Работа с файлами в python: основы
Содержание:
- Синтаксис YAML¶
- Запись файлов Excel
- Использование модуля wget
- 2: Открытие файла
- С помощью модуля subprocess
- Запись файлов CSV
- Запись excel-файлов
- Запись текстового контента в файл
- Запись в файл Python
- 3: Чтение файла
- Чтение и запись в бинарном режиме доступа
- Открытие файла с помощью функции open()
- Позиции указателя файла
- 2.1. Запись в пустой файл в Python
- Подготовка
- Стилевое оформление
- Шаг 2 — Открытие файла
- Генератор случайных файлов
- Чтение и запись json-файлов
- Открытие и чтение текстового файла
- Создание нового файла
- Читаем бинарный файл с помощью NumPy
- Считываем бинарный файл со строковыми данными в массив байтов
- The file Object Attributes
- Использование методов Writelines и Readlines
- Чтение данных из файла с помощью Python
- Шаг 4 — Запись файла
- Заключение
Синтаксис YAML¶
Как и Python, YAML использует отступы для указания структуры документа.
Но в YAML можно использовать только пробелы и нельзя использовать знаки
табуляции.
Еще одна схожесть с Python: комментарии начинаются с символа # и
продолжаются до конца строки.
Список
Список может быть записан в одну строку:
switchport mode access, switchport access vlan, switchport nonegotiate, spanning-tree portfast, spanning-tree bpduguard enable
Или каждый элемент списка в своей строке:
- switchport mode access - switchport access vlan - switchport nonegotiate - spanning-tree portfast - spanning-tree bpduguard enable
Когда список записан таким блоком, каждая строка должна начинаться с
(минуса и пробела), и все строки в списке должны быть на одном
уровне отступа.
Словарь также может быть записан в одну строку:
{ vlan 100, name IT }
Или блоком:
vlan 100 name IT
Строки
Строки в YAML не обязательно брать в кавычки. Это удобно, но иногда всё
же следует использовать кавычки. Например, когда в строке используется
какой-то специальный символ (специальный для YAML).
Такую строку, например, нужно взять в кавычки, чтобы она была корректно
воспринята YAML:
command "sh interface | include Queueing strategy:"
Запись файлов Excel
>>> import openpyxl
>>> wb = openpyxl.Workbook()
>>> wb.sheetnames
>>> wb.create_sheet(title = 'Первый лист', index = 0)
<Worksheet "Первый лист">
>>> wb.sheetnames
>>> wb.remove(wb)
>>> wb.sheetnames
>>> wb.save('example.xlsx')
Метод возвращает новый объект , который по умолчанию становится последним листом книги. С помощью именованных аргументов и можно задать имя и индекс нового листа.
Метод принимает в качестве аргумента не строку с именем листа, а объект . Если известно только имя листа, который надо удалить, используйте . Еще один способ удалить лист — использовать инструкцию .
Не забудьте вызвать метод , чтобы сохранить изменения после добавления или удаления листа рабочей книги.
Запись значений в ячейки напоминает запись значений в ключи словаря:
>>> import openpyxl >>> wb = openpyxl.Workbook() >>> wb.create_sheet(title = 'Первый лист', index = 0) >>> sheet = wb >>> sheet = 'Здравствуй, мир!' >>> sheet.value 'Здравствуй, мир!'
Заполняем таблицу 3×3:
import openpyxl
# создаем новый excel-файл
wb = openpyxl.Workbook()
# добавляем новый лист
wb.create_sheet(title = 'Первый лист', index = )
# получаем лист, с которым будем работать
sheet = wb'Первый лист'
for row in range(1, 4)
for col in range(1, 4)
value = str(row) + str(col)
cell = sheet.cell(row = row, column = col)
cell.value = value
wb.save('example.xlsx')
Можно добавлять строки целиком:
sheet.append('Первый', 'Второй', 'Третий')
sheet.append('Четвертый', 'Пятый', 'Шестой')
sheet.append('Седьмой', 'Восьмой', 'Девятый')
Использование модуля wget
Один из самых простых способов загрузки файлов в Python – через модуль wget, который не требует открытия файла назначения. Метод загрузки модуля wget загружает файлы всего в одну строку. Метод принимает два параметра: URL-путь к файлу для загрузки и локальный путь, где файл должен быть сохранен.
import wget
print('Beginning file download with wget module')
url = 'http://i3.ytimg.com/vi/J---aiyznGQ/mqdefault.jpg'
wget.download(url, '/Users/scott/Downloads/cat4.jpg')
Выполните приведенный выше скрипт и перейдите в каталог «Загрузки». Здесь вы должны увидеть недавно загруженный файл «cat4.jpg».
2: Открытие файла
Создайте сценарий files.py в текстовом редакторе и для простоты сохраните его в тот же каталог (/users/8host/).
Чтобы открыть файл в Python, нужно связать файл на диске с переменной Python. Сначала сообщите Python, где находится нужный файл. Чтобы открыть какой-либо файл, Python должен знать путь к этому файлу. Путь к файлу days.txt выглядит так: /users/8host/days.txt.
В файле files.py создайте переменную path и укажите в ней путь к файлу days.txt.
Теперь можно использовать функцию open(), чтобы открыть файл days.txt. В качестве первого аргумента функция open() требует путь к файлу, который нужно открыть. Эта функция имеет много других параметров. Одним из основных параметров является режим; это опциональная строка, которая позволяет выбрать режим открытия файла:
- ‘r’: открыть файл для чтения (опция по умолчанию).
- ‘w’: открыть файл для записи.
- ‘x’: создать новый файл и открыть его для записи.
- ‘a’: вставить в файл.
- ‘r+’: открыть файл для чтения и записи.
Попробуйте открыть файл для чтения. Для этого создайте переменную days_file и задайте в ней опцию open() и режим ‘r’, чтобы открыть файл days.txt только для чтения.
С помощью модуля subprocess
Модуль subprocess предназначен для замены некоторых методов в модуле os (в частности, методов os.system и os.spawn *), и он представляет два основных метода доступа к командам операционной системы. Это методы call и check_output. Еще раз, для систем Unix команду «copy file1.txt file2.txt» следует заменить на «cp file1.txt file2.txt».
call Method
Документация Python рекомендует нам использовать метод call для запуска команды из операционной системы.
Синтаксис следующий:
subprocess.call(args, *, stdin=None, stdout=None, stderr=None, shell=False)
Параметр args будет включать нашу команду оболочки. Однако небольшое предостережение, поскольку документация Python предупреждает нас, что использование shell = True может быть угрозой безопасности.
Используя этот вызов функции, мы можем запустить нашу команду копирования следующим образом:
import subprocess
# Windows
status = subprocess.call('copy file1.txt file8.txt', shell=True)
# Unix
status = subprocess.call('cp file1.txt file8.txt', shell=True)
Как показывает пример выше, нам просто нужно передать строку с помощью команды оболочки, как и раньше.
Как и ожидалось, операционная система скопирует file1.txt в файл с именем file8.txt.
Метод check_output
Этот метод также позволяет нам выполнять команду в оболочке. Это очень похоже на команду subprocess.run, за исключением того, что по умолчанию она передает данные из stdout в виде закодированных байтов. Синтаксис следующий:
subprocess.check_output(args, *, stdin=None, stderr=None, shell=False, universal_newlines=False)
Здесь параметр args включает команду оболочки, которую мы хотим использовать
Еще раз, документация Python предупреждает нас об использовании shell = True, поэтому используйте этот метод с осторожностью.. В следующем коде мы скопируем «file1.txt» в «file9.txt» с помощью команды check_output:
В следующем коде мы скопируем «file1.txt» в «file9.txt» с помощью команды check_output:
import subprocess
# Windows
status = subprocess.check_output('copy file1.txt file9.txt', shell=True)
# Unix
status = subprocess.check_output('cp file1.txt file9.txt', shell=True)
И, как и все команды, которые мы показали в этой статье, это скопирует файл «file1.txt» в указанное нами место назначения.
Запись файлов CSV
Мы также можем не только читать, но и писать любые новые и существующие файлы CSV. Запись файлов на Python осуществляется с помощью модуля csv.writer(). Он похож на модуль csv.reader() и также имеет два метода, то есть функцию записи или класс Dict Writer.
Он представляет две функции: writerow() и writerows(). Функция writerow() записывает только одну строку, а функция writerows() записывает более одной строки.
Диалекты
Они определяются как конструкция, которая позволяет создавать, хранить и повторно использовать различные параметры форматирования. Диалект поддерживает несколько атрибутов; наиболее часто используются:
- Dialect.delimiter: этот атрибут используется как разделительный символ между полями. Значение по умолчанию – запятая(,).
- Dialect.quotechar: этот атрибут используется для выделения полей, содержащих специальные символы, в кавычки.
- Dialect.lineterminator: используется для создания новых строк, значение по умолчанию – ‘\r\n’.
Запишем следующие данные в файл CSV.
data =
Пример –
import csv
with open('Python.csv', 'w') as csvfile:
fieldnames =
writer = csv.DictWriter(csvfile, fieldnames=fieldnames)
writer.writeheader()
writer.writerow({'Rank': 'B', 'first_name': 'Parker', 'last_name': 'Brian'})
writer.writerow({'Rank': 'A', 'first_name': 'Smith',
'last_name': 'Rodriguez'})
writer.writerow({'Rank': 'B', 'first_name': 'Jane', 'last_name': 'Oscar'})
writer.writerow({'Rank': 'B', 'first_name': 'Jane', 'last_name': 'Loive'})
print("Writing complete")
Выход:
Writing complete
Он возвращает файл с именем Python.csv, который содержит следующие данные:
first_name,last_name,Rank Parker,Brian,B Smith,Rodriguez,A Jane,Oscar,B Jane,Loive,B
Запись excel-файлов
Для сохранения табличных данных удобнее всего пользоваться библиотекой csv, так как с этим форматом работать проще, он быстрее, может открываться без наличия Excel на рабочем компьютере.
Конечно, бывают ситуации, когда может потребоваться поработать именно с файлами формата «xlsx», для чего подойдет модуль openpyxl. Сначала установим данную библиотеку, так как она не встроена в Питон по умолчанию:
С ее помощью можно читать и записывать данные в «эксель»-файлы.
Основные инструменты, с которыми будем работать:
- Workbook() – класс для создания табличного файла;
- Create_sheet() – внедрение страницы с определенным именем;
- Save() – сохранение результата в файл;
- Cell() – запись информации в ячейку;
- Get_column_letter() – получение буквенного обозначения колонки.
Пример кода:
В результате в созданном файле будем иметь следующее содержимое (рисунок 2).
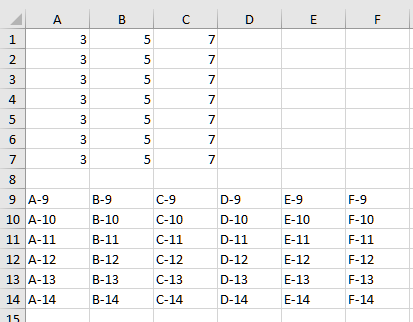 Рисунок 2 – Результат наполнения xlsx-файла
Рисунок 2 – Результат наполнения xlsx-файла
Также вкладка получит название «Запись».
Запись текстового контента в файл
Питон позволяет дозаписывать данные в документ или наполнить его новой информацией. В режиме «w» файл всегда будет перезаписываться полностью.
Запись текста возможна двумя способами:
- Через функцию write(),
- При помощи функции print().
Пример кода:
Первая операция создает файл и записывает в него строчку «Python». Если он существует, то вызовется ошибка FileExistsError. Это своего рода защита от перезаписи.
Вторая операция добавит новую строку в документ. Теперь в нем будет две строки: «Python» и «is great».
В третьем случае старые данные из «somеtext.txt» удалятся, а вместо них будет внедрена новая строчка «Program».
Таким образом, если требуется дозаписывать информацию в файл, то используем режим «a», в противном случае ограничиваемся режимом «w».
Запись в файл Python
Чтобы записать данные в файл в Python, нужно открыть его в режиме ‘w’, ‘a’ или ‘x’. Но будьте осторожны с режимом ‘w’. Он перезаписывает файл, если то уже существует. Все данные в этом случае стираются.
Запись строки или последовательности байтов (для бинарных файлов) осуществляется методом write(). Он возвращает количество символов, записанных в файл.
with open("test.txt",'w',encoding = 'utf-8') as f:
f.write("my first filen")
f.write("This filenn")
f.write("contains three linesn")
Эта программа создаст новый файл ‘test.txt’. Если он существует, данные файла будут перезаписаны. При этом нужно добавлять символы новой строки самостоятельно, чтобы разделять строки.
3: Чтение файла
Теперь вы можете работать с файлом. В зависимости от режима, в котором открыт файл, вы можете выполнить в нём те или иные действия. Для чтения информации Python предлагает три взаимосвязанные операции.
Первая операция – <file>.read(). Она возвращает все содержимое файла в виде одной строки.
Вторая операция – <file>.readline(), которая возвращает содержимое файла построчно.
Прочитав первую строку файла, операция readline при следующем запуске выведет вторую строку.
Третья операция – <file>.readlines(), она возвращает список строк, где строки представлены в виде отдельных элементов.
Читая файлы в Python, важно помнить следующее: если файл был прочитан с помощью одной из операций чтения, его нельзя прочитать снова. К примеру, если вы запустили days_file.read(), а затем days_file.readlines(), вторая операция вернёт пустую строку
Потому нужно открывать новую переменную файла всякий раз, когда вы хотите прочитать данные из файла.
Чтение и запись в бинарном режиме доступа
Что такое
бинарный режим доступа? Это когда данные из файла считываются один в один без
какой-либо обработки. Обычно это используется для сохранения и считывания
объектов. Давайте предположим, что нужно сохранить в файл вот такой список:
books =
("Евгений Онегин", "Пушкин А.С.", 200),
("Муму", "Тургенев И.С.", 250),
("Мастер и Маргарита", "Булгаков М.А.", 500),
("Мертвые души", "Гоголь Н.В.", 190)
Откроем файл на
запись в бинарном режиме:
file = open("out.bin", "wb")
Далее, для работы
с бинарными данными подключим специальный встроенный модуль pickle:
import pickle
И вызовем него
метод dump:
pickle.dump(books, file)
Все, мы
сохранили этот объект в файл. Теперь прочитаем эти данные. Откроем файл на
чтение в бинарном режиме:
file = open("out.bin", "rb")
и далее вызовем
метод load модуля pickle:
bs = pickle.load(file)
Все, теперь
переменная bs ссылается на
эквивалентный список:
print( bs )
Аналогичным
образом можно записывать и считывать сразу несколько объектов. Например, так:
import pickle
book1 = "Евгений Онегин", "Пушкин А.С.", 200
book2 = "Муму", "Тургенев И.С.", 250
book3 = "Мастер и Маргарита", "Булгаков М.А.", 500
book4 = "Мертвые души", "Гоголь Н.В.", 190
try:
file = open("out.bin", "wb")
try:
pickle.dump(book1, file)
pickle.dump(book2, file)
pickle.dump(book3, file)
pickle.dump(book4, file)
finally:
file.close()
except FileNotFoundError:
print("Невозможно открыть файл")
А, затем,
считывание в том же порядке:
file = open("out.bin", "rb")
b1 = pickle.load(file)
b2 = pickle.load(file)
b3 = pickle.load(file)
b4 = pickle.load(file)
print( b1, b2, b3, b4, sep="\n" )
Вот так в Python выполняется
запись и считывание данных из файла.
Открытие файла с помощью функции open()
Первый шаг к работе с файлами в Python – научиться открывать файл. Вы можете открывать файлы с помощью метода open().
Функция open() в Python принимает два аргумента. Первый – это имя файла с полным путем, а второй – режим открытия файла.
Ниже перечислены некоторые из распространенных режимов чтения файлов:
- ‘r’ – этот режим указывает, что файл будет открыт только для чтения;
- ‘w’ – этот режим указывает, что файл будет открыт только для записи. Если файл, содержащий это имя, не существует, он создаст новый;
- ‘a’ – этот режим указывает, что вывод этой программы будет добавлен к предыдущему выводу этого файла;
- ‘r +’ – этот режим указывает, что файл будет открыт как для чтения, так и для записи.
Кроме того, для операционной системы Windows вы можете добавить «b» для доступа к файлу в двоичном формате. Это связано с тем, что Windows различает двоичный текстовый файл и обычный текстовый файл.
Предположим, мы помещаем текстовый файл с именем file.txt в тот же каталог, где находится наш код. Теперь мы хотим открыть этот файл.
Однако функция open (filename, mode) возвращает файловый объект. С этим файловым объектом вы можете продолжить свою дальнейшую работу.
#directory: /home/imtiaz/code.py
text_file = open('file.txt','r')
#Another method using full location
text_file2 = open('/home/imtiaz/file.txt','r')
print('First Method')
print(text_file)
print('Second Method')
print(text_file2)
Результатом следующего кода будет:
================== RESTART: /home/imtiaz/code.py ================== First Method Second Method >>>
Позиции указателя файла
Python предоставляет метод tell(), который используется для печати номера байта, в котором в настоящее время существует указатель файла. Рассмотрим следующий пример.
# open the file file2.txt in read mode
fileptr = open("file2.txt","r")
#initially the filepointer is at 0
print("The filepointer is at byte :",fileptr.tell())
#reading the content of the file
content = fileptr.read();
#after the read operation file pointer modifies. tell() returns the location of the fileptr.
print("After reading, the filepointer is at:",fileptr.tell())
Выход:
The filepointer is at byte : 0 After reading, the filepointer is at: 117
2.1. Запись в пустой файл в Python
Самый простой способ сохранения данных, это записать их в файл. Чтобы записать текс в файл, требуется вызвать open() со вторым аргументом, который сообщит Python что требуется записать файл. Пример программы записи простого сообщения в файл на Python:
filename = ‘memory.txt’
with open(filename, ‘w’) as file:
file.write(«Язык программирования Python»)
Для начала определим название и тип будущего файла и сохраним в переменную filename. Затем при вызове функции open() передадим два аргумента. Первый аргумент содержит имя открываемого файла. Второй аргумент ‘ w ‘ сообщает Python, что файл должен быть открыт в режиме записи. Во второй строчке метод write() используется для записи строки в файл. Открыв файл ‘ memory.txt ‘ вы увидите в нем строку:
Язык программирования Python
Получившийся файл ничем не отличается от любых других текстовых файлах на компьютере, с ним можно делать все что угодно.
Важно: Открывая файл в режиме записи ‘ w ‘, если файл уже существует, то Python уничтожит его данные перед возвращением объекта файла. Файлы можно открывать в режимах:
Файлы можно открывать в режимах:
- чтение ‘ r ‘
- запись ‘ w ‘
- присоединение ‘ a ‘
- режим как чтения, так и записи ‘ r+ ‘
Подготовка
Перед тем, как начать урок, желательно создать один или несколько бинарных файлов, чтобы воспользоваться скриптом из примера. Ниже представлены два скрипта на Python, которые создадут два бинарника. Файл binary1.py создаёт string.bin, содержащий строковые данные, а binary2.py – number_list.bin со списком из числовых данных.
Binary1.py
# Создаём бинарный файл
file_handler = open("string.bin", "wb")
# Добавляем две строки в бинарный файл
file_handler.write(b"Welcome to LinuxHint.\nLearn Python Programming.")
# Закрываем чтение
file_handler.close()
Binary2.py
# Создаём бинарный файл
file=open("number_list.bin","wb")
# Объявляем список с числовыми данными
numbers=
# Конвертируем список в массив
barray=bytearray(numbers)
# Записываем массив в файл
file.write(barray)
file.close()
Стилевое оформление
Для настройки шрифтов, используемых в ячейках, необходимо импортировать функцию из модуля :
from openpyxl.styles import Font
Ниже приведен пример создания новой рабочей книги, в которой для шрифта, используемого в ячейке , устанавливается шрифт , красный цвет, курсивное начертание и размер 24 пункта:
import openpyxl
from openpyxl.styles import Font
# создаем новый excel-файл
wb = openpyxl.Workbook()
# добавляем новый лист
wb.create_sheet(title = 'Первый лист', index = )
# получаем лист, с которым будем работать
sheet = wb'Первый лист'
font = Font(name='Arial', size=24, italic=True, color='FF0000')
sheet'A1'.font = font
sheet'A1' = 'Здравствуй мир!'
# записываем файл
wb.save('example.xlsx')
Именованные стили применяются, когда надо применить стилевое оформление к большому количеству ячеек.
import openpyxl
from openpyxl.styles import NamedStyle, Font, Border, Side
# создаем новый excel-файл
wb = openpyxl.Workbook()
# добавляем новый лист
wb.create_sheet(title = 'Первый лист', index = )
# получаем лист, с которым будем работать
sheet = wb'Первый лист'
# создаем именованный стиль
ns = NamedStyle(name='highlight')
ns.font = Font(bold=True, size=20)
border = Side(style='thick', color='000000')
ns.border = Border(left=border, top=border, right=border, bottom=border)
# вновь созданный именованный стиль надо зарегистрировать
# для дальнейшего использования
wb.add_named_style(ns)
# теперь можно использовать именованный стиль
sheet'A1'.style = 'highlight'
# записываем файл
wb.save('example.xlsx')
Шаг 2 — Открытие файла
Прежде чем написать программу, нужно создать файл для кода Python. С помощью текстового редактора создадим файл files.py. Чтобы упростить задачу, сохраните его в том же каталоге, что и файл days.txt:
/users/sammy/.
Чтобы открыть файл, сначала нужно каким-то образом связать его с переменной в Python. Этот процесс называется открытием файла. Сначала мы укажем Python, где находится файл.
Чтобы Python мог открыть файл, ему требуется путь к нему: days.txt -/users/sammy/days.txt. Затем создаем строковую переменную для хранения этой информации. В нашем скрипте files.py мы создадим переменную path и установим для нее значение days.txt.
files.py
path = '/users/sammy/days.txt'
Затем используем функцию Python open(), чтобы открыть файл days.txt. В качестве первого аргумента она принимает путь к файлу.
Эта функция также позволяет использовать многие другие параметры. Но наиболее важным является параметр, определяющий режим открытия файла. Он зависит от того, что вы хотите сделать с файлом.
Вот некоторые из существующих режимов:
- ‘r’: использовать для чтения;
- ‘w’: использовать для записи;
- ‘x’: использование для создания и записи в новый файл;
- ‘a’: использование для добавления к файлу;
- ‘r +’: использовать для чтения и записи в тот же файл.
В текущем примере нужно только считать данные из файла, поэтому будем использовать режим «r». Применим функцию open(), чтобы открыть файл days.txt и назначить его переменной days_file.
files.py
days_file = open(path,'r')
После открытия файла мы сможем прочитать его, что сделаем на следующем шаге.
Генератор случайных файлов
Создадим папку , а внутри нее еще одну — . Дерево каталогов теперь должно выглядеть вот так:
ManageFiles/ | |_RandomFiles/
Чтобы поиграться с файлами, мы сгенерируем их случайным образом в директории . Создайте файл в папке . Вот что должно получиться:
ManageFiles/ | |_ create_random_files.py |_RandomFiles/
Готово? Теперь поместите в файл следующий код, и перейдем к его рассмотрению:
import os
from pathlib import Path
import random
list_of_extensions =
# перейти в папку RandomFiles
os.chdir('./RandomFiles')
for item in list_of_extensions:
# создать 20 случайных файлов для каждого расширения имени
for num in range(20):
# пусть имя файла начинается со случайного числа от 1 до 50
file_name = random.randint(1, 50)
file_to_create = str(file_name) + item
Path(file_to_create).touch()
Начиная с Python 3.4 мы получили pathlib, нашу маленькую волшебную палочку. Также мы импортируем функцию для генерации случайных чисел, но ее мы посмотрим в действии чуть ниже.
Сперва создадим
список файловых расширений для формирования названий файлов. Не стесняйтесь
добавить туда свои варианты.
Далее мы переходим в папку и запускаем цикл. В нем мы просто говорим: возьми каждый элемент и сделай с ним кое-что во внутреннем цикле 20 раз.
Теперь пришло время для импортированной функции . Используем ее для производства случайных чисел от 1 до 50. Это просто не очень творческий способ побыстрее дать названия нашим тестовым файлам: к сгенерированному числу добавим расширение файла и получим что-то вроде или . И так 20 раз для каждого расширения. В итоге образуется беспорядок, достаточный для того, чтобы его было лень сортировать вручную.
Итак, запустим
наш генератор хаоса через терминал.
python create_random_files.py
Поздравляю,
теперь у нас полная папка неразберихи. Будем распутывать.
В той же директории, где , создадим файл и поместим туда следующий код.
Чтение и запись json-файлов
Для работы с json-объектами предусмотрен встроенный модуль json. Его нужно импортировать для начала.
Практически все объекты Питона можно безболезненно преобразовывать в json-сущности.
В библиотеке json имеется 4 основные функции (таблица 2).
| Функция | Характеристика |
| dumps() | Преобразовывает объекты Питона в json |
| dump() | Записывает преобразованные в json-формат данные в файл |
| loads() | Преобразовывает json-данные в словарь |
| load() | Считывает содержимое json-файла и делает из них словарь |
Таблица 2 – Ключевые функции модуля json
Так как мы рассматриваем тему создания и чтения файлов, то будем использовать соответствующие инструменты.
Создадим на ПК документ «my.json» с таким содержимым:
Теперь считаем их и представим в виде словаря Python.
Пример кода:
Результат выполнения:
Как видно, десериализация json-данных осуществляется следующим образом:
- Двойные кавычки преобразованы в одинарные;
- Булево значение false превратилось в False;
- Объект null соответствует значению None в Питоне.
А теперь расширим информацию в документе «my.json», добавив еще одного студента.
Пример кода:
Открываем файл в режиме чтения и возможности записи («r+»). Считываем имеющееся в нем содержимое и преобразуем его в словарь. Добавляем новую запись в словарь с ключом «student2». Полностью переписываем содержимое документа с учетом новой информации: делаем отступы (indent=4) для удобства чтения, а также отключаем режим «только ASCII», чтобы появилась возможность вставлять кириллицу.
Открытие и чтение текстового файла
Для этого в Питоне имеются следующие конструкции:
- Функция open() – открывает документ в виде файлового объекта;
- Функция close() – закрывает файл и удаляет его из оперативной памяти;
- Контекстный менеджер with (автоматически очищает память после работы с файлом). Его синтаксис показан на рисунке ниже.
 Рисунок 1 – Синтаксис контекстного менеджера with
Рисунок 1 – Синтаксис контекстного менеджера with
- Метод read() – считывает документ полностью или частично в виде строки;
- Метод readline() – построчно выводит содержимое объекта;
- Метод readlines() – формирует из строк файла список.
В папке проекта создадим текстовый документ «econ.txt» с таким наполнением:
Писать код будем в IDE PyCharm (среду разработки скачиваем с официального сайта).
Пример кода:
Результат выполнения:
Создание нового файла
Новый файл можно создать, используя один из следующих режимов доступа с функцией open().
- x: создает новый файл с указанным именем. Вызовет ошибку, если существует файл с таким же именем.
- a: создает новый файл с указанным именем, если такого файла не существует. Он добавляет содержимое к файлу, если файл с указанным именем уже существует.
- w: создает новый файл с указанным именем, если такого файла не существует. Он перезаписывает существующий файл.
Пример 1.
#open the file.txt in read mode. causes error if no such file exists.
fileptr = open("file2.txt","x")
print(fileptr)
if fileptr:
print("File created successfully")
Выход:
<_io.TextIOWrapper name = 'file2.txt' mode = 'x' encoding = 'cp1252'> File created successfully
Читаем бинарный файл с помощью NumPy
В этой части мы поговорим о том, как создать бинарный файл и прочитать его с помощью массивов NumPy. Перед началом работы необходимо установить модуль NumPy командой в терминале или через ваш редактор Python, в котором вы будете писать программу.
Функция создаёт текстовый или бинарный файл, а считывает данные из файла и создаёт массив.
Синтаксис tofile()
ndarray.tofile(file, sep='', format='%s')
Первый аргумент обязательный – он принимает имя файла, путь или строку. Файл создастся, только если будет указан первый аргумент. Второй аргумент – необязательный, он используется для разделения элементов массива. Третий аргумент также необязателен, он отвечает за форматированный вывод содержимого файла.
Синтаксис fromfile()
numpy.fromfile(file, dtype=float, count=- 1, sep='', offset=0, *, like=None)
Первый аргумент обязательный – он принимает имя файла, путь или строку. Содержимое файла будет прочитано, только если вы укажете имя файла. определяет тип данных в возвращаемом массиве. задаёт число элементов массива. – для разделения элементов текста или массива. определяет позицию в файле, с которой начинается считывание. Последний аргумент нужен, чтобы создать массив, не являющийся массивом NumPy.
Напишем следующий код, чтобы создать бинарный файл с помощью массива NumPy, прочитать его и вывести содержимое.
# Импортируем NumPy import numpy as np # Объявляем массив numpy nparray = np.array() # Создаём бинарный файл из numpy-массива nparray.tofile("list.bin") # Выведем данные из бинарного файла print(np.fromfile("list.bin", dtype=np.int64))
Считываем бинарный файл со строковыми данными в массив байтов
В Python существует множество способов прочитать бинарный файл. Можно прочитать определённое количество байтов или весь файл сразу.
В приведенном ниже коде функция открывает для чтения string.bin, а функция на каждой итерации цикла считывает по 7 символов в файле и выводит их. Далее мы используем функцию еще раз, но уже без аргументов — для считывания всего файла. После считывания содержимое выводится на экран.
# Открываем бинарный файл на чтение
file_handler = open("string.bin", "rb")
# Читаем первые 7 байтов из файла
data_byte = file_handler.read(7)
print("Print three characters in each iteration:")
# Проходим по циклу, чтобы считать оставшуюся часть файла
while data_byte:
print(data_byte)
data_byte = file_handler.read(7)
# Записываем всё содержимое файла в байтовую строку
with open('string.bin', 'rb') as fh:
content = fh.read()
print("Print the full content of the binary file:")
print(content)
The file Object Attributes
Once a file is opened and you have one file object, you can get various information related to that file.
Here is a list of all attributes related to file object −
| Sr.No. | Attribute & Description |
|---|---|
| 1 |
file.closed Returns true if file is closed, false otherwise. |
| 2 |
file.mode Returns access mode with which file was opened. |
| 3 |
file.name Returns name of the file. |
| 4 |
file.softspace Returns false if space explicitly required with print, true otherwise. |
Example
#!/usr/bin/python
# Open a file
fo = open("foo.txt", "wb")
print "Name of the file: ", fo.name
print "Closed or not : ", fo.closed
print "Opening mode : ", fo.mode
print "Softspace flag : ", fo.softspace
This produces the following result −
Name of the file: foo.txt Closed or not : False Opening mode : wb Softspace flag : 0
Использование методов Writelines и Readlines
Как упоминалось в начале этой статьи, Python также содержит два метода Writelines() и readlines() для записи и чтения нескольких строк за один шаг соответственно. Чтобы записать весь список в файл на диске, код Python выглядит следующим образом:
# define list of places
places_list =
with open('listfile.txt', 'w') as filehandle:
filehandle.writelines("%s\n" % place for place in places_list)
Чтобы прочитать весь список из файла на диске, код Python выглядит следующим образом:
# define empty list
places = []
# open file and read the content in a list
with open('listfile.txt', 'r') as filehandle:
filecontents = filehandle.readlines()
for line in filecontents:
# remove linebreak which is the last character of the string
current_place = line
# add item to the list
places.append(current_place)
Приведенный выше пример следует более традиционному подходу, заимствованному из других языков программирования. Чтобы написать его более питоническим способом, взгляните на приведенный ниже код:
# define empty list
places = []
# open file and read the content in a list
with open('listfile.txt', 'r') as filehandle:
places =
После открытия файла listfile.txt в строке 5, восстановление списка происходит полностью в строке 6. Во-первых, содержимое файла считывается с помощью readlines(). Во-вторых, в цикле for из каждой строки удаляется символ переноса строки с помощью метода rstrip(). В-третьих, строка добавляется в список мест, как новый элемент списка. По сравнению с приведенным выше листингом код намного компактнее, но может быть более трудным для чтения для начинающих программистов Python.
Чтение данных из файла с помощью Python
Допустим, вы (или ваш пользователь посредством вашего приложения) поместили данные в файл, и ваш код должен их получить. Тогда перед вами стоит цель – прочитать файл. Логика чтения такая же, как логика записи:
- Открыть файл
- Прочесть данные
- Закрыть файл
Опять же, этот логический поток отражает то, что вы и так делаете постоянно, просто используя компьютер (или читая книгу, если на то пошло). Чтобы прочитать документ, вы открываете его, читаете и закрываете. С компьютерной точки зрения «открытие» файла означает загрузку его в память.
На практике текстовый файл содержит более одной строки. Например, вашему коду может потребоваться прочитать файл конфигурации, в котором сохранены данные игры или текст следующей песни вашей группы. Так же, как вы не прочитываете всю книгу прямо в момент открытия, ваш код не должен распарсить весь файл целиком при загрузке в память. Вероятно, вам потребуется перебрать содержимое файла.
f = open('example.tmp', 'r')
for line in f:
print(line)
f.close()
В первой строке данного примера мы открываем файл в режиме чтения. Файл обозначаем переменной , но, как и при открытии файлов для записи, имя переменной может быть произвольным. В имени нет ничего особенного – это просто кратчайший из возможных способов представить слово file, поэтому программисты Python часто используют его.
Во второй строке мы резервируем (еще одно произвольное имя переменной), для представления каждой строки . Это сообщает Python, что нужно выполнить итерацию по строкам нашего файла и вывести каждую из них на экран.
Чтение файла с использованием конструкции with
Как и при записи данных, существует более короткий метод чтения из файлов с использованием конструкции . Поскольку здесь не требуется вызов функции , это более удобно для быстрого взаимодействия.
with open('example.txt', 'r') as f:
for line in f:
print(line)
Шаг 4 — Запись файла
На этом этапе мы запишем новый файл, который включает в себя название «Days of the Week», и дни недели. Сначала создадим переменную title.
files.py
title = 'Days of the Weekn'
Также нужно сохранить дни недели в строковой переменной days. Открываем файл в режиме чтения, считываем файл и сохраняем вывод в новую переменную days.
files.py
path = '/users/sammy/days.txt' days_file = open(path,'r') days = days_file.read()
Теперь, когда у нас есть переменные для названия и дней недели, запишем их в новый файл. Сначала нужно указать расположение файла. Мы будем использовать каталог /users/sammy/. Также нужно указать новый файл, который мы хотим создать. Фактический путь будет /users/sammy/new_days.txt. Мы записываем его в переменную new_path. Затем открываем новый файл в режиме записи, используя функцию open() с режимом w.
files.py
new_path = '/users/sammy/new_days.txt' new_days = open(new_path,'w')
Если файл new_days.txt уже существовал до открытия, его содержимое будет удалено, поэтому будьте осторожны при использовании режима «w».
Когда новый файл будет открыт, поместим в него данные, используя <file>.write(). Операция write принимает один параметр, который должен быть строкой, и записывает эту строку в файл.
Если хотите записать новую строку в файл, нужно указать символ новой строки. Мы записываем в файл заголовок, за которым следуют дни недели.
iles.py
new_days.write(title) print(title) new_days.write(days) print(days)
Всякий раз, когда мы заканчиваем работу с файлом, нужно его закрыть. Мы покажем это в заключительном шаге.
Заключение
Сегодня мы поговорили про чтение и запись файлов с помощью Python. Есть много различных способов записи данных в файлы с помощью Python и множество способов форматирования текста, который вы пишете в файлы, с помощью JSON, YAML, TOML и т.д. Также есть очень хороший встроенный метод для создания и поддержки базы данных SQLite и множество библиотек для обработки любого количества форматов файлов, включая графику, аудио, видео и многое другое.
Возможно, вам также будет интересно:
- Чтение файлов в формате CSV в Python
- Чтение YAML-файлов в Python при помощи модуля PyYAML
- Чтение бинарных файлов с помощью Python
- Как читать excel-файлы (xlsx) при помощи Python
- Использование Python для парсинга файлов конфигурации
Перевод статьи «Reading and writing files with Python».




