Программа для восстановления сайтов из вебархива
Содержание:
- Как увидеть фото ВК в закрытом профиле
- Создание первого в мире сайта
- Как найти уникальный контент для своего сайта
- Как пользоваться веб архивом
- Элементы сайта-истории
- web.archive.org
- archive.md
- Зачем был придуман первый веб-сайт
- Как использовать архив
- web.archive.org
- Как найти архив фото ВК на vk.watch
- История создания Internet Archive
- Как выглядит сайт-история?
- Элементы сайта-истории
- Залог успеха — эмоциональная вовлеченность
- Рунет тоже изменится
- Сохраненная копия страницы в поисковых системах Яндекс и Google
- Проекты, предоставляющие историю сайта
- Инструкция по получению уникальных статей с вебархива
- Зачем нужны сателлиты?
- Заключение
Как увидеть фото ВК в закрытом профиле
Есть несколько простых способов посмотреть, какие фотографии хранит пользователь, если он закрыл свою страницу от просмотров. Одним из них является добавление человека в друзья. Ведь только этому списку пользователей доступна информация на закрытой странице. Если по каким-то причинам вы не можете этого сделать, но данные очень хочется посмотреть, создайте фейковый аккаунт ВК. Добавьте в него реальную фотографию и опишите увлечения, которые бы заинтересовали пользователя.
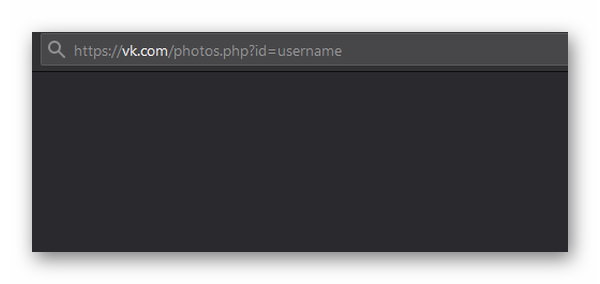
Существуют также технические способы посмотреть изображения, которые хранит закрытый от всех пользователь. Нужно в браузере вставить ссылку: https://vk.com/login?u=2&to=/albums0, где вместо знаков «x» нужно записать ID ВК. В браузере должны открыться фотографии, к которым нет возможности получить доступ. Можно также воспользоваться помощью общих друзей. Если вы общаетесь с теми, кто может посмотреть фото, попросите их сделать для вас несколько скриншотов.
Видеоинструкция
Как увидеть скрытый архив фотографий ВКонтакте при помощи ID пользователя и другие способы описаны в этом ролике.
Создание первого в мире сайта

6 августа 1991 года в интернете появился самый первый во всех смыслах сайт, который располагался по электронному адресу info.cern.ch. Создал его, выше упомянутый Тим Бернерс-Ли, который по сути и стал настоящим отцом современных интернет-технологий.
Внешне первый сайт был невзрачен, что совершенно неудивительно. Он представлял собой сплошную стартовую страницу белого цвета, на которой для посетителей размещалась основная информация о инновационной технологии того времени «World Wide Web». Здесь же, на первом во всем мире сайте, были размещены и подробные инструкции по установке браузеров, а также серверов на свои персональные компьютеры, то есть технологию «WWW», можно смело назвать началом современного интернет-пространства, во всех его проявлениях.
По типу и своей простоте, самый первый сайт был интернет-каталогом, одностраничным, невзрачным, но информационно наполненным. Через некоторое время, разработчик позаботился о том, чтобы превратить этот сайт в широкомасштабный каталог, который предоставлял пользователям информацию о других, не менее важных сайтах и перенаправлял посетителей на их страницы, посредством размещенных в каталоге ссылок.
Как признается сам создатель интернета и сайта, не подозревая о том что за столько короткие сроки интернет наберет столь масштабную популярность среди пользователей во всем мире, он создавал свой сайт чтобы разместить на нем адреса всех интернет-порталов, которые будут создаваться в дальнейшем. Но спустя несколько лет, эта затея стала невозможной, да и ненужной, ведь новые сайты стали появляться все чаще, а некоторые старые сайты менять своих владельцев и уходить в прошлое.
Как найти уникальный контент для своего сайта
Часто возникают ситуации, когда проекты по различным причинам закрывают, удаляя сайт с хостинга. При этом на таком ресурсе могут сохраняться полезные и интересные статьи. Через некоторое время они перестают индексироваться поисковыми системами и текст статей становится уникальным. Для владельцев информационных сайтов подобные статьи на нужную тематику представляют интерес.
Такой контент можно добавлять на собственный проект без угрозы каких-либо санкций со стороны поисковых систем, поскольку для них основное значение имеет уникальность контента на текущий момент, а не его первоисточник. Чтобы найти подходящие статьи, сэкономив время и деньги необходимые на создание собственного контента, нужно предварительно узнать список доменов, которые освободились в последнее время.
Зайдем в раздел продающихся доменов на сервисе Reg.ru, выберем категорию, совпадающую с тематикой собственного проекта, например, здоровье:
Далее выбираем подкатегорию или просматриваем все предложенные домены, выбирая из них варианты для дальнейшего анализа в веб-архиве:
После того как подходящие статьи найдены в веб-архиве необходимо проверить их на уникальность с помощью сервисов антиплагиата, например, text.ru. Если контент уникален, опубликуйте его на собственном сайте.
Как пользоваться веб архивом
Если вы хотите выполнить поиск в архиве веб-страниц, введите в адресную строку вашего браузера адрес web.archive.org.ru, после чего в поле поиска укажите адрес интересуемого сайта. Например, введите адрес домашней страницы Яндекса http://yandex.ru и нажмите клавишу «Enter».
Сохраненные копии главной страницы Яндекс на сайте web.archive.org
Зелеными кружочками обозначены даты когда была проиндексирована страница, нажав на него вы перейдете на архивную копию сайта. Для того чтобы выбрать архивную дату, достаточно кликнуть по временной диаграмме по разделу с годом и выбрать доступные в этом году месяц и число. Так же если вы нажмете на ссылку «Summary of yandex.ru» то увидите, какой контент был проиндексирован и сохранен в архиве для конкретного сайта с 1 января 1996 года ( это дата начала работы веб архива).
Какой контент сохраняет веб-архив интернета
Нажав на выбранную дату, вам откроется архивная копия страницы, такая как она выглядела на веб-сайте в прошлом. Давайте посмотрим на Яндекс в молодости, ниже приведен снимок главной страницы Яндекса на 8 февраля 1999 года.
Веб архив копия сайта Яндекс на 08.02.1999
Вполне возможно, что в архивном варианте страниц, хранящемся на веб-сайте Archive.org, будут отсутствовать некоторые иллюстрации, и возможны ошибки форматирования текста. Это результатом того, что механизм архивирования веб-сайтов, пытается, прежде всего, сохранить текстовый контент web-сайтов. Помните об еще одном ограничении онлайн-архива. При поиске конкретного контента, размещенного на определенной архивной странице, лучше всего вводить ее точный адрес, а не главный адрес данного веб-сайта.
Возвращаясь к нашему примеру: вы получили доступ к архивному контенту, размещенному на главной странице Яндекса, при нажатии на ссылки в архивной версии могут как загружаться так и не загружаться другие страницы сайта. Так в нашем варианте страница «последние 20 запросов» была найдена, а вот страница «Реклама на yandex.ru» не нашлась.
Подводя итоги можно сказать, что web.archive.org поистине уникальный и грандиозный проект. Он действительно является машиной времени для интернета, позволяя найти удаленные сайты и их архивные версии . Как использовать предоставляемые возможности решать только вам, но использовать их можно и нужно обязательно !
Элементы сайта-истории
Любая история – это в первую очередь повествование. История на сайте – не исключение.
Повествование складывается из следующих элементов:
- Персонаж. Выступать в качестве персонажа может продукт компании, сам бренд или что-то еще. Может быть и вымышленный персонаж, который несет в себе собирательный образ, например, целевой аудитории компании.
- Конфликт (событие). В роли конфликта могут быть какие-либо волнующие целевую аудиторию проблемы. Ситуации, в которые попадает клиент и в решении которых может помочь компания.
- Действие. Это те действия, который должен совершить клиент, чтобы решить конфликт, проблему. И в истории рассказывается, какие это должны быть действия. Тут могут быть и действия, которые совершает компания, чтобы решить проблему клиента. Часто описывается конечный результат действий, положительные эмоции от использования продукта, счастье клиента после того, как проблема решена.
web.archive.org
Этот сервис веб архива ещё известен как Wayback Machine. Имеет разные дополнительные функции, чаще всего используется инструментами по восстановлению сайтов и информации.
Для сохранения страницы в архив перейдите по адресу https://archive.org/web/ введите адрес интересующей вас страницы и нажмите кнопку «SAVE PAGE».
Для просмотра доступных сохранённых версий веб-страницы, перейдите по адресу https://archive.org/web/, введите адрес интересующей вас страницы или домен веб-сайта и нажмите «BROWSE HISTORY»:
В самом верху написано, сколько всего снимком страницы сделано, дата первого и последнего снимка.
Затем идёт шкала времени на которой можно выбрать интересующий год, при выборе года, будет обновляться календарь.
Обратите внимание, что календарь показывает не количество изменений на сайте, а количество раз, когда был сделан архив страницы.
Точки на календаре означают разные события, разные цвета несут разный смысл о веб захвате. Голубой означает, что при архивации страницы от веб-сервера был получен код ответа 2nn (всё хорошо); зелёный означает, что архиватор получил статус 3nn (перенаправление); оранжевый означает, что получен статус 4nn (ошибка на стороне клиента, например, страница не найдена), а красный означает, что при архивации получена ошибка 5nn (проблемы на сервере). Вероятно, чаще всего вас должны интересовать голубые и зелёные точки и ссылки.
При клике на выбранное время, будет открыта ссылка, например, http://web.archive.org/web/20160803222240/https://hackware.ru/ и вам будет показано, как выглядела страница в то время:
Используя эту миниатюру вы сможете переходить к следующему снимку страницы, либо перепрыгнуть к нужной дате:
Лучший способ увидеть все файлы, которые были архивированы для определённого сайта, это открыть ссылку вида http://web.archive.org/*/www.yoursite.com/*, например, http://web.archive.org/*/hackware.ru/
Кроме календаря доступна следующие страницы:
- Collections — коллекции. Доступны как дополнительные функции для зарегистрированных пользователей и по подписке
- Changes
- Summary
- Site Map
Changes
«Changes» — это инструмент, который вы можете использовать для идентификации и отображения изменений в содержимом заархивированных URL.
Начать вы можете с того, что выберите два различных дня какого-то URL. Для этого кликните на соответствующие точки:
И нажмите кнопку Compare. В результате будут показаны два варианта страницы. Жёлтый цвет показывает удалённый контент, а голубой цвет показывает добавленный контент.
В этой вкладке статистика о количестве изменений MIME-типов.
Site Map
Как следует из название, здесь показывается диаграмма карты сайта, используя которую вы можете перейти к архиву интересующей вас страницы.
Если вместо адреса страницы вы введёте что-то другое, то будет выполнен поиск по архивированным сайтам:
Показ страницы на определённую дату
Кроме использования календаря для перехода к нужной дате, вы можете просмотреть страницу на нужную дату используя ссылку следующего вида: http://web.archive.org/web/ГГГГММДДЧЧММСС/АДРЕС_СТРАНИЦЫ/
Обратите внимание, что в строке ГГГГММДДЧЧММСС можно пропустить любое количество конечных цифр.
Если на нужную дату не найдена архивная копия, то будет показана версия на ближайшую имеющуюся дату.
archive.md
Адреса данного Архива Интернета:
- http://archive.md
- http://archive.ph/
- http://archive.today/
На главной странице говорящие за себя поля:
- Архивировать страницу, которая сейчас онлайн
- Искать сохранённые страницы
Для поиска по сохранённым страницам можно как указывать конкретный URL, так и домены, например:
- microsoft.com покажет снимки с хоста microsoft.com
- *.microsoft.com покажет снимки с хоста microsoft.com и всех его субдоменов (например, www.microsoft.com)
- покажет архив данного url (поиск чувствителен к регистру)
- поиск архивных url начинающихся с http://twitter.com/burg
Данный сервис сохраняет следующие части страницы:
- Текстовое содержимое веб страницы
- Изображения
- Содержимое фреймов
- Контент и изображения загруженные или сгенерированные с помощью Javascript на сайтах Web 2.0
- Скриншоты размером 1024×768 пикселей.
Не сохраняются следующие части веб-страниц:
- Flash и загружаемый им контент
- Видео и звуки
- RSS и другие XML-страницы сохраняются ненадёжно. Большинство из них не сохраняются, или сохраняются как пустые страницы.
Архивируемая страница и все изображения должны быть менее 50 Мегабайт.
Для каждой архивированной страницы создаётся ссылка вида http://archive.is/XXXXX, где XXXXX это уникальный идентификатор страницы. Также к любой сохранённой странице можно получить доступ следующим образом:
- http://archive.is/2013/http://www.google.de/ — самый новый снимок в 2013 году.
- http://archive.is/201301/http://www.google.de/ — самый новый снимок в январе 2013.
- http://archive.is/20130101/http://www.google.de/ — самый новый снимок в течение дня 1 января 2013.
Дату можно продолжить далее, указав часы, минуты и секунды:
- http://archive.is/2013010103/http://www.google.de/
- http://archive.is/201301010313/http://www.google.de/
- http://archive.is/20130101031355/http://www.google.de/
Для улучшения читаемости, год, месяц, день, часы, минуты и секунды могут быть разделены точками, тире или двоеточиями:
- http://archive.is/2013-04-17/http://blog.bo.lt/
- http://archive.is/2013.04.17-12:08:20/http://blog.bo.lt/
Также возможно обратиться ко всем снимкам указанного URL:
http://archive.is/http://www.google.de/
Все сохранённые страницы домена:
http://archive.is/www.google.de
Все сохранённые страницы всех субдоменов
http://archive.is/*.google.de
Чтобы обратиться к самой последней версии страницы в архиве или к самой старой, поддерживаются адреса вида:
- http://archive.is/newest/http://reddit.com/
- http://archive.is/oldest/http://reddit.com/
Чтобы обратиться к определённой части длинной страницы имеется две опции:
- добавить хэштег (#) с позицией прокрутки в качество которого число между 0 (вершина страницы) и 100 (низ страницы). Например,
- выбрать текст на страницы и получить URL с хэштегом, указывающим на этот раздел. Например,
В доменах поддерживаются национальные символы:
- http://archive.is/www.maroñas.com.uy
- http://archive.is/*.测试
Обратите внимание, что при создании архивной копии страницы архивируемому сайту отправляется IP адрес человека, создающего снимок страницы. Это делается через заголовок X-Forwarded-For для правильного определения вашего региона и показа соответствующего содержимого.
Зачем был придуман первый веб-сайт
Главная страница сайта
Цель проекта банальна для эпохальной технологии на начальной стадии — упростить работу команде. Марк Цукерберг затем же создавал Facebook, чтобы ему и его одногруппникам было проще общаться друг с другом.
ЦЕРН отклонил идею, но Бернерс Ли проявил настойчивость и продолжил разрабатывать сайт, уже в команде с Робертом Кайо.
Так раньше выглядел ЦЕРН, Европейская организация по ядерным исследованиям, крупнейшая в мире лаборатория физики высоких энергий.
Ученый предложил сделать так, чтобы гипертекст был доступен одновременно нескольким компьютерам, подключенным к интернету.
«Меня расстраивало, на разных компьютерах содержалась разная информация. И чтобы получить к ней доступ к нескольким источникам, нужно задействовать несколько компьютеров», — говорил Бернерс Ли.
NeXT. Компьютер, на котором был создан первый веб-сайт.
У британца была и более масштабная задача. В ЦЕРН приезжали люди из университетов со всего мира, и привозили с собой компьютеры со всеми видами программного обеспечения. Проблемой была невозможность использования одной программы на компьютерах с разными видами софта.
Бернерс Ли искал ее решение. Изначально он думал о создании ряда программ, берущих информацию из одной системы и конвертирующих ее формат для показа в другой.
Но оптимизировать программы под каждый софт — долго, энергозатратно и дорого. Британец выбрал другой способ: просто дать доступ к информации всем сразу.
Как использовать архив
Веб-архив используют для следующих целей:
- восстановление собственного сайта, если он был по какой-либо причине утрачен либо поврежден;
- просмотр старой информации и медиа-контента, которого уже нет на работающих сайтах;
- анализ изменения выбранного ресурса с течением времени;
- поиск удаленной уникальной информации, которую затем можно использовать на собственном проекте.
Чтобы просмотреть старые версии нужного сайта, необходимо перейти на сервис веб-архива, указать адрес домена и нажать «BROWSE HISTORY»:
После этого отобразится временная шкала в диапазоне с даты основания ресурса по текущий момент. После клика мышью по году открывается календарь, в котором выбирается желаемая дата. Доступен выбор любой даты, отмеченной зеленым либо голубым кружком. Диаметр круга зависит от количества обращений робота веб-архива к проекту в этот день. Зеленый цвет обозначает редиректы. После выбора даты кликаем на нее для перехода на нужную версию сайта:
В некоторых случаях старые версии сайта могут отсутствовать в веб-архиве. Такое происходит, если правообладатель обратился с требованием удалить копии принадлежащего ему контента либо проект закрыли в связи с нарушением закона о защите интеллектуальной собственности. Бывает также, что разработчики закрыли возможность сканирования сайта роботами веб-архива.
Иногда нужный ресурс доступен, но могут отсутствовать картинки или элементы дизайна, тогда стоит открыть версию сайта, сохраненную в другой день.
web.archive.org
В самом верху написано, сколько всего снимком страницы сделано, дата первого и последнего снимка.
Затем идёт шкала времени на которой можно выбрать интересующий год, при выборе года, будет обновляться календарь.
Обратите внимание, что календарь показывает не количество изменений на сайте, а количество раз, когда был сделан архив страницы.
Точки на календаре означают разные события, разные цвета несут разный смысл о веб захвате. Голубой означает, что при архивации страницы от веб-сервера был получен код ответа 2nn (всё хорошо); зелёный означает, что архиватор получил статус 3nn (перенаправление); оранжевый означает, что получен статус 4nn (ошибка на стороне клиента, например, страница не найдена), а красный означает, что при архивации получена ошибка 5nn (проблемы на сервере). Вероятно, чаще всего вас должны интересовать голубые и зелёные точки и ссылки.
Используя эту миниатюру вы сможете переходить к следующему снимку страницы, либо перепрыгнуть к нужной дате:
Кроме календаря доступна следующие страницы:
- Collections — коллекции. Доступны как дополнительные функции для зарегистрированных пользователей и по подписке
- Changes
- Summary
- Site Map
Changes
«Changes» — это инструмент, который вы можете использовать для идентификации и отображения изменений в содержимом заархивированных URL.
Начать вы можете с того, что выберите два различных дня какого-то URL. Для этого кликните на соответствующие точки:
И нажмите кнопку Compare. В результате будут показаны два варианта страницы. Жёлтый цвет показывает удалённый контент, а голубой цвет показывает добавленный контент.
В этой вкладке статистика о количестве изменений MIME-типов.
Site Map
Как следует из название, здесь показывается диаграмма карты сайта, используя которую вы можете перейти к архиву интересующей вас страницы.
Если вместо адреса страницы вы введёте что-то другое, то будет выполнен поиск по архивированным сайтам:
Показ страницы на определённую дату
Кроме использования календаря для перехода к нужной дате, вы можете просмотреть страницу на нужную дату используя ссылку следующего вида: http://web.archive.org/web/ГГГГММДДЧЧММСС/АДРЕС_СТРАНИЦЫ/
Обратите внимание, что в строке ГГГГММДДЧЧММСС можно пропустить любое количество конечных цифр.
Если на нужную дату не найдена архивная копия, то будет показана версия на ближайшую имеющуюся дату.
Как найти архив фото ВК на vk.watch
Есть и специализированные сайты, на которых можно искать фотографии в архиве пользователя из ВКонтакте по ID идентификатору или по изображению лица.
По адресу https://vk.watch пользователи могут найти подобный сервис. Здесь будет возможность найти также удалённые комментарии, списки друзей и другие исторические данные, к которым сегодня нет доступа. Или они удалены владельцами страниц. Для удачного поиска фотографий нужно знать ID страницы. Или портрет пользователя, фото которых необходимо найти.
Сервис не бесплатен. Для доступа к архивным данным необходимо оплатить подписку – 3.6 доллара. Платным аккаунтом можно будет пользоваться месяц. После чего подписку нужно снова продлить.
На этот сервис часто подписываются адвокаты, рекрутеры и прочие люди, кому могут быть интересны личные данные из страниц ВКонтакте. После получения доступа можно будет увидеть удалённые фотографии друзей и пользователей этой социальной сети. Сайт работает только с ВК.

В открытом доступе можно будет переключаться с фотографий на комментарии других пользователей, которые были удалены. На сайте vk.watch более 500 миллионов архивных профилей ВКонтакте.

И более 1 миллиарда фотографий, которые в данный момент могут быть недоступными. Чтобы найти пользователя по фото, нужно на главной странице выбрать кнопку «Фото лица» и добавить на сайте файл из памяти телефона или компьютера.
Если поиск будет успешным, пользователь увидит имя профиля на следующей страницы. Данные могут быть доступными в том случае, если после удаления страницы из ВК ещё не прошло 6 месяцев.
Это период, который отводится для восстановления страницы. После чего вся информация о пользователе, включая саму страницу, удаляются безвозвратно. При этом данные ещё могут храниться на порталах, таких как archive.org и других.
История создания Internet Archive
В 1996 году Брюстер Кайл, американский программист, создал Архив Интернета, где он начал собирать копии веб-сайтов, со всей находящейся в них информацией. Это были полностью сохраненные в реальном виде страницы, как если бы вы открыли необходимый сайт в браузере.
Данными веб-архива может воспользоваться каждый желающий совершенно бесплатно. Создавая его, у Брюстера Кайла была основная цель – сохранить культурно-исторические ценности интернет-пространства и создать обширную электронную библиотеку.
В 2001 году был создан основной сервис Internet Archive Wayback Machine, который и сегодня можно найти по адресу https://archive.org. Именно здесь находятся копии всех веб-сервисов в свободном доступе для просмотра.
Чтобы не ограничиваться коллекцией сайтов, в 1999 году начали архивировать тексты, изображения, звукозаписи, видео и программные обеспечения.
В марте 2010 года, на ежегодной премии Free Software Awards, Архив Интернета был удостоен звания победителя в номинации Project of Social Benefit.
С каждым годом библиотека разрастается, и уже в августе 2016 года объем Webarchive составил 502 миллиарда копий веб-страниц. Все они хранятся на очень больших серверах в Сан-Франциско, Новой Александрии и Амстердаме.
Как выглядит сайт-история?
Помимо того, что здесь присутствует определенный сюжет, на сайтах-историях многое строится на взаимодействии визуальных частей и интерактивности. Применение техник сторителлинга на сайтах может быть весьма разнообразным. Порой они могут переплетаться с инфографикой, видео и т. п. Иногда сайты полностью основаны на сторителлинге, иногда – лишь частично.
Посмотрите на два сайта, при создании которых применялась техника визуального сторителлинга.
Нажмите для перехода
Нажмите для перехода
На самом деле сайты-истории очень разнообразны. Они могут рассказывать о том, как использовать тот или иной продукт компании, рассказывать о технологиях, которые применяются в производстве, или даже просто создавать определенное настроение у посетителя. Все зависит от целей компании.
Элементы сайта-истории
Любая история – это в первую очередь повествование. История на сайте – не исключение.
Повествование складывается из следующих элементов:
- Персонаж. Выступать в качестве персонажа может продукт компании, сам бренд или что-то еще. Может быть и вымышленный персонаж, который несет в себе собирательный образ, например, целевой аудитории компании.
- Конфликт (событие). В роли конфликта могут быть какие-либо волнующие целевую аудиторию проблемы. Ситуации, в которые попадает клиент и в решении которых может помочь компания.
- Действие. Это те действия, который должен совершить клиент, чтобы решить конфликт, проблему. И в истории рассказывается, какие это должны быть действия. Тут могут быть и действия, которые совершает компания, чтобы решить проблему клиента. Часто описывается конечный результат действий, положительные эмоции от использования продукта, счастье клиента после того, как проблема решена.
Это три основополагающих элемента хорошей истории. Как именно облечь их в визуальную форму на сайте — зависит от задачи
Главное здесь – это не упустить основную идею, отказаться от лишних отвлекающих внимание элементов, чтобы провести внимание зрителя от начала истории (сайта) до конца
Залог успеха — эмоциональная вовлеченность
Залогом успеха сайтов-историй является то, что они вызывают высокую эмоциональную вовлеченность. Они интересные, запоминаются, результативно транслируют нужные идеи.
По данным Koozai, сегодня люди сканируют контент, а не вникают в него
Ищут то, что их заинтересует, и останавливают на этом внимание. Если же контент не сможет выделиться из массы других сообщений и вызвать интерес, то можно считать, что он создан зря – то есть никогда не сможет выполнить возложенные на него функции
Техники сторителлинга позволяют создать сильный визуальный контент. Это понимает большинство маркетологов: по исследованиям Social Media Examiner, процент использования такого контента продолжает расти
Большое внимание уделяется видео. Видеоистории и их применение – в том числе и на сайтах – имеют решающее значение в эффективности маркетинговых кампаний
Исследования направлений движения глаз человека по веб-странице показывают, что пользователи сайтов обращают пристальное внимание на информативно насыщенные изображения. И, соответственно, проводят дольше времени на сайте, где эти изображения есть
И снова здесь выигрывают сайты, созданные с применением сторителлинга.
Есть и другие аспекты, которые влияют на результативность подобных сайтов.
Во-первых, они выделяются среди других, позволяют захватить внимание. Сегодня время, когда информации слишком много и из-за перенасыщенности различными рекламными сообщениями, брендам все труднее завладеть вниманием потенциальных клиентов
Использование историй помогает решить эту проблему. Ведь сама структура историй создаётся так, чтобы захватывать внимание зрителя и вести его от начала истории до конца.
Во-вторых, сообщение поданное с помощью сторителлинга легче для восприятия, это обусловлено тем, как наш мозг воспринимает информацию. А всем известный факт, если перегрузить внимание или сделать сообщение сложным, то оно перестанет работать. Чем проще, тем лучше.
Все это в комплексе и делает сайты-истории результативным инструментом достижения маркетинговых целей.
Рунет тоже изменится
Wayforward Machine работает как с зарубежными, так и иностранными веб-сервисами. Редакция CNews испытала его на ряде частных и государственных ресурсов.
Всплывающие окна требуют загрузить фотографии паспорта и водительских прав, а также предоставить скан сетчатки глаза и отпечатков пальцев
Баннеры появились на сайте Роскомнадзора, а также на главной странице Google и в его поисковой выдаче. В то же время российский поисковик «Яндекс» не только не пустил Wayforward Machine на свою главную страницу, но и в некотором роде улучшил работу сервиса, заставив не только бороться со всплывающими предупреждениями и требованиями, но и пройти тест на робота.
Российский поисковик объединился с Wayforward Machine
Следует отметить, что Wayforward Machine никак не влияет на работу браузера или веб-сайтов. При открытии любой страницы без использования этого сервиса никаких баннеров (за исключением рекламы на сайте) пользователь не увидит.
Работа сервиса Wayforward Machine
В работе самого Wayforward Machine есть некоторые ограничения. В частности, авторы подготовили лишь около 10 различных видов баннеров, тем самым сократив их разнообразие до минимума. С другой стороны, это лишь симуляция интернета будущего – если мрачное будущее все же наступит, число таких всплывающих окон может перевалить за сотни и тысячи.
Сохраненная копия страницы в поисковых системах Яндекс и Google
Для сохранения копий страниц понадобятся дополнительные сервисы. Поисковые системы сохраняют последние версии страниц, которые были проиндексированы поисковым роботом.
Для этого в строке поиска Яндекс вводим адрес сайта с оператором site: или url: в зависимости от того, что хотим проверить конкретную страницу или ресурс целиком. Нажимаем на стрелочку рядом с URL и выбираем «Сохраненная копия».
Откроется последняя версия страницы, которая есть у ПС. Можно посмотреть только текст, выбрав одноименную вкладку.
Посмотреть сохраненную копию конкретной страницы в Google можно с помощью оператора cache. Например, вводим cache:trinet.ru и получаем:
Вы так же можете посмотреть текстовую версию страницы.
Найти сохраненную версию страницы можно и через выдачу Google. Необходимо:
- использовать оператор site:, либо указать сразу необходимый URL
- найти страницу в выдаче
- нажать на стрелочку рядом с URL
- выбрать «Сохраненная копия»
Платформа Serpstat
С помощью этого инструмента можно посмотреть изменения видимости сайта в поисковой выдаче за год или за все время, что сайт находится в базе Serpstat.
Сервис Keys.so
Используя этот сервис можно посмотреть, сколько страниц находится в выдаче, в ТОП – 1, ТОП – 3 и т.д. Можно регулировать параметры на графике и выгружать полную статистику в Excel.
Проекты, предоставляющие историю сайта
Peeep.us в действии
Сегодня существует несколько проектов, которые предоставляют сервисные услуги по отысканию сохраненных копий. Вот некоторые из них:
- Самым популярным и востребованным у пользователей является web.archive.org. Представленный сайт считается наиболее старым на просторах интернета, создание датируется 1996 годом. Сервис проводит автоматический и ручной сбор данных, а вся информация размещается на огромных заграничных серверах.
- Вторым по популярности сайтом считается peeep.us. Ресурс весьма интересен, ведь его можно использовать для сохранения копии информационного потока, который доступен только вам. Заметим, что проект работает со всеми доменными именами и расширяет границы использования веб-архивов. Что касается полноты информации, то представленный сайт не сохраняет картинки и фреймы. С 2015 года также внесен в список запрещенных на территории России.
- Аналогичным проектом, который описывали выше, является archive.is. К отличиям можно отнести полноту сбора информации, а также возможности сохранения страниц из социальных сетей. Поэтому если вы утеряли пост или интересную информацию, можно выполнить поиск через веб-архив.
Инструкция по получению уникальных статей с вебархива
1. Запускаем ваш любимый браузер и вводим адрес web.archive.org.
Главная страница вебархива, где будем искать статьи
2. В поисковой строке набираем интересующую вас тематику, например «траляля»
3. Смотрим выдачу сайтов из вебархива
4. Анализируем домены по следующим признакам
4.1. Количество страниц в вебархиве должно быть больше 50
Выдача вебархива, где можно увидеть сколько страниц в архиве
4.2. Проверяем сайт на работоспособность, для этого копируем домен и вставляем в адресную строку браузера. В нашем случае это домен www.generix.com.ua, он оказался свободен.
4.3. Если же домен будет занят и на нем будет находится сайт по схожей тематике то повторите пункты 4.1 и 4.2
4.4. Проверяем таким образом все домены в выдаче вебархива и сохраняем в блокнот те домены которые нам подходят.
5. Скачиваем программу Web Archive Downloader и с помощью нее сохраняем на компьютер архивные копии сайтов, более подробно по работе с программой вы можете ознакомиться в разделе FAQ.
6. Проверяем полученные статьи на уникальность (как читайте ниже)
7. Используем полученные уникальные статьи по назначению
В принципе все, как вы видите ничего сложного нет, осталось разобраться как проверять статьи на уникальность массово. Ведь вы скачаете их
большое количество.
Зачем нужны сателлиты?
Ключевая задача понятна – продвигать основной ресурс. Чем же именно сателлит может помочь вашему проекту?
Передаёт ссылочный вес на основной сайт
Ссылочная масса – важный фактор ранжирования. Поэтому все чаще компании создают собственные сети сайтов-сателлитов – PBN (Private Blog Network), на которых можно бесплатно разместить ссылки с нужными анкорами, быстро убрать или отредактировать их при необходимости. Преимущество перед биржами в том, что цены на ссылки расти не будут, а за качество размещения полностью отвечаете вы.
Привлекает трафик по более узким запросам
Тематика сайта-спутника в данном случае более конкретная, чем у продвигаемого сайта. Например, для магазина бытовой техники создается сайт отдельно для холодильников, стиральных машин и т.д. Более узконаправленная тематика привлечет качественный трафик, который впоследствии можно передавать на основной сайт.
Заполняет выдачу поисковых систем
Использовать сателлиты можно для вывода в топ не одного своего сайта, а сразу нескольких. По определенным ключевым запросам с помощью сайтов-помощников вы можете полностью вытеснить конкурентов из выдачи.
Заключение
Архивы страниц Глобальной сети могут хранить в себе неожиданные экземпляры, ушедшей в прошлое, эпохи развития HTML-дизайна. Разумеется, манипуляций с чистым кодом сегодня производится уже намного меньше. Для большинства необходимых действий были разработаны визуально понятные и удобные инструменты, которые избавляют вас от необходимости знать код и уметь его писать и редактировать. Тем не менее, плотно работая с различными сайтами, вы периодически будете сталкиваться с необходимостью ручной настройки, а значит ковыряться в исходном коде всё-таки придётся. Но для большинства пользователей и владельцев блогов по интересам, подобные умения могут оказаться абсолютно бесполезными.




