKOwFu04aD6fwJcdcKORtMuduIqRn3I
L9oGyoYLCZH9bbDbeCcFQhrM+fCjA7wrBpPJxL7jD+59dpKDow9/HDN0zNTRg46p
p5+d0XjUUUxah7Gtx7cCo5Fqv6+T1gvXQdvTfNgPI26Ua3qEjfSlQivGUcM9zdwk
YmrAautR3PTNySLQOGY2HuU+gt2DNuqTYL9c5dooJlK0R1Yx0AslMxQbcCBW+Fpn
uCVXjrctLZz/N+9DIqMKwJZjtguKucSNIqFco4Zh/6mRahW2ISqJFDPO3Sa0Zg7+
rmA8xr2dJej0OTheNlm9waiaCruhcKd+K8yhQXHc3epr6xXLpUyxcCGxbM4yZpDX
c1kIO5sBCl8A8qZt99YskwqaMAE5RMe7zUHYBW6nNstb0VkZZ5M5Fx6kSFi6CkdR
WxZig5/DSsylPXVblyg4x6loeGw3ZKbDGCzTJviv89yFwLSa34AYKbn+svap5orh
Bk5tghl2shs1QB4o50+Py66GtBtVn9egcz+TN7fk3smo56/FvXF7ieHIPno5sSEN
pBJ3ERtS7Zu/rvkuy4s/XlRWOOqf+sFb275YW5Rhg7U7zmH1F8zL3Bw=
Скопировать
Какими бывают подсказки
Можно выделить несколько типов поисковых подсказок.
Полнотекстовые – отображаются у пользователей ПК, быстро набирающих запрос с клавиатуры. Им удобнее вбить в поисковую строку запрос частично, а остальную часть выбрать из предложенного списка.
Пословные доступны в мобильных приложениях и Яндекс.Браузере. Задав первое слово, пользователь вводит всю фразу с помощью кликов на предлагаемые варианты.
Подсказки-фактоиды доступны пользователям мобильного поиска – ответ на введенный запрос отображается сразу под поисковой строкой. Таким образом пользователь может получить информацию о погоде, пробках и иных фактах.
По схожему принципу работают подсказки и в Яндекс.Видео – они содержат в себе номера сезонов и серии, являющиеся прямыми ссылками на соответствующее видео.
Длинные поисковые подсказки появились благодаря возросшему числу пользователей, вводящих запросы длиной от пяти слов. В некоторых тематиках доля таких пользователей составляет 50% и более. Такие поисковые подсказки имеют место в поиске, картинках и видео.
Исторические – доступны авторизованным пользователям десктопа и мобильных устройств. Также такие подсказки появляются в поисковых сервисах Яндекса. Формируются на основе истории запросов и выделяются приоритетно в поиске.
Представление результатов#
A-Parser создавался для парсинга информации любых видов, для этого было введено 2 типа результатов:
- Простые результаты(Flat)
- Массивы результатов(Array)
Рассмотрим каждый тип на примере парсера SE::Google, скриншот выдачи:

Простые результаты
Простые результаты — когда одному запросу соответствует один результат, примеры:
- Количество результатов по запросу ($totalcount)
- Является ли запрос опечаткой($misspell, на скриншоте не представлен)
Другие примеры:
- Значение Alexa Rank($rank) в парсере Rank::Alexa
- Значение переведённого текста($translated) в парсере DeepL::Translator
- Количество ссылающихся доменов($domains), значение траста($trustflow), беклинков($backlinks) и т.д. в парсере Rank::MajesticSEO
Одиночные результаты сохраняются в обычных переменных(префикс + название на латинице)
Массивы результатов
Массивы результатов — когда одному запросу соответствует список результатов, каждый элемент списка в свою очередь может содержать несколько вложенных элементов. Разберем на примере выдачи Google — она представлена в парсере массивом $serp, для наглядности воспользуемся таблицей, запишем первые 5 результатов выдачи:
| Ссылка($link) | Анкор($anchor) | Сниппет($snippet) |
|---|---|---|
| http://www.speedtest.net/ | Speedtest.net by Ookla — The Global Broadband Speed Test | Test your Internet connection bandwidth to locations around the world with this interactive broadband speed test from Ookla. |
| http://en.wikipedia.org/wiki/Test_cricket | Test cricket — Wikipedia, the free encyclopedia | Test cricket is the longest form of the sport of cricket. Test matches are played between national representative teams with «Test status», as determined by the … |
| http://www.speakeasy.net/speedtest/ | Speakeasy Speed Test | Saturday 03-May 2014, 11:04:29 AM Your IP: The Speakeasy Speed Test requires Flash v7 or higher. Please update your browser. See Pricing Or Call Today |
| http://www.humanmetrics.com/cgi-win/jtypes2.asp | Personality test based on C. Jung and I. Briggs Myers type theory | Humanmetrics Jung Typology Test instrument uses methodology, questionnaire, scoring and software that are proprietary to Humanmetrics, and shall not be … |
| http://test-ipv6.com/ | Test your IPv6. | This will test your browser and connection for IPv6 readiness, as well as show you your current IPV4 and IPv6 address. … Test your IPv6 connectivity. JavaScript … |
Каждая позиция выдачи записывается в массив с 3мя вложенными элементами — ссылка($link), анкор($anchor), сниппет($snippet)
Другой пример — список связанных ключевых слов, который сохраняется в массиве $related:
| Кейворд($key) |
|---|
| test wwe |
| depression test |
| test my speed |
| wonderlic test |
| test personality |
| act test |
| jiggle test |
| bipolar test |
Как видно в данном массиве всего один вложенный элемент — кейворд($key)
Нумерация элементов массивов начинается с 0, пример доступа к отдельным элементам массива:
- $serp.0.link — первая ссылка из выдачи
- $serp.3.anchor — четвертый анкор из выдачи
- $related.0.key — первый связанный кейворд
Более подробно про форматирование простых результатов и массивов будет описано ниже
Как получить список поисковых подсказок
Можно получить несколькими способами:
- Используя блок дополнительного поиска в системе Google «Вместе с … часто ищут». Для этого вводится запрос, и можно посмотреть, что ищут вместе с ним.
Такой вид не совсем удобен, поскольку, во-первых, показывает всего около десятка подсказок, что очень мало для создания семантического ядра сайта. Во-вторых, каждую фразу приходится набивать отдельно, что занимает много времени. Выгрузить результаты по нескольким запросам сразу нельзя.
2. Посредством инструментов для парсера подсказок поисковых систем:
Ubersuggest — позволяет увидеть информацию из поиска по новостям, изображениям и видео поисковой системы. Нужно ввести ключевое слово в строку поиска и задать язык.
Этот сервис подскажет, какие слова пользователи ищут вместе с заданными «ключевиками». Дополнительные слова при этом разделяются от заданного основного знаком «+». Сортировка по алфавиту делает работу с данными удобной для SEO-оптимизатора.
- Keyword Tool является бесплатным сервисом. Он основан на подсказках Google для разных регионов и языков данной поисковой системы. Также сервис позволяет увидеть семантику из Bing, AppStore и YouTube. Стандартно вводится слово в строку поиска, производится отбор по базе данных и языку.
- Словодер — программа, позволяющая работать сразу с несколькими поисковыми системами, поскольку работает через прокси-сервер. Для начала работы необходимо скачать программу, после ее запуска ввести слово для поиска и выбрать нужный поисковик — поисковые подсказки Яндекс , Google, Mail, Rambler, Yahoo, Nigma. Затем нужно нажать на кнопку «Парсить» и подождать вывода результатов.
- avtodreem, чаще всего можно встретить в поисковой выдаче по запросу «как попасть в подсказки».
Бесплатные парсеры
В Сети можно найти бесплатные версии парсеров, которые по заверениям разработчиков ничем не уступают вышеописанным программам и сервисам. Однако в большинстве случаев это «сырой» продукт с рядом недостатков – отсутствие обновлений, неудобный интерфейс, ограниченные функции. Низкая точность выборки, часто возникают ошибки. Причина – Яндекс.Вордстат постоянно изменяется, за этим нужно следить и вносить корректировки в ПО.
Если бесплатное использование является обязательным условием, можно скачать актуальные версии «Словоёб» или «Магадан». Альтернатива – воспользоваться возможностями «Букварикса» после регистрации.
Выбор парсеров зависит от поставленной задачи – объема ключевых фраз, точности выборки и дальнейшей обработки результатов. Для больших проектов рекомендуются платные версии, для ознакомления с возможностями и для составления СЯ для 1-3 сайтов – бесплатные.
Поищите XHR запросы в консоли разработчика
 Кабина моего самолета
Кабина моего самолета
Все современные вебсайты (но не в дарк вебе, лол) используют Javascript, чтобы догружать данные с бекенда. Это позволяет сайтам открываться плавно и скачивать контент постепенно после получения структуры страницы (HTML, скелетон страницы).

Обычно, эти данные запрашиваются джаваскриптом через простые GET/POST запросы. А значит, можно подсмотреть эти запросы, их параметры и заголовки — а потом повторить их у себя в коде! Это делается через консоль разработчика вашего браузера (developer tools).В итоге, даже не имея официального API, можно воспользоваться красивым и удобным закрытым API. ️Даже если фронт поменяется полностью, этот API с большой вероятностью будет работать. Да, добавятся новые поля, да, возможно, некоторые данные уберут из выдачи. Но структура ответа останется, а значит, ваш парсер почти не изменится.
Алгорим действий такой:
-
Открывайте вебстраницу, которую хотите спарсить
-
Правой кнопкой -> Inspect (или открыть dev tools как на скрине выше)
-
Открывайте вкладку Network и кликайте на фильтр XHR запросов
-
Обновляйте страницу, чтобы в логах стали появляться запросы
-
Найдите запрос, который запрашивает данные, которые вам нужны
-
Копируйте запрос как cURL и переносите его в свой язык программирования для дальнейшей автоматизации.
 Кнопка, которую я искал месяцы
Кнопка, которую я искал месяцы
Вы заметите, что иногда эти XHR запросы включают в себя огромные строки — токены, куки, сессии, которые генерируются фронтендом или бекендом. Не тратьте время на ревёрс фронта, чтобы научить свой парсер генерировать их тоже.
Вместо этого попробуйте просто скопипастить и захардкодить их в своем парсере: очень часто эти строчки валидны 7-30 дней, что может быть окей для ваших задач, а иногда и вообще несколько лет. Или поищите другие XHR запросы, в ответе которых бекенд присылает эти строчки на фронт (обычно это происходит в момент логина на сайт). Если не получилось и без куки/сессий никак, — советую переходить на автоматизацию браузера (Selenium, Puppeteer, Splash — Headless browsers) — об этом ниже.
Парсеры поисковых систем#
| Название парсера | Описание |
|---|---|
| SE::Google | Парсинг всех данных с поисковой выдачи Google: ссылки, анкоры, сниппеты, Related keywords, парсинг рекламных блоков. Многопоточность, обход ReCaptcha |
| SE::Yandex | Парсинг всех данных с поисковой выдачи Yandex: ссылки, анкоры, сниппеты, Related keywords, парсинг рекламных блоков. Максимальная глубина парсинга |
| SE::AOL | Парсинг всех данных с поисковой выдачи AOL: ссылки, анкоры, сниппеты |
| SE::Bing | Парсинг всех данных с поисковой выдачи Bing: ссылки, анкоры, сниппеты, Related keywords, Максимальная глубина парсинга |
| SE::Baidu | Парсинг всех данных с поисковой выдачи Baidu: ссылки, анкоры, сниппеты, Related keywords |
| SE::Baidu | Парсинг всех данных с поисковой выдачи Baidu: ссылки, анкоры, сниппеты, Related keywords |
| SE::Dogpile | Парсинг всех данных с поисковой выдачи Dogpile: ссылки, анкоры, сниппеты, Related keywords |
| SE::DuckDuckGo | Парсинг всех данных с поисковой выдачи DuckDuckGo: ссылки, анкоры, сниппеты |
| SE::MailRu | Парсинг всех данных с поисковой выдачи MailRu: ссылки, анкоры, сниппеты |
| SE::Seznam | Парсер чешской поисковой системы seznam.cz: ссылки, анкоры, сниппеты, Related keywords |
| SE::Yahoo | Парсинг всех данных с поисковой выдачи Yahoo: ссылки, анкоры, сниппеты, Related keywords, Максимальная глубина парсинга |
| SE::Youtube | Парсинг данных с поисковой выдачи Youtube: ссылки, название, описание, имя пользователя, ссылка на превью картинки, кол-во просмотров, длина видеоролика |
| SE::Ask | Парсер американской поисковой выдачи Google через Ask.com: ссылки, анкоры, сниппеты, Related keywords |
| SE::Rambler | Парсинг всех данных с поисковой выдачи Rambler: ссылки, анкоры, сниппеты |
| SE::Startpage | Парсинг всех данных с поисковой выдачи Startpage: ссылки, анкоры, сниппеты |
Парсите HTML теги
Если случилось чудо и у сайта нет ни официального API, ни вкусных XHR запросов, ни жирного JSON внизу HTML, если рендеринг браузерами вам тоже не помог, то остается последний, самый нудный и неблагодарный метод. Да, это взять и начать парсить HTML разметку страницы. То есть, например, из достать ссылку. Это можно делать как простыми регулярными выражениями, так и через более умные инструменты (в питоне это BeautifulSoup4 и Scrapy) и фильтры (XPath, CSS-selectors).
Мой единственный совет: постараться минимизировать число фильтров и условий, чтобы меньше переобучаться на текущей структуре HTML страницы, которая может измениться в следующем A/B тесте.

Даниил Охлопков — Data Lead @ Runa Capital
Подписывайтесь на мой Телеграм канал, где я рассказываю свои истории из парсинга и сливаю датасеты.
Надеюсь, что-то из этого было полезно! Я считаю, что в парсинге важно, с чего ты начинаешь. С чего начать — я рассказал, а дальше ваш ход
Реклама в поисковых подсказках Яндекс: преимущества
Общий принцип выдачи подсказок Яндекса мы уже упоминали. Чем чаще такой запрос выполняется, тем выше вероятность его попадания в подсказки. Естественно, при этом учитывается максимальная релевантность подсказки и поисковой темы. Если вы ищете «Как отремонтировать окна», вам вряд ли подскажут о том, какие стальные двери самые лучшие.
Но зато если уж подскажут про окна… Реклама в подсказках Яндекса прекрасно работает по одной простой причине: она существенно упрощает поиск. Пользователи набирают меньше слов, не думают о возможных ошибках при наборе и даже могут забыть переключить раскладку — Яндекс всё автоматически исправит. К тому же, удобно и то, что можно быстро попасть на нужный пользователю сайт. Если человек часто набирает какой-то адрес, этот URL скоро окажется в подсказках.
Помимо показов в подсказке, релевантное объявление может попасть и в результаты поиска. Причём показ подсказки никак не влияет на CTR при расчёте первого места в выдаче. Увеличение охвата не влияет на коэффициент качества, если число кликов сохраняется.
Так что брендированный запрос в подсказках, который связан с конкретной компанией, отлично работает. Довольно часто в Рунете можно встретить восторженные отзывы от новичков, которые не смогли пробиться в топ, но, по их словам, обеспечили себе место в подсказках. Как вам такое, например: «Подсказки Яндекса дали нашей компании два миллиона показов и обеспечили 60% от всех заказов! Вот уже полгода мы просто получаем заказы и больше не вкладываемся ни в какую рекламу».
Сплошные же плюсы и вообще звучит как призыв к действию! Так ли это в реальности? Приступаем к конкретике — что нужно сделать, чтобы попасть в подсказки Яндекса, и что вам это даст.
Как правильно использовать long tail запросы в статье
Точно сказать нельзя, но можно дать рекомендации:
- Используйте запросы в точном вхождении.
- Старайтесь использовать запросы в подзаголовках.
- Сразу же после запроса давайте ответ в пределах 370 знаков без пробелов.
Ваша задача – в первую очередь вывести выбранные вами запросы в блоки быстрых ответов. Google может поднять до нулевой позиции и запрос, на который вы не ориентировались специально, но случайно дали на него ответ. Например, так выглядит блок быстрого ответа в поиске:
А вот так этот же блок на сайте:
Это один из примеров такого случайного попадания в блок быстрых ответов в Google. Тем не менее, это отличный пример того, что у пользователя был четкий вопрос, а поисковая система выдала на него точный ответ.
Знаю случаи, когда такой подход использовали для доработки существующих материалов на сайте, после чего они попадали в блок быстрых ответов. Просто делаете все, кроме последнего, восьмого шага и оптимизируете существующие статьи, добавляя в них блоки с вопросами-ответами.
Виды парсеров по сферам применения
Для организаторов СП (совместных покупок)
Есть специализированные парсеры для организаторов совместных покупок (СП). Их устанавливают на свои сайты производители товаров (например, одежды). И любой желающий может прямо на сайте воспользоваться парсером и выгрузить весь ассортимент.
Чем удобны эти парсеры:
- интуитивно понятный интерфейс;
- возможность выгружать отдельные товары, разделы или весь каталог;
- можно выгружать данные в удобном формате. Например, в Облачном парсере доступно большое количество форматов выгрузки, кроме стандартных XLSX и CSV: адаптированный прайс для Tiu.ru, выгрузка для Яндекс.Маркета и т. д.
Популярные парсеры для СП:
- SPparser.ru,
- Облачный парсер,
- Турбо.Парсер,
- PARSER.PLUS,
- Q-Parser.
Вот три таких инструмента:
- Marketparser,
- Xmldatafeed,
- ALL RIVAL.
Парсеры для быстрого наполнения сайтов
Такие сервисы собирают названия товаров, описания, цены, изображения и другие данные с сайтов-доноров. Затем выгружают их в файл или сразу загружают на ваш сайт. Это существенно ускоряет работу по наполнению сайта и экономят массу времени, которое вы потратили бы на ручное наполнение.
В подобных парсерах можно автоматически добавлять свою наценку (например, если вы парсите данные с сайта поставщика с оптовыми ценами). Также можно настраивать автоматический сбор или обновление данных по расписания.
Примеры таких парсеров:
- Catalogloader,
- Xmldatafeed,
- Диггернаут.
Как осуществить наиболее эффективный сбор?
Пользоваться инструментом несложно благодаря интуитивно понятному интерфейсу.
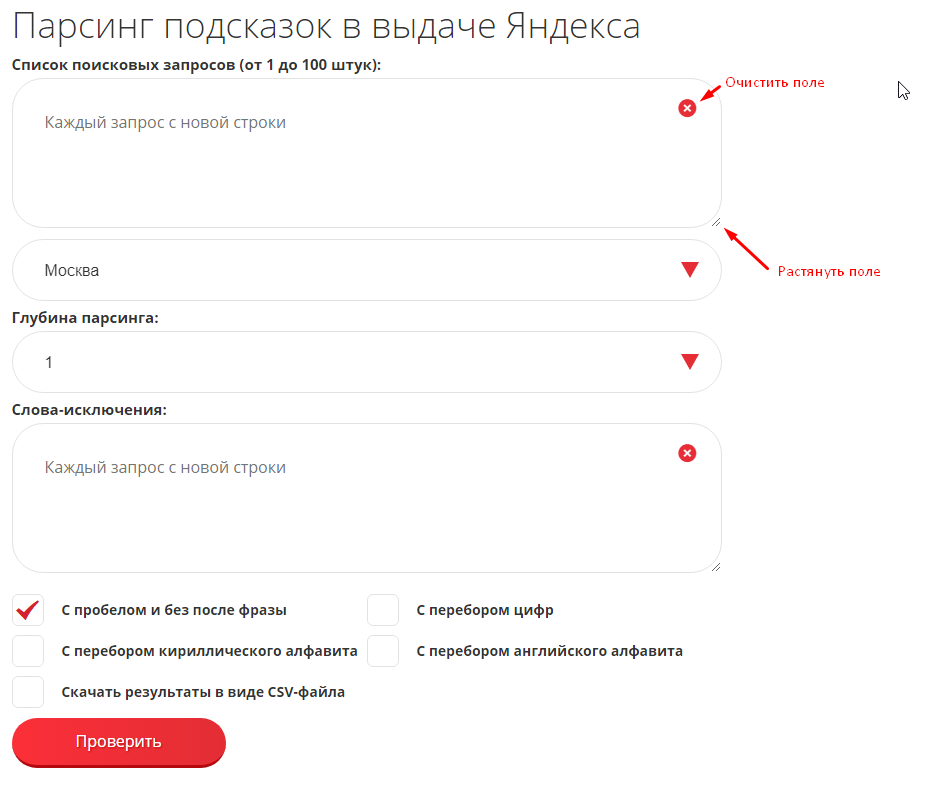
В первую форму вводятся поисковые фразы, для которых необходимо спарсить подсказки. В случае ошибки, можно нажать на крестик в правом верхнем углу и очистить форму. Кроме того, если фраз достаточно много, для удобства можно увеличить поле, потянув значок в правом нижнем углу.
После ввода фраз, из выпадающего меню требуется задать необходимый регион продвижения.
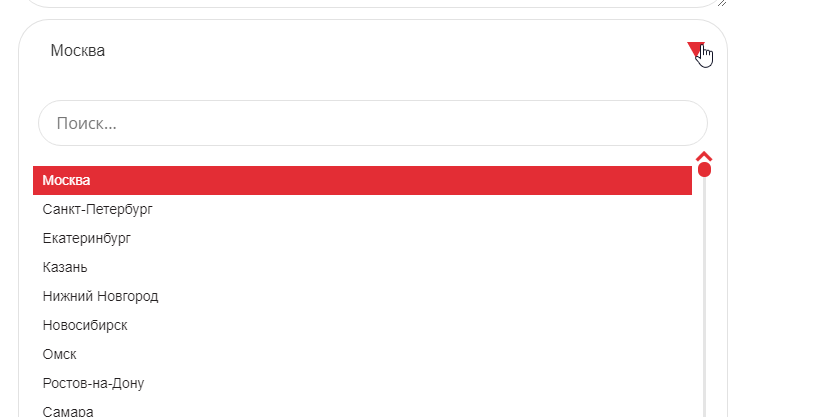
Дальнейшие настройки — зависят от решаемых задач.
Параметр «Глубина парсинга» отвечает за итерационный сбор.
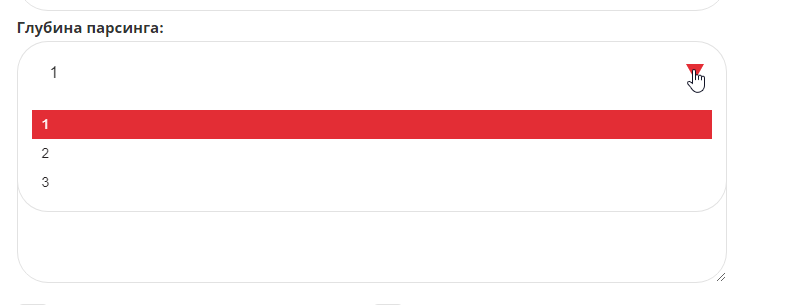
Если указана цифра 1, сбор подсказок будет осуществляться только для фраз, введенных в поле «Список поисковых запросов». Если же нужна более широкая семантика, то имеет смысл сначала собрать подсказки к имеющимся ключевым фразам, а затем — подсказки к уже полученным. Этот последовательный сбор можно выполнить за одну операцию, просто выставив глубину парсинга, равную двум.
Например, если требуется сначала спарсить поисковые подсказки по слову , а затем дополнить их теми подсказками, которые были собраны, например, к , то сервис «Пиксель Тулс» окажется крайне полезен для этой задачи.
Кроме того, инструмент позволяет воспользоваться словами-исключениями для того, чтобы не собирать подсказки, содержащие ненужные слова, например, или .
Как собрать long tail запросы, 8 простых шагов
Первый шаг, который нам нужно сделать это выбрать направление. По каким запросам мы хотим продвигаться? Про что хотим писать статьи?
Например, контент:
Второй шаг – уточняем, о каком именно контенте мы хотим писать:
Теперь мы берем список вопросительных маркеров:
- где;
- если;
- зачем;
- как;
- какой;
- когда;
- который;
- кто;
- куда;
- можно;
- можно ли;
- нужно;
- нужно ли;
- откуда;
- почему;
- сколько;
- чей;
- что.
И на третьем шаге мы подставляем вопросительный маркер перед началом нашей ключевой фразы:
В итоге получаем список вопросительных long tail запросов. Четвертый шаг – занести эти запросы в Excel:
Шаг пять – повторять шаги 3 и 4, пока не кончатся вопросительные маркеры. В некоторых случаях подсказки не всплывают – это нормально. Значит, что вопросительный маркер в данном контексте не популярен. Просто идите дальше по списку.
Итак, пройдя все вопросительные маркеры, мы собрали 27 long tail запросов. Шестой шаг – фильтрация. Мы выделяем и удаляем те запросы, которые не соответствуют нашей тематике, либо мы не хотим с ними работать:
Некоторые из запросов можно объединить, например – запросы на строке 2 и 3. Запрос на третьей строке уже включает в себя прямое вхождение запроса из строки два, соответственно его тоже удаляем.
Седьмой шаг – дополнить наш список запросов, немного изменив основной запрос. У нас был – контент сайта. Можно пройтись по запросам – контент для сайта, статьи для сайта.
Повторяйте предыдущие 7 шагов, пока не соберете достаточное количество запросов. Как узнать, когда пора остановиться? Когда у вас полностью кончатся идеи. Либо, когда соберете 200–300 запросов. Этого хватит на несколько десятков статей.
Восьмой шаг – разбить собранные запросы на группы. Первая группа – наш самый главный лонгрид. Он должен содержать в себе как можно больше запросов, быть самым информативным и полезным. Все остальные группы – статьи поменьше, с них мы будем ссылаться на лонгрид для увеличения веса страницы:
На выходе мы получили 5 групп запросов. Группа 1 – наш лонгрид, в котором мы пишем все о контенте для сайта: что это такое, что в него входит, где его брать, как создавать, кто может сделать это за вас, как еще его можно достать, где его хранить и как вообще продвигать сайт за счет контента.
Все остальные группы – небольшие статьи, которые раскрывают дополнительные вопросы. С каждой из этих статей мы должны сделать ссылку на наш лонгрид.
Некоторые запросы могут показаться одинаковыми по смыслу, например:
- как защитить контент сайта от копирования;
- как защитить контент сайта от воровства.
Разница всего в одном слове. И именно за это слово нужно цепляться. Как это можно обыграть? В защите от копирования написать, как можно защитить текст от его выделения мышкой для последующего копирования. А в защите от воровства можно указать правила перепечатки материалов:
Таким образом, мы собрали большой пул низкочастотных запросов, а за одним подготовили контент-план на месяцы вперед. Причем, вам может показаться, что ответы на некоторые вопросы – очевидные. Будь это так, их бы не искали сотни раз в день. Значит, контент, который вы планируете готовить – уже потенциально интересен определенной аудитории.
Как происходит формирование поисковых подсказок (ПП) в Яндексе и Гугле
Формирование подобных фраз происходит путем работы сложных алгоритмов при влиянии многих факторов. К ним относятся:
- Частота фраз в поиске. ПС предлагают пользователю наиболее популярные хвосты к введенному запросу.
- Регионы для коммерческого запроса. Если посетитель ищет окна в Воронеже, ПС, как правило, не дает ему хвост из других регионов.
- Ориентация на пользователя. ПС ориентируются на часто запрашиваемые этим пользователем слова, на историю его поиска и другую персональную информацию.
- Обновление. Относится к новостным вопросам, поэтому окно с подсказками обновляется постоянно.
- Фильтр. Удаляются нецензурные слова, запросы с ошибками и опечатками, низкопопулярные фразы.
P. S. Помните о сезонности
Вордстат – и, следовательно, парсер тоже – показывает статистику за последние 30 дней. Если запрос сезонный, можно сделать неправильные выводы, если смотреть только один месяц. Сезонные ключи нужно дополнительно проверять на wordstat.yandex.ru в разделе «История запросов»:
Зарегистрируйтесь в Click.ru сейчас и получите доступ к парсеру Wordstat, а также бесплатным инструментам по созданию и управлению контекстной рекламой – умному подборщику слов, генератору объявлений, медиапланеру, автобиддеру. По промокоду key вы в течение месяца сможете апробировать все возможности сервиса и получать максимальное вознаграждение 8 % вне зависимости от суммы расходов на контекстную рекламу.
Парсеры параметров сайтов и доменов#
| Название парсера | Описание |
|---|---|
| SE::Google::TrustCheck | Проверка сайта на trust |
| SE::Google::Compromised | Проверка наличия надписи This site may be hacked |
| SE::Google::SafeBrowsing | Проверка домена в блеклисте Google |
| SE::Yandex::SafeBrowsing | Проверка домена в блеклисте Yandex |
| SE::Bing::LangDetect | Определение языка сайта через поисковик Bing |
| SE::Yandex::SQI | Проверка Индекса качества сайта в Яндексе |
| Net::Whois | Определяет зарегистрирован домен или нет, дату создания домена, а так же дату окончания регистрации |
| Net::Dns | парсер резолвит домены в IP адреса |
| Rank::Cms | Определяет все популярные форумы, блоги, CMS, гестбуки, вики и множество других типов движков |
| Rank::Alexa | Определяет позици. в глобальном рейтинге Alexa |
| Rank::Alexa::Api | Быстрый чекер алексы через API |
| Rank::Archive | Парсер даты первого и последнего кэширования сайта в веб архиве |
| Rank::Linkpad | Парсер беклинков и статистики с сервиса linkpad.ru |
| Rank::MajesticSEO | Парсер количества бек-линков с сервиса majesticseo.com |
| Rank::Mustat | Оценка трафика на сайте, также стоимость и рейтинг домена |
| Rank::Social::Signal | парсер социальных сигналов |
| Rank::Curlie | проверка наличия сайта в каталоге Curlie (аналог DMOZ) |
| Rank::Ahrefs | Парсер ahrefs.com |
| Rank::KeysSo | Парсер keys.so |
| Rank::MOZ | Парсер MOZ |
| SecurityTrails::Ip | Собирает домены по IP |
| SecurityTrails::Domain | Парсер SecurityTrails |




