Пузырьковая сортировка (сортировка “пузырьком”)
Содержание:
- Варианты алгоритма
- Алгоритм
- Использовать
- Идея алгоритма
- Встроенный язык 1С 8.*
- Принцип работы
- Быстрая сортировка (Quick sort)
- Сложность алгоритма
- Пузырьковая сортировка Python 3
- Динамическое выделение памяти[править]
- Анализ
- Пузырьковая сортировка и её улучшения
- Оптимизация реализации кода Python
- Простые сортировки
Варианты алгоритма
Сорт коктейлей
Производной пузырьковой сортировки является сортировка коктейлей или шейкерная сортировка. Этот метод сортировки основан на следующем наблюдении: при пузырьковой сортировке элементы могут быстро перемещаться в конец массива, но перемещаются в начало массива только по одной позиции за раз.
Идея сортировки коктейлей состоит в чередовании направления маршрута. Получается несколько более быстрая сортировка, с одной стороны, потому что она требует меньшего количества сравнений, с другой стороны, потому что она перечитывает самые последние данные при изменении направления (поэтому они все еще находятся в кэш-памяти ). Однако количество обменов, которые необходимо произвести, идентично (см. Выше). Таким образом, время выполнения всегда пропорционально n 2 и, следовательно, посредственно.
Три прыжка вниз
Код для этой сортировки очень похож на пузырьковую сортировку. Подобно пузырьковой сортировке, при этой сортировке первыми отображаются самые крупные элементы. Однако это не работает с соседними элементами; он сравнивает каждый элемент массива с тем, который находится на месте большего, и обменивается, когда находит новый, больший.
tri_jump_down(Tableau T)
pour i allant de taille de T - 1 à 1
pour j allant de 0 à i - 1
si T < T
échanger(T, T)
Сортировка combsort
Вариант пузырьковой сортировки, называемый гребенчатой сортировкой ( combsort ), был разработан в 1980 году Влодзимежем Добосевичем и вновь появился в апреле 1991 года в журнале Byte Magazine . Он исправляет главный недостаток пузырьковой сортировки, которой являются «черепахи», и делает алгоритм столь же эффективным, как и быстрая сортировка .
Алгоритм
Принцип действий прост: обходим массив от начала до конца, попутно меняя местами неотсортированные соседние элементы. В результате первого прохода на последнее место «всплывёт» максимальный элемент. Теперь снова обходим неотсортированную часть массива (от первого элемента до предпоследнего) и меняем по пути неотсортированных соседей. Второй по величине элемент окажется на предпоследнем месте. Продолжая в том же духе, будем обходить всё уменьшающуюся неотсортированную часть массива, вставляя найденные максимумы в конец.
Псевдокод сортировки пузырьком:
function bubbleSort(a):
for i = 0 to n - 2
for j = 0 to n - 2
if a > a
swap(a, a)
Использовать
Пузырьковая сортировка. Список был построен в декартовой системе координат, где каждая точка ( x , y ) указывает, что значение y хранится в индексе x . Затем список будет отсортирован пузырьковой сортировкой по значению каждого пикселя
Обратите внимание, что сначала сортируется самый большой конец, а меньшим элементам требуется больше времени, чтобы переместиться в правильное положение.
Хотя пузырьковая сортировка является одним из простейших алгоритмов сортировки для понимания и реализации, ее сложность O ( n 2 ) означает, что ее эффективность резко снижается в списках из более чем небольшого числа элементов. Даже среди простых алгоритмов сортировки O ( n 2 ) такие алгоритмы, как сортировка вставкой , обычно значительно более эффективны.
Из-за своей простоты пузырьковая сортировка часто используется для ознакомления с концепцией алгоритма или алгоритма сортировки для начинающих студентов- информатиков . Тем не менее, некоторые исследователи, такие как Оуэн Астрахан , пошли на многое, чтобы осудить пузырьковую сортировку и ее неизменную популярность в образовании по информатике, рекомендуя даже не преподавать ее.
Жаргон Файл , который лихо звонков bogosort «архетипический извращенно ужасный алгоритм», также вызывает пузырьковую сортировку «общий плохой алгоритм». Дональд Кнут в своей книге «Искусство компьютерного программирования» пришел к выводу, что «пузырьковой сортировке, похоже, нечего рекомендовать, кроме броского названия и того факта, что она приводит к некоторым интересным теоретическим проблемам», некоторые из которых он затем обсуждает.
Пузырьковая сортировка асимптотически эквивалентна по времени работы сортировке вставкой в худшем случае, но эти два алгоритма сильно различаются по количеству необходимых перестановок. Экспериментальные результаты, такие как результаты Astrachan, также показали, что сортировка вставкой работает значительно лучше даже в случайных списках. По этим причинам многие современные учебники алгоритмов избегают использования алгоритма пузырьковой сортировки в пользу сортировки вставкой.
Пузырьковая сортировка также плохо взаимодействует с современным аппаратным обеспечением ЦП. Он производит как минимум вдвое больше записей, чем сортировка вставкой, вдвое больше промахов в кеш и асимптотически больше ошибочных прогнозов переходов . Эксперименты с сортировкой строк Astrachan в Java показывают, что пузырьковая сортировка примерно в пять раз быстрее сортировки вставкой и на 70% быстрее сортировки по выбору .
В компьютерной графике пузырьковая сортировка популярна благодаря своей способности обнаруживать очень маленькие ошибки (например, перестановку всего двух элементов) в почти отсортированных массивах и исправлять их с линейной сложностью (2 n ). Например, он используется в алгоритме заполнения многоугольника, где ограничивающие линии сортируются по их координате x в определенной строке сканирования (линия, параллельная оси x ), а с увеличением y их порядок изменяется (два элемента меняются местами) только при пересечения двух линий. Пузырьковая сортировка — это стабильный алгоритм сортировки, как и сортировка вставкой.
Идея алгоритма
Соседние элементы последовательности сравниваются между собой и, в случае необходимости, меняются местами. В качестве примера рассмотрим упорядочивание методом пузырьковой сортировки массива, количество элементов n которого равно 5: 8, 2, 4, 7, 5. В итоге должен получиться массив с элементами, располагающимися в порядке возрастания их значений.Вначале сравниваются два первых элемента последовательности: 8 и 2, так как значение первого элемента больше значения второго, т. е. 8>2, они меняются местами. Далее, сравниваются второй и третий элементы: девятка больше четверки, следовательно, элементы снова обмениваются позициями. Аналогично алгоритм продолжает выполняться до тех пор, пока все элементы массива не окажутся на своих местах. Всего для этого потребуется n*(n-1) сравнений. В частности, на данной последовательности произведено 20 сравнений и только 5 перестановок.
.
Встроенный язык 1С 8.*
Здесь приведен алгоритм сортировки на примере объекта типа «СписокЗначений», но его можно модифицировать для работы с любым объектом, для этого нужно изменить соответствующим образом код функций «СравнитьЗначения», «ПолучитьЗначение», «УстановитьЗначение».
Функция СравнитьЗначения(Знач1, Знач2)
Если Знач1>Знач2 Тогда
Возврат 1;
КонецЕсли;
Если Знач1<Знач2 Тогда
Возврат -1;
КонецЕсли;
Возврат 0;
КонецФункции
Функция ПолучитьЗначение(Список, Номер)
Возврат Список.Получить(Номер-1).Значение;
КонецФункции
Процедура УстановитьЗначение(Список, Номер, Значение)
Список.Значение = Значение;
КонецПроцедуры
Процедура qs_0(s_arr, first, last)
i = first;
j = last;
x = ПолучитьЗначение(s_arr, Окр((first + last) / 2, 0));
Пока i <= j Цикл
Пока СравнитьЗначения(ПолучитьЗначение(s_arr, i), x)=-1 Цикл
i=i+1;
КонецЦикла;
Пока СравнитьЗначения(ПолучитьЗначение(s_arr, j), x)=1 Цикл
j=j-1;
КонецЦикла;
Если i <= j Тогда
Если i < j Тогда
к=ПолучитьЗначение(s_arr, i);
УстановитьЗначение(s_arr, i, ПолучитьЗначение(s_arr, j));
УстановитьЗначение(s_arr, j, к);
КонецЕсли;
i=i+1;
j=j-1;
КонецЕсли;
КонецЦикла;
Если i < last Тогда
qs_0(s_arr, i, last);
КонецЕсли;
Если first < j Тогда
qs_0(s_arr, first,j);
КонецЕсли;
КонецПроцедуры
Процедура Сортировать(Список, Размер="", Первый="", Последний="")
Если Не ЗначениеЗаполнено(Первый) Тогда
Первый=1;
КонецЕсли;
Если НЕ ЗначениеЗаполнено(Последний) Тогда
Последний=Размер;
КонецЕсли;
qs_0(Список, Первый, Последний);
КонецПроцедуры
Принцип работы
На каждом шаге мы находим наибольший элемент из двух соседних и ставим этот элемент в конец пары. Получается, что при каждом прогоне цикла большие элементы будут всплывать к концу массива, как пузырьки воздуха — отсюда и название.
Алгоритм выглядит так:
- Берём самый первый элемент массива и сравниваем его со вторым. Если первый больше второго — меняем их местами с первым, если нет — ничего не делаем.
- Затем берём второй элемент массива и сравниваем его со следующим — третьим. Если второй больше третьего — меняем их местами, если нет — ничего не делаем.
- Проходим так до предпоследнего элемента, сравниваем его с последним и ставим наибольший из них в конец массива. Всё, мы нашли самое большое число в массиве и поставили его на своё место.
- Возвращаемся в начало алгоритма и делаем всё снова точно так же, начиная с первого и второго элемента. Только теперь даём себе задание не проверять последний элемент — мы знаем, что теперь в конце массива самый большой элемент.
- Когда закончим очередной проход — уменьшаем значение финальной позиции, до которой проверяем, и снова начинаем сначала.
- Так делаем до тех пор, пока у нас не останется один элемент.
Быстрая сортировка (Quick sort)
Быстрая сортировка использует алгоритм «разделяй и властвуй». Она начинается с разбиения
исходного массива на две области. Эти части находятся слева и справа от отмеченного
элемента, называемого опорным. В конце процесса одна часть будет
содержать элементы меньшие, чем опорный, а другая часть будет содержать элементы больше
опорного.
Код C++
void SortAlgo::quickSort(int* data, int const len)
{
int const lenD = len;
int pivot = 0;
int ind = lenD/2;
int i,j = 0,k = 0;
if(lenD>1){
int* L = new int;
int* R = new int;
pivot = data;
for(i=0;i<lenD;i++){
if(i!=ind){
if(data<pivot){
L = data;
j++;
}
else{
R = data;
k++;
}
}
}
quickSort(L,j);
quickSort(R,k);
for(int cnt=0;cnt<lenD;cnt++){
if(cnt<j){
data = L;;
}
else if(cnt==j){
data = pivot;
}
else{
data = R;
}
}
}
}
Поделиться с друзьями
Сложность алгоритма
Сложность алгоритма позволяет дать ему оценку по времени выполнения, то есть определяет его эффективность. Можно выражать сложность по-разному, но чаще всего используется асимптотическая сложность, которая определяет его эффективность при стремлении входных данных к бесконечности.
Точное время выполнения алгоритма не рассматривается, потому что оно зависит слишком от многих факторов: мощность процессора, тип данных массива, используемый язык программирования.
Алгоритм сортировки пузырьком имеет сложность , где – количество элементов массива. Из формулы видно, что сложность сортировки пузырьком квадратично зависит от количества сортируемых элементов. Это значит, что он неэффективен при работе с большими массивами данных.
Следует понимать, что с помощью асимптотической функции нельзя точно вычислить время работы алгоритма. Например, дана последовательность «6 5 4 3 2 1», для её сортировки придется сделать максимальное количество проходов. Такой случай называют наихудшим. Если дана последовательность «3 1 2 4 5», то количество проходов будет минимально, соответственно сортировка пройдет гораздо быстрее. Если же дан уже отсортированный массив, то алгоритму сортировки и вовсе не нужно совершать проходов. Это называется наилучшим случаем.
Пузырьковая сортировка Python 3
# Оптимизированная реализация Python3
# сортировки пузырьком
# Оптимизированная версия пузырьковой сортировки
def bubbleSort(arr):
n = len(arr)
# Проход через все элементы массива
for i in range(n):
swapped = False
# Последние i элементы уже
# на месте
for j in range(0, n-i-1):
# проход через массив от 0
# n-i-1. Поменять местами элементы, если
# найденный элемент больше
# следующего
if arr > arr :
arr, arr = arr, arr
swapped = True
# Если в процессе прохода не было ни одной замены,
# то выход из функции
if swapped == False:
break
# тестирующий код
arr =
bubbleSort(arr)
print ("Сортированный массив :")
for i in range(len(arr)):
print ("%d" %arr,end=" ")
Метод пузырька C — результат сортировки:
Сортированный массив: 11 12 22 25 34 64 90
Худшая и средняя сложность времени: O (n * n). Наихудший случай возникает, когда массив отсортирован по обратному адресу.
Сложность наилучшего случая: O (n). Наилучший случай возникает, когда массив уже отсортирован.
Пограничные случаи: сортировка занимает минимальное время (порядок n), когда элементы уже отсортированы.
Сортировка на месте: Да.
Стабильность: Да.
В компьютерной графике пузырьковая сортировка популярна благодаря возможности обнаруживать мелкие ошибки (например, обмен всего двух элементов) в почти отсортированных массивах и исправлять ее только с линейной сложностью (2n). Например, она используется в алгоритме заполнения полигонов, где ограничивающие линии сортируются по их координате x на определенной линии сканирования (линия, параллельная оси X), и с увеличением Y их порядок меняется (два элемента меняются местами) только на пересечениях двух линий.






Пожалуйста, оставьте свои комментарии, если захотите поделиться дополнительной информацией про алгоритм сортировки пузырьком.
Пожалуйста, оставьте свои комментарии по текущей теме статьи. За комментарии, лайки, дизлайки, отклики, подписки огромное вам спасибо!
ВЛВиктория Лебедеваавтор-переводчик статьи «Bubble Sort»
Динамическое выделение памяти[править]
Ниже приведена программа, где память под массив выделяется динамически:
#include<stdio.h>
#include<stdlib.h>
#include<malloc.h>
intcmp(constvoid*a,constvoid*b){
return*(int*)a-*(int*)b;
}
intmain(){
intn,i;
int*a;
scanf("%d",&n);
a=(int*)malloc(sizeof(int)*n);
for(i=;i<n;i++){
scanf("%d",&ai]);
}
qsort(a,n,sizeof(int),cmp);
for(i=;i<n;i++){
printf("%d ",ai]);
}
free(a);
return;
}
Функция malloc (от англ. memory allocation — выделение памяти) делает запрос к ядру операционной системы по выделению заданного количества байт. Единственный аргумент этой функции — число байт, которое вам нужно. В качестве результата функция возвращает указатель на начало выделенной памяти. Указатель на начало выделенной памяти &mbsah — это адрес ячейки памяти, начиная с которого идут N байт, которые вы можете использовать под любые свои нужды. Всю память, которая была выделена с помощью функции malloc, нужно освобождать с помощью функции free. Аргумент функции free — это указатель на начало выделенной когда-то памяти.
Анализ

Пример пузырьковой сортировки. Начиная с начала списка, сравните каждую соседнюю пару, поменяйте их местами, если они не в правильном порядке (последняя меньше первой). После каждой итерации необходимо сравнивать на один элемент меньше (последний), пока не останется больше элементов для сравнения.
Представление
Пузырьковая сортировка имеет наихудший случай и среднюю сложность О ( n 2 ), где n — количество сортируемых элементов. Большинство практических алгоритмов сортировки имеют существенно лучшую сложность в худшем случае или в среднем, часто O ( n log n ). Даже другое О ( п 2 ) алгоритмы сортировки, такие как вставки рода , как правило , не работать быстрее , чем пузырьковой сортировки, а не более сложным. Следовательно, пузырьковая сортировка не является практическим алгоритмом сортировки.
Единственное существенное преимущество пузырьковой сортировки перед большинством других алгоритмов, даже быстрой сортировкой , но не сортировкой вставкой , заключается в том, что в алгоритм встроена способность определять, что список сортируется эффективно. Когда список уже отсортирован (в лучшем случае), сложность пузырьковой сортировки составляет всего O ( n ). Напротив, большинство других алгоритмов, даже с лучшей средней сложностью , выполняют весь процесс сортировки на множестве и, следовательно, являются более сложными. Однако сортировка вставкой не только разделяет это преимущество, но также лучше работает со списком, который существенно отсортирован (имеет небольшое количество инверсий ). Кроме того, если такое поведение желательно, его можно тривиально добавить к любому другому алгоритму, проверив список перед запуском алгоритма.
Кролики и черепахи
Расстояние и направление, в котором элементы должны перемещаться во время сортировки, определяют производительность пузырьковой сортировки, поскольку элементы перемещаются в разных направлениях с разной скоростью. Элемент, который должен двигаться к концу списка, может перемещаться быстро, потому что он может принимать участие в последовательных заменах. Например, самый большой элемент в списке будет выигрывать при каждом обмене, поэтому он перемещается в свою отсортированную позицию на первом проходе, даже если он начинается рядом с началом. С другой стороны, элемент, который должен двигаться к началу списка, не может двигаться быстрее, чем один шаг за проход, поэтому элементы перемещаются к началу очень медленно. Если наименьший элемент находится в конце списка, потребуется n −1 проход, чтобы переместить его в начало. Это привело к тому, что эти типы элементов были названы кроликами и черепахами соответственно в честь персонажей басни Эзопа о Черепахе и Зайце .
Были предприняты различные попытки уничтожить черепах, чтобы повысить скорость сортировки пузырей. Сортировка коктейлей — это двунаправленная сортировка пузырьков, которая идет от начала до конца, а затем меняет свое направление, идя от конца к началу. Он может довольно хорошо перемещать черепах, но сохраняет сложность наихудшего случая O (n 2 ) . Сортировка гребенкой сравнивает элементы, разделенные большими промежутками, и может очень быстро перемещать черепах, прежде чем переходить к все меньшим и меньшим промежуткам, чтобы сгладить список. Его средняя скорость сопоставима с более быстрыми алгоритмами вроде быстрой сортировки .
Пошаговый пример
Возьмите массив чисел «5 1 4 2 8» и отсортируйте его от наименьшего числа к наибольшему числу, используя пузырьковую сортировку. На каждом этапе сравниваются элементы, выделенные жирным шрифтом . Потребуется три прохода;
- Первый проход
- ( 5 1 4 2 8) → ( 1 5 4 2 8). Здесь алгоритм сравнивает первые два элемента и меняет местами, поскольку 5> 1.
- (1 5 4 2 8) → (1 4 5 2 8), поменять местами, поскольку 5> 4
- (1 4 5 2 8) → (1 4 2 5 8), поменять местами, поскольку 5> 2
- (1 4 2 5 8 ) → (1 4 2 5 8 ). Теперь, поскольку эти элементы уже упорядочены (8> 5), алгоритм не меняет их местами.
- Второй проход
- ( 1 4 2 5 8) → ( 1 4 2 5 8)
- (1 4 2 5 8) → (1 2 4 5 8), поменять местами, поскольку 4> 2
- (1 2 4 5 8) → (1 2 4 5 8)
- (1 2 4 5 8 ) → (1 2 4 5 8 )
Теперь массив уже отсортирован, но алгоритм не знает, завершился ли он. Алгоритму требуется один дополнительный полный проход без какой-либо подкачки, чтобы знать, что он отсортирован.
- Третий проход
- ( 1 2 4 5 8) → ( 1 2 4 5 8)
- (1 2 4 5 8) → (1 2 4 5 8)
- (1 2 4 5 8) → (1 2 4 5 8)
- (1 2 4 5 8 ) → (1 2 4 5 8 )
Пузырьковая сортировка и её улучшения
Сортировка пузырьком

Сортировка пузырьком — один из самых известных алгоритмов сортировки. Здесь нужно последовательно сравнивать значения соседних элементов и менять числа местами, если предыдущее оказывается больше последующего. Таким образом элементы с большими значениями оказываются в конце списка, а с меньшими остаются в начале.
Этот алгоритм считается учебным и почти не применяется на практике из-за низкой эффективности: он медленно работает на тестах, в которых маленькие элементы (их называют «черепахами») стоят в конце массива. Однако на нём основаны многие другие методы, например, шейкерная сортировка и сортировка расчёской.
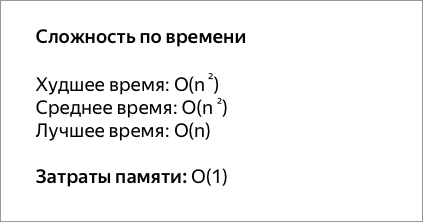
void BubbleSort(vector<int>& values) {
for (size_t idx_i = 0; idx_i + 1 < values.size(); ++idx_i) {
for (size_t idx_j = 0; idx_j + 1 < values.size() - idx_i; ++idx_j) {
if (values < values) {
swap(values, values);
}
}
}
}
Сортировка перемешиванием (шейкерная сортировка)
Шейкерная сортировка отличается от пузырьковой тем, что она двунаправленная: алгоритм перемещается не строго слева направо, а сначала слева направо, затем справа налево.
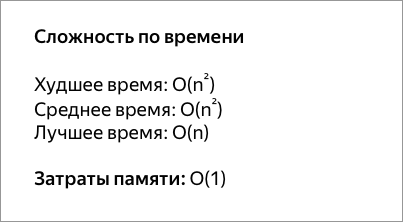
void ShakerSort(vector<int>& values) {
if (values.empty()) {
return;
}
int left = 0;
int right = values.size() - 1;
while (left <= right) {
for (int i = right; i > left; --i) {
if (values > values) {
swap(values, values);
}
}
++left;
for (int i = left; i < right; ++i) {
if (values > values) {
swap(values, values);
}
}
--right;
}
}
Сортировка расчёской
Сортировка расчёской — улучшение сортировки пузырьком. Её идея состоит в том, чтобы «устранить» элементы с небольшими значения в конце массива, которые замедляют работу алгоритма. Если при пузырьковой и шейкерной сортировках при переборе массива сравниваются соседние элементы, то при «расчёсывании» сначала берётся достаточно большое расстояние между сравниваемыми значениями, а потом оно сужается вплоть до минимального.
Первоначальный разрыв нужно выбирать не случайным образом, а с учётом специальной величины — фактора уменьшения, оптимальное значение которого равно 1,247. Сначала расстояние между элементами будет равняться размеру массива, поделённому на 1,247; на каждом последующем шаге расстояние будет снова делиться на фактор уменьшения — и так до окончания работы алгоритма.

void CombSort(vector<int>& values) {
const double factor = 1.247; // Фактор уменьшения
double step = values.size() - 1;
while (step >= 1) {
for (int i = 0; i + step < values.size(); ++i) {
if (values > values) {
swap(values, values);
}
}
step /= factor;
}
// сортировка пузырьком
for (size_t idx_i = 0; idx_i + 1 < values.size(); ++idx_i) {
for (size_t idx_j = 0; idx_j + 1 < values.size() - idx_i; ++idx_j) {
if (values < values) {
swap(values, values);
}
}
}
}
Оптимизация реализации кода Python
Мы можем оптимизировать приведенный выше код, используя два метода. Свопы не производятся; это означает, что список отсортирован. В предыдущем методе оценивается полный список, хотя в этом нет необходимости.
Мы можем предотвратить ненужную оценку, используя логический флаг и проверяя, были ли сделаны какие-либо свопы в предыдущем разделе.
Пример –
def bubble_sort(list1):
# We can stop the iteration once the swap has done
has_swapped = True
while(has_swapped):
has_swapped = False
for i in range(len(list1) - 1):
if list1 > list1:
# Swap
list1, list1 = list1, list1
has_swapped = True
return list1
list1 =
print("The unsorted list is: ", list1)
# Calling the bubble sort function
print("The sorted list is: ", bubble_sort(list1))
Выход:
The unsorted list is: The sorted list is:
Во втором методе мы учитываем тот факт, что итерация заканчивается, когда самый большой элемент списка оказывается в конце списка.
В первый раз мы передаем самый большой элемент в конечную позицию, используя позицию n. Во второй раз мы проходим через позицию n-1, второй по величине элемент.
На каждой последующей итерации мы можем сравнивать на один элемент меньше, чем раньше. Точнее, на k-й итерации нужно сравнить только первые n – k + 1 элементов:
Пример –
def bubble_sort(list1):
has_swapped = True
total_iteration = 0
while(has_swapped):
has_swapped = False
for i in range(len(list1) - total_iteration - 1):
if list1 > list1:
# Swap
list1, list1 = list1, list1
has_swapped = True
total_iteration += 1
print("The number of iteraton: ",total_iteration)
return list1
list1 =
print("The unsorted list is: ", list1)
# Calling the bubble sort funtion
print("The sorted list is: ", bubble_sort(list1))
Выход:
The unsorted list is: The number of iteraton: 6 The sorted list is:
Простые сортировки
Сортировка вставками

При сортировке вставками массив постепенно перебирается слева направо. При этом каждый последующий элемент размещается так, чтобы он оказался между ближайшими элементами с минимальным и максимальным значением.

void InsertionSort(vector<int>& values) {
for (size_t i = 1; i < values.size(); ++i) {
int x = values;
size_t j = i;
while (j > 0 && values > x) {
values = values;
--j;
}
values = x;
}
}
Сортировка выбором
Сначала нужно рассмотреть подмножество массива и найти в нём максимум (или минимум). Затем выбранное значение меняют местами со значением первого неотсортированного элемента. Этот шаг нужно повторять до тех пор, пока в массиве не закончатся неотсортированные подмассивы.
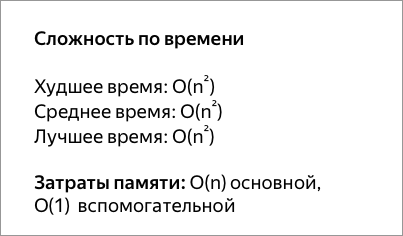
void SelectionSort(vector<int>& values) {
for (auto i = values.begin(); i != values.end(); ++i) {
auto j = std::min_element(i, values.end());
swap(*i, *j);
}
}
Эффективные сортировки
Быстрая сортировка
Этот алгоритм состоит из трёх шагов. Сначала из массива нужно выбрать один элемент — его обычно называют опорным. Затем другие элементы в массиве перераспределяют так, чтобы элементы меньше опорного оказались до него, а большие или равные — после. А дальше рекурсивно применяют первые два шага к подмассивам справа и слева от опорного значения.
Быструю сортировку изобрели в 1960 году для машинного перевода: тогда словари хранились на магнитных лентах, а сортировка слов обрабатываемого текста позволяла получить переводы за один прогон ленты, без перемотки назад.

int Partition(vector<int>& values, int l, int r) {
int x = values;
int less = l;
for (int i = l; i < r; ++i) {
if (values <= x) {
swap(values, values);
++less;
}
}
swap(values, values);
return less;
}
void QuickSortImpl(vector<int>& values, int l, int r) {
if (l < r) {
int q = Partition(values, l, r);
QuickSortImpl(values, l, q - 1);
QuickSortImpl(values, q + 1, r);
}
}
void QuickSort(vector<int>& values) {
if (!values.empty()) {
QuickSortImpl(values, 0, values.size() - 1);
}
}
Сортировка слиянием

Сортировка слиянием пригодится для таких структур данных, в которых доступ к элементам осуществляется последовательно (например, для потоков). Здесь массив разбивается на две примерно равные части и каждая из них сортируется по отдельности. Затем два отсортированных подмассива сливаются в один.

void MergeSortImpl(vector<int>& values, vector<int>& buffer, int l, int r) {
if (l < r) {
int m = (l + r) / 2;
MergeSortImpl(values, buffer, l, m);
MergeSortImpl(values, buffer, m + 1, r);
int k = l;
for (int i = l, j = m + 1; i <= m || j <= r; ) {
if (j > r || (i <= m && values < values)) {
buffer = values;
++i;
} else {
buffer = values;
++j;
}
++k;
}
for (int i = l; i <= r; ++i) {
values = buffer;
}
}
}
void MergeSort(vector<int>& values) {
if (!values.empty()) {
vector<int> buffer(values.size());
MergeSortImpl(values, buffer, 0, values.size() - 1);
}
}
Пирамидальная сортировка
При этой сортировке сначала строится пирамида из элементов исходного массива. Пирамида (или двоичная куча) — это способ представления элементов, при котором от каждого узла может отходить не больше двух ответвлений. А значение в родительском узле должно быть больше значений в его двух дочерних узлах.

Пирамидальная сортировка похожа на сортировку выбором, где мы сначала ищем максимальный элемент, а затем помещаем его в конец. Дальше нужно рекурсивно повторять ту же операцию для оставшихся элементов.

void HeapSort(vector<int>& values) {
std::make_heap(values.begin(), values.end());
for (auto i = values.end(); i != values.begin(); --i) {
std::pop_heap(values.begin(), i);
}
}
Ещё больше интересного — в соцсетях Академии




