Что такое схема базы данных
Содержание:
- Create a table relationship by using the Field List pane to add a field
- 1 Анализ предметной области
- Ключевое поле
- Нормализация базы данных
- Этапы создания базы данных
- Шаблон: «Служба обертывания БД»
- Как хранится информация в БД
- БД из трех таблиц
- Состав частей реляционной модели данных
- Анализ требований: определение цели базы данных
- Правила целостности данных
- Вставка рисунка или объекта
- Колоночные СУБД
- Структура базы данных: построение блоков
- Итоги
Create a table relationship by using the Field List pane to add a field
You can add a field to an existing table that is open in Datasheet view by dragging it from the Field List
pane. The Field List
pane shows fields available in related tables and also fields available in other tables in the database.
Field List
pane and the table to which you dragged the field. This relationship, created by Access, does not enforce referential integrity by default. To enforce referential integrity, you must edit the relationship. See the section for more information.
Open the Field List pane
The Field List
pane shows all of the other tables in your database, grouped into categories. When you work with a table in Datasheet view, Access displays fields in either of two categories in the Field List
pane: Fields available in related tables
and . The first category lists all of the tables that have a relationship with the table with which you are currently working. The second category lists all of the tables with which your table does not have a relationship.
In the Field List
pane, when you click the plus sign (+
) next to a table name, you see a list of all the fields available in that table. To add a field to your table, drag the field that you want from the Field List
pane to the table in Datasheet view.
Add a field and create a relationship from the Field List pane
With the table open in Datasheet view, press ALT+F8. The Field List
pane appears.
Under Fields available in other tables
, click the plus sign (+
) next to a table name to display the list of fields in that table.
Drag the field that you want from the Field List
pane to the table that is open in Datasheet view.
When the insertion line appears, drop the field into position.
The Lookup Wizard
starts.
Follow the instructions to complete the Lookup Wizard
.
The field appears in the table in Datasheet view.
When you drag a field from an «other» (unrelated) table and then complete the Lookup Wizard, a new one-to-many relationship is automatically created between the table in the Field List
and the table to which you dragged the field. This relationship, created by Access, does not enforce referential integrity by default. To enforce referential integrity, you must edit the relationship. See the section for more information.
1 Анализ предметной области
Зачастую, кинотеатр состоит из нескольких залов разной конфигурации, а посетителю предоставляется возможность выбора билета, для этого ему отображается текущее состояние зала. Выбранные места посетитель сообщает кассиру, который вводит их в систему и места помечаются как «проданные». Это «основной» сценарий использования информационной системы, однако надо учесть следующее:
- репертуар и расписание проката кинотеатра должен кто-то вносить в систему — соответствующую роль назовем «Менеджер»;
- посетитель и кассир должны иметь возможность просматривать расписание, при этом интересно расписание, начиная с некоторого момента времени (например, текущего времени). Составлять оно может по-разному:
- расписание показа всех фильмов, упорядоченное по времени;
- расписание прокатов в отдельных залах кинотеатра;
- расписание проката определенного фильма.
Из этого описания понятны основные функции системы, изображенные на рисунке с помощью нотации диаграммы прецедентов UML. На диаграмме не отображена роль администратора базы данных, так как администратор обычно взаимодействует с системой не через интерфейс, а через выполнение SQL-запросов.
Несмотря на то, что мы не будет разрабатывать интерфейс информационной системы и текстовые описания прецедентов, дальше нас будут интересовать данные, необходимые для выполнения того или иного прецедента, а для этого надо выделить и описать сущности. Иначе, невозможно определить «какие данные должен вводить менеджер при добавлении фильма». Основные сущности, данные которых потребуются во время работы, показаны на рисунке, при этом используется нотация диаграммы классов UML. Каждый прямоугольник соответствует одной сущности, внутри записаны поля и типы данных.
Каждая сущность, кроме hall_row содержит поле id, которое идентифицирует объект. У сущности hall_row поле id не нужно, так как в одном и том же зале кинотеатра (id_hall) не могут повторяться номера рядов (number).
Когда пользователь выберет зал и прокат — система должна отобразить заполненность зала, при этом надо отобразить конфигурацию зала с пометкой занятых и свободных мест. Под конфигурацией зала тут имеется ввиду, что разные залы имеют разный размер, а ряды зала могут иметь различное количество мест. Поэтому в базе данных зал (hall) составляется из рядов (hall_row), одним из параметров которых является вместимость (capacity).
Ключевое поле
Ключевое поле
Это та запись, которая определяет запись в таблице.
Нажимаем в колонке слева на названии таблицы Читатель. Справа появилась таблица. Правой кнопкой нажимаем на названии – конструктор – в пустом поле пишем код читателя.
Сделаем это поле ключевым (на панели задач – ключевое поле) и закроем таблицу.
Это первичный ключ. Для ключевых полей используют тип – счетчик или числовой.
Определим ключевое поле для каждой таблицы аналогично предыдущей.
Книги – код книги.
Издательство – код издательства (тип данных –мастер подстановок – Издательство- выберите поле код и наименование).
Выдача – код выдачи (код читателя – таблица Читатель /код читателя и фамилия/ и код книги – таблица Книги/ код книги и название).
Любое поле можно перетащить мышкой в начало таблицы или в другое нужное место. Ключевые поля обычно ставят на первое месте
Связывание таблиц
Переходим на вкладку – Работа с базами данных – схема данных – появилось окно.
Поочередно нажимаем на название каждой таблицы и закрываем окно.
Появилась схема данных. Определим как будем связывать таблицы.
Издательства выпускают книги. Значит, в таблицу Книги надо добавить Код издательства. Для этого открываем таблицу Книги в режиме конструктора и добавляем код издательства.
Возвращаемся в схему данных и перетаскиваем Код издательства из одной таблицы в Код издательства другой. Появляется окно. Ставим Обеспечение целостности данных и в двух других пунктах ниже. Далее нажимаем создать. Появляется связь – один ко многим, т.е. одно издательство выпускает много книг.
Аналогично свяжем две другие таблицы.
Откроем таблицу Выдача через конструктор. Добавляем поле Код читателя.
Сохраняем, закрываем.
Теперь Код читателя таблицы Читатель переносим на Код читателя таблицы Выдача.
Ставим везде галочки — создать. Появилась связь (читатель берет много книг).
Теперь свяжем таблица Книги и Выдача. Для этого в таблицу Выдача добавим Код книги. И проделаем те же манипуляции.
Заполнение таблиц
Берем таблицу Читатель. Код читателя ставим на первое место. Нумерация будет автоматическая в этом поле. Вводим остальные данные (не менее 10) и сохраняем правой кнопкой.
Заполняем остальные таблицы по аналогии.
Нормализация базы данных
После предварительного проектирования базы данных можно применить правила нормализации, чтобы убедиться, что таблицы структурированы правильно.
В то же время не все базы данных необходимо нормализовать. В целом, базы с обработкой транзакций в реальном времени (OLTP), должны быть нормализованы.
Базы данных с интерактивной аналитической обработкой (OLAP), позволяющие проще и быстрее выполнять анализ данных, могут быть более эффективными с определенной степенью денормализации. Основным критерием здесь является скорость вычислений. Каждая форма или уровень нормализации включает правила, связанные с нижними формами.
Первая форма нормализации
Первая форма нормализации (сокращенно 1NF) гласит, что во время логического проектирования базы данных каждая ячейка в таблице может иметь только одно значение, а не список значений. Поэтому таблица, подобная той, которая приведена ниже, не соответствует 1NF:

Возможно, у вас возникнет желание обойти это ограничение, разделив данные на дополнительные столбцы. Но это также противоречит правилам: таблица с группами повторяющихся или тесно связанных атрибутов не соответствует первой форме нормализации. Например, приведенная ниже таблица не соответствует 1NF:

Вместо этого во время физического проектирования базы данных разделите данные на несколько таблиц или записей, пока каждая ячейка не будет содержать только одно значение, и дополнительных столбцов не будет. Такие данные считаются разбитыми до наименьшего полезного размера. В приведенной выше таблице можно создать дополнительную таблицу «Реквизиты продаж», которая будет соответствовать конкретным продуктам с продажами. «Продажи» будут иметь связь 1:M с «Реквизитами продаж».
Вторая форма нормализации
Вторая форма нормализации (2NF) предусматривает, что каждый из атрибутов должен полностью зависеть от первичного ключа. Каждый атрибут должен напрямую зависеть от всего первичного ключа, а не косвенно через другой атрибут.
Например, атрибут «возраст» зависит от «дня рождения», который, в свою очередь, зависит от «ID студента», имеет частичную функциональную зависимость. Таблица, содержащая эти атрибуты, не будет соответствовать второй форме нормализации.
Кроме этого таблица с первичным ключом, состоящим из нескольких полей, нарушает вторую форму нормализации, если одно или несколько полей не зависят от каждой части ключа.
Таким образом, таблица с этими полями не будет соответствовать второй форме нормализации, поскольку атрибут «название товара» зависит от идентификатора продукта, но не от номера заказа:
- Номер заказа (первичный ключ);
- ID товара (первичный ключ);
- Название товара.
Третья форма нормализации
Третья форма нормализации (3NF): каждый не ключевой столбец должен быть независим от любого другого столбца. Если при проектировании реляционной базы данных изменение значения в одном не ключевом столбце вызывает изменение другого значения, эта таблица не соответствует третьей форме нормализации.
В соответствии с 3NF, нельзя хранить в таблице любые производные данные, такие как столбец «Налог», который в приведенном ниже примере, напрямую зависит от общей стоимости заказа:

В свое время были предложены дополнительные формы нормализации. В том числе форма нормализации Бойса-Кодда, четвертая-шестая формы и нормализации доменного ключа, но первые три являются наиболее распространенными.
Многомерные данные
Некоторым пользователям может потребоваться доступ к нескольким разрезам одного типа данных, особенно в базах данных OLAP. Например, им может потребоваться узнать продажи по клиенту, стране и месяцу. В этой ситуации лучше создать центральную таблицу, на которую могут ссылаться таблицы клиентов, стран и месяцев. Например:

Этапы создания базы данных
Надлежащим образом структурированная база данных:
- Помогает сэкономить дисковое пространство за счет исключения лишних данных;
- Поддерживает точность и целостность данных;
- Обеспечивает удобный доступ к данным.
Основные этапы разработки базы данных:
- Анализ требований или определение цели базы данных;
- Организация данных в таблицах;
- Указание первичных ключей и анализ связей;
- Нормализация таблиц.
Рассмотрим каждый этап проектирования баз данных подробнее
Обратите внимание, что в этом руководстве рассматривается реляционная модель базы данных Эдгара Кодда, написанная на языке SQL (а не иерархическая, сетевая или объектная модели)
Шаблон: «Служба обертывания БД»
Когда с чем-то слишком трудно справиться, имеет смысл скрыть беспорядок. С помощью шаблона «Служба обертывания базы данных» (database wrapping service) скрываем БД за службой, которая действует как тонкая «обертка», перенося зависимости БД, которые становятся зависимостями службы, как показано на рис. 3.
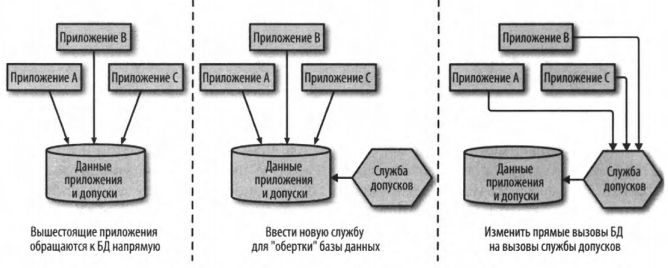 Рис. 3 — Использование службы для «обертывания» базы данных
Рис. 3 — Использование службы для «обертывания» базы данных
Указанный шаблон очень хорошо работает там, где слишком трудно разобрать на части опорную схему. Указанный шаблон имеет преимущества перед использованием простого представления БД. Можно написать код в своей службе обертывания, который будет предоставлять гораздо более изощренные представления на опорные данные. Служба обертывания также принимает операции записи (через вызовы API). Разумеется, внедрение этого шаблона требует от вышестоящих потребителей внесения изменений, им придется перейти от прямого доступа к БД к вызовам API. В идеале, применение этого шаблона будет отправной точкой для более фундаментальных изменений, давая время на то, чтобы разложить схему под слоем API.
Как хранится информация в БД
В основе всей структуры хранения лежат три понятия:
- База данных;
- Таблица;
- Запись.
База данных
База данных — это высокоуровневное понятие, которое означает объединение совокупности данных, хранимых для выполнения одной цели. Если мы делаем современный сайт, то все его данные будут храниться внутри одной базы данных. Для сайта онлайн-дневника наблюдений за погодой тоже понадобится создать отдельную базу данных.
Таблица
По отношению к базе данных таблица является вложенным объеком. То есть одна БД может содержать в себе множество таблиц. Аналогией из реального мира может быть шкаф (база данных) внутри которого лежит множество коробок (таблиц). Таблицы нужны для хранения данных одного типа, например, списка городов, пользователей сайта, или библиотечного каталога. Таблицу можно представить как обычный лист в Excel-таблице, то есть совокупность строк и столбцов. Наверняка каждый хоть раз имел дело с электронными таблицами (MS Excel). Заполняя такую таблицу, пользователь определяет столбцы, у каждого из которых есть заголовок. В строках хранится информация. В БД точно также: создавая новую таблицу, необходимо описать, из каких столбцов она состоит, и дать им имена.
Запись
Запись — это строка электронной таблицы. Это неделимая сущность, которая хранится в таблице. Когда мы сохраняем данные веб-формы с сайта, то на самом деле добавляем новую запись в какую-то из таблиц базы данных. Запись состоит из полей (столбцов) и их значений. Но значения не могут быть какими угодно. Определяя столбец, программист должен указать тип данных, который будет храниться в этом столбце: текстовый, числовой, логический, файловый и т.д. Это нужно для того, чтобы в будущем в базу не были записаны данные неверного типа.
Соберем всё вместе, чтобы понять, как будет выглядеть ведение дневника погоды при участии базы данных.
- Создадим для сайта новую БД и дадим ей название «weather_diary».
- Создадим в БД новую таблицу с именем «weather_log» и определим там следующие столбцы:
- Город (тип: текст);
- День (тип: дата);
- Температура (тип: число);
- Облачность (тип: число; от 0 (нет облачности) до 4 (полная облачность));
- Были ли осадки (тип: истина или ложь);
- Комментарий (тип: текст).
- При сохранении формы будем добавлять в таблицу weather_log новую запись, и заполнять в ней все поля информацией из полей формы.
Теперь можно быть уверенными, что наблюдения наших пользователей не пропадут, и к ним всегда можно будет получить доступ.
Реляционная база данных
Английское слово „relation“ можно перевести как связь, отношение. А определение «реляционные базы данных» означает, что таблицы в этой БД могут вступать в отношения и находиться в связи между собой. Что это за связи? Например, одна таблица может ссылаться на другую таблицу. Это часто требуется, чтобы сократить объём и избежать дублирования информации. В сценарии с дневником погоды пользователь вводит название своего города. Это название сохраняется вместе с погодными данными. Но можно поступить иначе:
- Создать новую таблицу с именем „cities“.
- Все города в России известны, поэтому их все можно добавить в одну таблицу.
- Переделать форму, изменив поле ввода города с текстового на поле типа «select», чтобы пользователь не вписывал город, а выбирал его из списка.
- При сохранении погодной записи, в поле для города поставить ссылку на соответствующую запись из таблицы городов.
Так мы решим сразу две задачи:
- Сократим объём хранимой информации, так как погодные записи больше не будут содержать название города;
- Избежим дублирования: все пользователи будут выбирать один из заранее определённых городов, что исключит опечатки.
Связи между таблицами в БД бывают разных видов. В примере выше использовалась связь типа «один-ко-многим», так как одному городу может соответствовать множество погодных записей, но не наоборот! Бывают связи и других типов: «один-к-одному» и «многие-ко-многим», но они используются значительно реже.
Это интересно: Трудовая книжка
БД из трех таблиц
Сначала необходимо спроектировать структуру базы данных. Например, БД «Учеба».
В ней будет 3 таблицы с полями (полужирным начертанием выделены ключевые поля):
1. «Список курсантов» — №, фамилия, имя, день рождения, пол, улица, дом, кв, группа.
2. «Группы» — номер группы, название группы, преподаватель.
3. «Успеваемость» — код, фамилия, имя, любые 6 предметов.
Ключевые поля можно сделать тип счетчик или числовой.
Откройте новую базу данных Microsoft Access
Сохраните ее в своей папке с именем «Учеба».
Таблицы в ней создадим в режиме Конструктор.
Таблицы заполните произвольными 20 строками в режиме таблицы.
Создадим схему базы данных для данных таблиц во вкладке Работа с базами данных.
Чтобы создать схему данных, надо поочередно выбрать таблицы и протянуть связи левой кнопкой мыши от одной таблицы к другой. В открывшемся окне нажать Ок, поставив галочки в полях таблички.
Таблицы «Группы» и «Список учеников» связать связью «один-ко-многим», а таблицы «Список учеников» и «Успеваемость» — связью «один-к-одному». Таблицы «Группы» и «Успеваемость» напрямую не связаны.
Задание.
Запрос выполняется на вкладке Создание. Выполнить запрос для выделения учащихся (их группу и преподавателей), у которых одновременно экзаменационный балл по химии меньше 75 и больше 50, а по информатике балл меньше 80 и больше 60. Предоставь результат для проверки.
Состав частей реляционной модели данных
Наиболее распространенная трактовка реляционной модели данных, принадлежит Дейту, который воспроизводит ее (с различными уточнениями) практически во всех своих книгах. Согласно Дейту реляционная модель состоит из трех частей, описывающих разные аспекты реляционного подхода: структурной части, манипуляционной части и целостной части.
Структурная часть
Структурная часть (аспект), отвечает за принцип построения структуры реляционной базы данных на нормализированном наборе n-арных отношений, в форме таблиц
Важно что реляционная база данных, структурно может представляться только в виде отношений
Манипуляционная часть
В манипуляционной части модели утверждаются операторы манипулирования отношениями — реляционная алгебра и реляционное исчисление. Первый механизм базируется в основном на классической теории множеств (с некоторыми уточнениями), а второй — на классическом логическом аппарате исчисления предикатов первого порядка. Основной функцией манипуляционной части реляционной модели является обеспечение меры реляционности любого конкретного языка реляционных БД: язык называется реляционным, если он обладает не меньшей выразительностью и мощностью, чем реляционная алгебра или реляционное исчисление.
Целостная часть
В целостной части реляционной модели данных фиксируются два базовых требования целостности, которые должны поддерживаться в любой реляционной СУБД. Первое требование называется требованием целостности сущностей. Объекту или сущности реального мира в реляционных БД соответствуют кортежи отношений. Конкретно требование состоит в том, что любой кортеж любого отношения отличим от любого другого кортежа этого отношения, т.е. другими словами, любое отношение должно обладать первичным ключом. Как мы видели в предыдущем разделе, это требование автоматически удовлетворяется, если в системе не нарушаются базовые свойства отношений.
Второе требование называется требованием целостности по ссылкам и является несколько более сложным. Очевидно, что при соблюдении нормализованности отношений сложные сущности реального мира представляются в реляционной БД в виде нескольких кортежей нескольких отношений.
Требование целостности по ссылкам, или требование внешнего ключа состоит в том, что для каждого значения внешнего ключа, появляющегося в ссылающемся отношении, в отношении, на которое ведет ссылка, должен найтись кортеж с таким же значением первичного ключа, либо значение внешнего ключа должно быть неопределенным (т.е. ни на что не указывать).
Анализ требований: определение цели базы данных
Например, если вы создаете базу данных для публичной библиотеки, нужно продумать, каким образом и читатели, и библиотекари должны получать доступ к БД.
Вот несколько способов сбора информации перед созданием базы данных:
- Опрос людей, которые будут ее использовать;
- Анализ бизнес-форм, таких как счета-фактуры, расписания, опросы;
- Рассмотрение всех существующих систем данных (включая физические и цифровые файлы).
Начните со сбора существующих данных, которые будут включены в базу. Затем определите типы данных, которые нужно сохранить. А также объекты, которые описывают эти данные. Например:
Клиенты
- Имя;
- Адрес;
- Город, штат, почтовый индекс;
- Адрес электронной почты.
Товары
- Название;
- Цена;
- Количество в наличии;
- Количество под заказ.
Заказы
- Номер заказа;
- Торговый представитель;
- Дата;
- Товар;
- Количество;
- Цена;
- Стоимость.
При проектировании реляционной базы данных эта информация позже станет частью словаря данных, в котором описаны таблицы и поля БД. Разбейте информацию на минимально возможные части. Например, подумайте о том, чтобы разделить поле почтового адреса и штата, чтобы можно было фильтровать людей по штату, в котором они проживают.
После того, как вы определились с тем, какие данные будут включены в базу, откуда эти данные будут поступать, и как они будут использоваться, можно приступить к планированию фактической БД.
Правила целостности данных
Также с помощью средств проектирования баз данных необходимо настроить БД с учетом возможности проверки данных на соответствие определенным правилам. Многие СУБД, такие как Microsoft Access, автоматически применяют некоторые из этих правил.
Правило целостности гласит, что первичный ключ никогда не может быть равен NULL. Если ключ состоит из нескольких столбцов, ни один из них не может быть равен NULL. В противном случае он может неоднозначно идентифицировать запись.
Правило целостности ссылок требует, чтобы каждый внешний ключ, указанный в одной таблице, сопоставлялся с одним первичным ключом в таблице, на которую он ссылается. Если первичный ключ изменяется или удаляется, эти изменения необходимо реализовать во всех объектах, на которые ссылается этот ключ в базе данных.
Правила целостности бизнес-логики обеспечивают соответствие данных определенным логическим параметрам. Например, время встречи должно быть в пределах стандартных рабочих часов.
Вставка рисунка или объекта
Создание других таблиц для этой базы данных — аналогичное.
Создайте еще 5 таблиц самостоятельно.
Вставка в запись рисунка или объекта
Рисунок или объект добавляется из имеющегося файла либо создается в приложении OLE (например, в MS Paint), а затем вставляется в текущую запись.
Рассмотрим размещение объекта OLE на примере поля Фотография начальника в таблице Преподаватели. Фотографии хранятся в формате графического редактора Paint в файлах с расширением .bmp. Если рисунка в вашем файле нет, то создайте его самостоятельно и сохраните.
- В окне базы данных установите курсор на таблице Преподаватели и нажмите кнопку Открыть
- Заполните строки (записи) открывшейся таблицы данными в соответствии с названиями столбцов (полей)
- Для размещения поля Фотография начальника выполните внедрение объекта OLE в файл базы данных. Установите курсор в соответствующее поле таблицы. Выполните команду меню Вставка|Объект
- В окне Вставка объекта выберите тип объекта Paintbrush Picture и установите флажок Создать из файла
- В этом окне можно ввести имя файла, содержащего фотографию.
- Для просмотра внедренного объекта установите курсор в соответствующее поле и дважды щелкните кнопкой мыши
- Чтобы вернуться из программы Paint, выполните команду Файл|Выход и возврат к таблице Преподаватели.
Размещение данных типа МЕМО в таблице
В таблице ПРЕДМЕТ предусмотрено поле ПРОГРАММА, которое будет содержать длинный текст – краткую программу курса. Для такого поля выберите тип данных ПолеМЕМО.
Колоночные СУБД
Колоночные СУБД очень похожи на реляционные. Они так же состоят из строк, которые имеют атрибуты, а строки группируются в таблицах. Различия в логических моделях несущественные, а вот на уровне физического хранения данных различия значительные.
В реляционных СУБД данные хранятся «построчно», это означает что для считывания значения определенной колонки, придется прочитать практически всю строку, как минимум от первой до нужной колонки. В колоночной СУБД данные хранятся «поколоночно», т.е. колонка — это как отдельная таблица. Соответственно чтение будет происходить из конкретного столбца сразу. На практике это реально работает очень быстро (проверено мной на нескольких реализованных хранилищах данных).
Основные преимущества колоночных СУБД – эффективное выполнения сложных аналитических запросов на больших объемах, и легкое, практически мгновенное, изменение структуры таблиц с данными, плюс существенная компрессия и сжатие, которое позволяет значительно экономить место.
Яркие представители колоночных СУБД — Sybase IQ (ныне SAP IQ), Vertica, ClickHouse, Google BigTable, InfoBright, Cassandra.
Когда выбирать колоночные СУБД
Один из весомых аргументов за использование именно колоночной СУБД — это если вы хотите построить хранилище данных, и планируете делать выборки со сложными аналитическими вычислениями. Косвенный признак, который так же может сигнализировать о том, что имеет смысл, хотя бы посмотреть в сторону колоночных СУБД — это если количество строк, из которых делаются выборки, превышает сотни миллионов.
Когда не выбирать колоночные СУБД
Учитывая специфику колоночных СУБД, будет не эффективно ее использовать, если выборки достаточно простые, параметры выборки статичны, и если преобладают выборки по ключевым значениям. Так же, если количество строк в таблице, из которой делается выборка, меньше сотен миллионов строк, то скорее всего не будет большого преимущества, по сравнению с реляционной СУБД.
Нужно так же иметь ввиду, что в колоночных СУБД могут быть и другие ограничения. Например, может отсутствовать поддержка транзакций, а язык запросов может отличаться от классического SQL, и прочее.
Структура базы данных: построение блоков
Следующим шагом будет визуальное представление базы данных. Для этого нужно точно знать, как структурируются реляционные БД. Внутри базы связанные данные группируются в таблицы, каждая из которых состоит из строк и столбцов.
Чтобы преобразовать списки данных в таблицы, начните с создания таблицы для каждого типа объектов, таких как товары, продажи, клиенты и заказы. Вот пример:
Каждая строка таблицы называется записью. Записи включают в себя информацию о чем-то или о ком-то, например, о конкретном клиенте. Столбцы (также называемые полями или атрибутами) содержат информацию одного типа, которая отображается для каждой записи, например, адреса всех клиентов, перечисленных в таблице.

Чтобы при проектировании модели базы данных обеспечить согласованность разных записей, назначьте соответствующий тип данных для каждого столбца. К общим типам данных относятся:
- CHAR — конкретная длина текста;
- VARCHAR — текст различной длины;
- TEXT — большой объем текста;
- INT — положительное или отрицательное целое число;
- FLOAT, DOUBLE — числа с плавающей запятой;
- BLOB — двоичные данные.
Некоторые СУБД также предлагают тип данных Autonumber, который автоматически генерирует уникальный номер в каждой строке.
В визуальном представлении БД каждая таблица будет представлена блоком на диаграмме. В заголовке каждого блока должно быть указано, что описывают данные в этой таблице, а ниже должны быть перечислены атрибуты:

При проектировании информационной базы данных необходимо решить, какие атрибуты будут служить в качестве первичного ключа для каждой таблицы, если таковые будут. Первичный ключ (PK) — это уникальный идентификатор для данного объекта. С его помощью вы можете выбрать данные конкретного клиента, даже если знаете только это значение.
Атрибуты, выбранные в качестве первичных ключей, должны быть уникальными, неизменяемыми и для них не может быть задано значение NULL (они не могут быть пустыми). По этой причине номера заказов и имена пользователей являются подходящими первичными ключами, а номера телефонов или адреса — нет. Также можно использовать в качестве первичного ключа несколько полей одновременно (это называется составным ключом).
Когда придет время создавать фактическую БД, вы реализуете как логическую, так и физическую структуру через язык определения данных, поддерживаемый вашей СУБД.
Также необходимо оценить размер БД, чтобы убедиться, что можно получить требуемый уровень производительности и у вас достаточно места для хранения данных.
Итоги
Важное замечание – не пытайтесь сразу все задачи решить в рамках одной СУБД. Это более чем нормально иметь несколько разных типов СУБД
Так же, не пытайтесь сразу определиться с производителем СУБД, или связать свою жизнь с одним конкретным брендом.
При выборе типа СУБД следует, прежде всего, исходить из типа решаемых задач, типов обрабатываемых данных, перспектив роста и масштабирования.
Обращайте так же внимание на популярность и наличие широкого круга разработчиков и средств разработки – это даст вам возможность, при необходимости, найти ответ на возникший вопрос быстро. В данной статье я намеренно не делаю акцент на выбор между облачными и on-premise решениями — эта тема одной из следующих статей
В данной статье я намеренно не делаю акцент на выбор между облачными и on-premise решениями — эта тема одной из следующих статей.
Итак, в таблице представленной ниже, кратко собрано то, что описано выше в статье.
|
Тип СУБД |
Когда выбирать |
Примеры популярных СУБД |
|
Реляционные |
Нужна транзакционность; высокая нормализация; большая доля операций на вставку |
Oracle, MySQL, Microsoft SQL Server, PostgreSQL |
|
Ключ-значение |
Задачи кэширования и брокеры сообщений |
Redis, Memcached |
|
Документные |
Для хранения объектов в одной сущности, но с разной структурой; хранение структур на основе JSON |
CouchDB, MongoDB, Amazon DocumentDB |
|
Графовые |
Задачи подобные социальным сетям; системы оценок и рекомендаций |
Neo4j, Amazon Neptune, InfiniteGraph, InfoGrid |
|
Колоночные |
Хранилища данных; выборки со сложными аналитическими вычислениями; количество строк в таблице превышает сотни миллионов |
Vertica, ClickHouse, Google BigTable, Sybase \ SAP IQ, InfoBright, Cassandra |
Надеюсь данная статья оказалась полезной.
В следующих статьях посмотрим на выбор между облачными и on-premise СУБД, платными и бесплатными, и многое другое.




