База данных
Содержание:
- Недостатки реляционных баз
- А что там внутри. Пример нормализации
- Проблемы модели
- Виды СУБД
- Иерархическая база данных, структура иерархических данных
- MVCC — MultiVersion Concurrency Control
- Требования к проектированию БД
- MySQL
- Ключи и индексы
- SQLite
- Что такое базы данных (БД) и зачем они нужны
- Типы данных в базах
- Нормализация базы данных
- Ключ-значение
- Рейтинг
- Итоги
Недостатки реляционных баз
Поскольку каждый запрос выполняется к целой таблице, время выполнения запроса зависит от размера таблицы
Это важное ограничение, которое заставляет нас сохранять таблицы относительно небольшими и проводить оптимизацию БД для ее масштабирования.
Масштабирование осуществляется добавлением вычислительных мощностей к компьютеру, на котором установлена БД, этот метод называется вертикальное масштабирование. Почему это недостаток? Потому, что существует предел вычислительной мощности компьютера, добавление ресурсов провоцирует простой.
Не поддерживаются объекты на основе ООП, даже представление простых списков очень сложно.
А что там внутри. Пример нормализации
Разберём устройство реляционной БД подробнее на примере. Позже это поможет нам понимать и сравнивать базы разных типов.
Допустим, у нас есть база данных, в которой всего одна таблица — Messages. В ней хранится информация о телефонных разговорах клиентов и операторов компании по ремонту техники.
Каждая строка этой таблицы содержит данные о звонке клиента по его проблеме и ответ оператора, а также дату обращения.
Телефон у компании многоканальный. Поэтому одному и тому же оператору могут звонить разные клиенты, а один и тот же клиент может попадать на разных операторов с разными вопросами.
Проблемы модели
Преимущество реляционных хранилищ состоит в том, что они способны обеспечить наилучшее соотношение устойчивости, производительности, гибкости, совместимости и масштабируемости. Реляционные БД предоставляют лёгкий доступ к составляемым отчётам и обеспечивают высокую надёжность и целостность информации из-за отсутствия избыточных данных. Но сейчас, когда всё большее количество приложений работает с высокой нагрузкой, увеличивается значение фактора масштабируемости.
Реляционные БД легко масштабируются, только когда они расположены на одном сервере. Если потребуется увеличить количество серверов и разделить нагрузку между ними, то возрастёт сложность хранилищ, что значительно снизит возможность использовать их как платформу для мощных распределённых систем. Поэтому приходится применять другие типы БД, которые обладают лучшей масштабируемостью и отказываться от возможностей, предоставляемых реляционными хранилищами.
Реляционная БД — это совокупность связей, которые способны структурировать данные, что даёт возможность рационального хранения и эффективного использования информационных материалов.
Виды СУБД
Сами по себе таблицы или база данных не способны выполнять операции, а в СУБД можно создавать новые таблицы, удалять ненужные данные, настраивать ключи и обрабатывать запросы. Основные задачи СУБД:
- поддержка языков баз данных;
- непосредственное управление данными;
- управление буферами оперативной памяти;
- управление транзакциями;
- резервное копирование и восстановление после сбоев.
Существуют разные виды таких систем, которые разрабатывает и техногиганты, вроде Google, Microsoft и Amazon, и более нишевые студии. Разработчики стремятся сделать свой продукт лучше, чтобы их система быстрее и качественнее других обрабатывала данные. Из-за этого появились разные виды языка SQL — так называемые SQL-диалекты. У каждой СУБД диалект имеет что-то общее со всеми, а также свои особенности, которые не будут работать в другой системе.
СУБД могут быть коммерческими или иметь открытый код. Системы управления с открытым кодом можно бесплатно использовать в проектах, а также дополнять их документацию и совершенствовать процесс работы с системой. Коммерческие СУБД имеют платный доступ к полным версиям — как правило, такие используют крупные корпорации.
PostgreSQL — это объектно-ориентированная система, то есть она обрабатывает данные как абстрактные объекты. Каждый объект, в отличие от простых табличных значений, может иметь собственные характеристики и уникальные методы взаимодействия с другими объектами. Это позволяет PostgreSQL обрабатывать более сложные структуры данных и выполнять более сложные процедуры. Например, Яндекс.Почта в свое время перешла на эту систему, чтобы поддерживать стабильное соединение десятков тысяч пользователей к одной базе.
MySQL — простая в изучении и функциональная система, которая работает с сайтами и веб-приложениями. Чаще всего используется в системах управления контентом сайтов (CMS), на сайтах с возможностью регистрации пользователей, в корпоративных системах CRM, в планировщиках, чатах и форумах. MySQL считается одним из самых безопасных и высокоскоростных решений, которое существует на рынке.
SQLite — это облегченная встраиваемая версия СУБД. В ней нет возможности поделиться правами доступа, как во многих других системах, но благодаря своему устройству эта система быстрая и мощная. SQLite подходит для обработки запросов на сайтах с низким и средним трафиком, а также в однопользовательских мобильных приложениях и играх. Преимущество такой системы — файловая структура, то есть база в SQLite состоит из одного файла, поэтому ее очень легко переносить.
Oracle — одна из первых СУБД, которая появилась еще в 1977 году и развивается до сих пор. Это кроссплатформенная система, которая может работать на Windows, Linux, MacOS, мобильных и других ОС. Система используется в крупных коммерческих проектах. Например, в России с Oracle сотрудничают операторы МТС и Теле2, банк «Открытие» и ВТБ.
Google Cloud Spanner — это облачная система управления данными, которую Google разработал для управления собственными сервисами, например AdWords и Google Play. В 2017 году систему сделали общедоступной. Cloud Spanner относят к категории NewSQL — это системы, которые совмещают в себе преимущества реляционных и нереляционных СУБД.
Иерархическая база данных, структура иерархических данных
Когда речь идёт о хранении иерархических данных, каждый объект хранит информацию в виде определенной сущности, и у каждой сущности могут быть родительские и дочерние элементы, а у дочерних, в свою очередь, тоже могут быть дочерние элементы. Таким образом, можно сказать, что это данные, которые подлежат строгой иерархии (представьте себе своеобразное дерево).
Простой пример иерархических данных — документ в формате XML либо файловая система компьютера.
Нельзя не упомянуть и то, что базы данных этого вида оптимизированы под чтение информации. При такой структуре данные можно быстро выбирать из нужной области, отдавая запрашиваемую информацию пользователям. Например, компьютер легко работает с конкретной папкой либо файлом, которые, по сути, можно назвать объектами структуры иерархических данных. Но когда нужно перебрать всю информацию, это может занять время (если вернуться к вышеописанному примеру, то проверка антивирусом всех уголков нашего компьютера выполняется не так быстро, как хотелось бы).
На рисунке представлена классическая структура иерархической базы данных. Вверху находится родитель (его ещё называют корневым элементом), ниже размещены дочерние элементы. Элементы с данными, находящиеся на одном уровне, можно назвать братьями либо соседними элементами. БД данной категории бывают с разным количеством уровней и разной степени вложенности.
MVCC — MultiVersion Concurrency Control
 zr1(y)yyy
zr1(y)yyy
Как это работает?
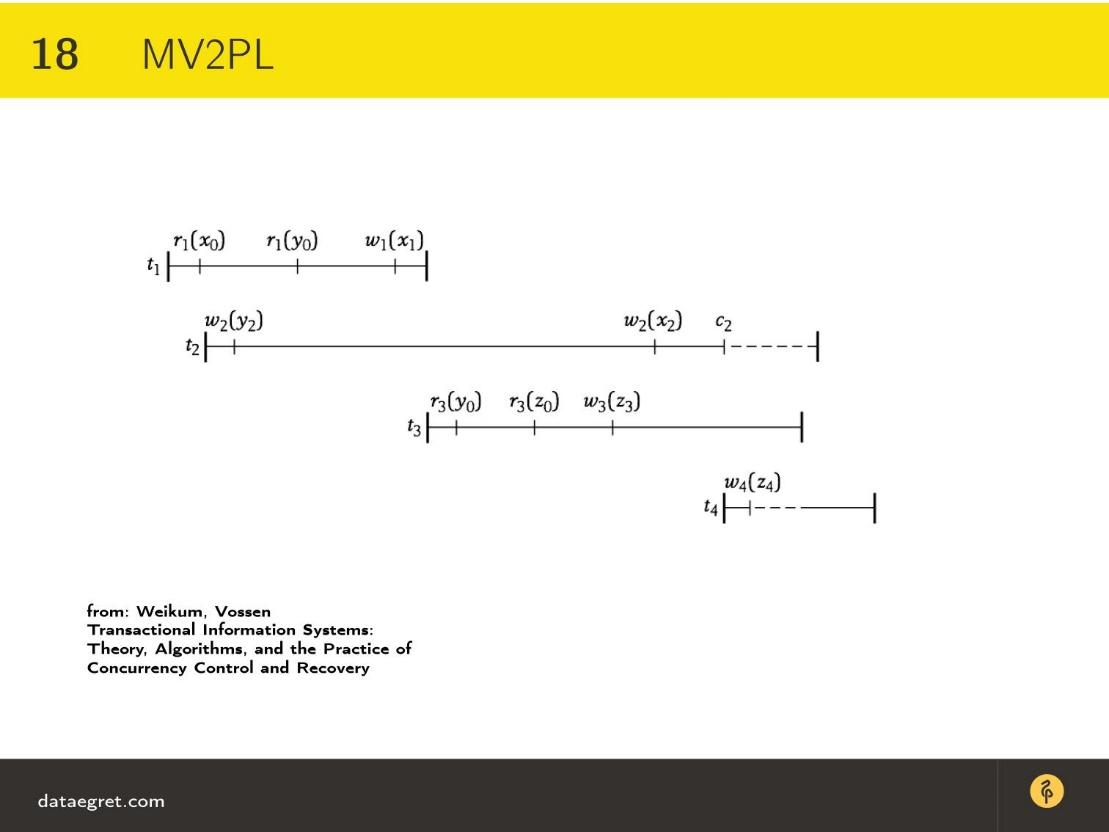
- Когда мы пошли исполнять транзакцию t1, имеется чтение x, т.е. самой изначальной версии.
- Дальше в t2 мы начинаем записывать y другой версии, потому что он был изменен.
- В транзакции t1, которая началась раньше, чем мы начали записывать y, до сих пор видно предыдущую версию y, поскольку t2 еще не завершилась, и мы и спокойно начать с ней работать.
- Поскольку транзакция t1 заканчивается раньше, чем w2(y2), то произойдет перечитываниеy,и после этого в транзакции t 2 выполнится нормальная работа, а другая транзакция просто нормально завершится.
yw2yt1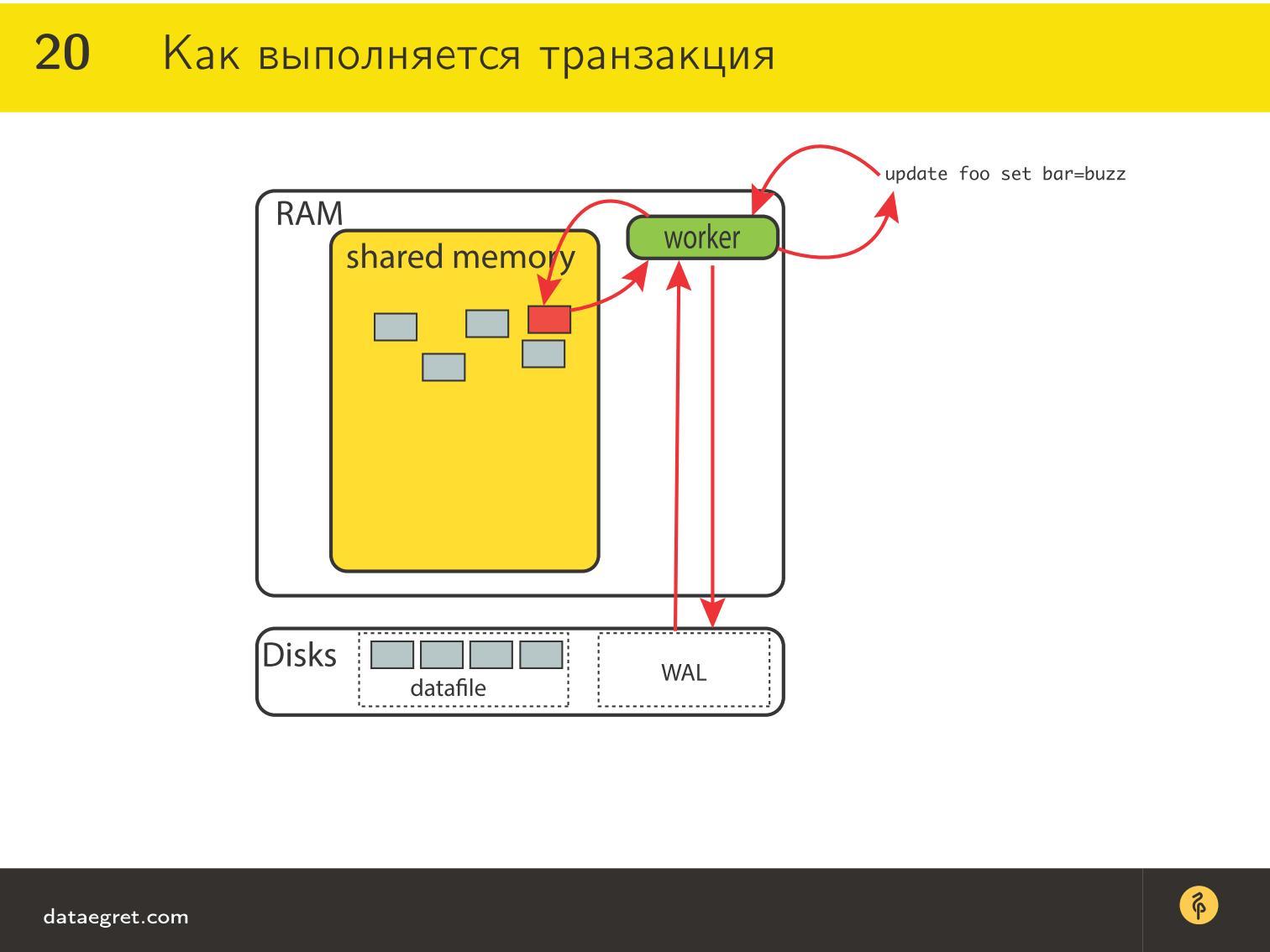 xy
xy
- В MySQL он внутри InnoDB,
- В PostgreSQL это отдельная директория, которая наконец в версии 10 стала называться WAL вместо PGX-Log;
- В Oracle это называется Redo Log;
- В DB2 — WAL.
Требования к проектированию БД
О видах и особенностях реляционных БД мы уже поговорили. Теперь давайте подробнее обсудим сложности их проектирования. В данном случае этот процесс начинается с постановки задач, исходя из нужных требований, особенностей использования, недостатков либо достоинств той либо иной системы управления. В случае с СУБД MySQL необходимо правильно составить общую структуру.
Требования обычно следующие:
1. База данных должна быть относительно простой в плане обработки информации.
2. Она должна быть максимально компактной и неизбыточной настолько, насколько это возможно без ущерба для функциональности.
Возможны и другие требования, причём нередко они противоречат друг другу
Именно поэтому важно найти оптимальный баланс с точки зрения архитектуры, учитывая назначение конечного продукта
Так как проектирование — важнейший процесс, им занимается проектировщик. Обычно к работе привлекают профессиональных администраторов серверов либо архитекторов БД, имеющих большой практический опыт. Нужно четко понимать, что проектируется и какие результаты должны получиться на выходе. Это бывает непросто, так как, если речь идёт о серьёзных проектах, готовая структура может включать в себя десятки и сотни таблиц, которые бывают связаны друг с другом как простыми, так и замысловатыми способами.
Результат проектирования — диаграмма или схема. Это подробное схематическое описание, в котором указываются, какие данные будут храниться, сколько столбцов в таблице, тип столбцов в таблице, как связаны таблицы между собой и многое другое. При правильном и грамотном проектировании система будет работать стабильно и без сбоев. В обратном случае ожидайте проблем, так как нет ничего хуже, чем ошибиться на этапе построения архитектуры проекта.
Если вы хотите овладеть базами данных на высоком профессиональном уровне, записывайтесь на соответствующий курс в OTUS. Практикующие эксперты научат вас особенностям управления БД и тому, как эффективно взаимодействовать с любой реляционной СУБД, используя для этого язык структурированных запросов SQL.
MySQL
Самый именитый представитель нашего обзора программ для разработки базы данных. Бесплатная база данных MySQL существует с 1995 года и теперь принадлежит компании Oracle. СУБД имеет открытый исходный код. Также существует несколько платных версий, которые предлагают дополнительные функции, такие как гео-репликация кластера и автоматическое масштабирование.
Поскольку MySQL является отраслевым стандартом, она совместима практически со всеми операционными системами и написана на языках C и C ++. Это решение является отличным вариантом для международных пользователей. Сервер СУБД может выводить клиентам сообщения об ошибках на нескольких языках.
Достоинства
- Проверка на стороне сервера;
- Может использоваться как локальная база данных;
- Гибкая система привилегий и паролей;
- Безопасное шифрование всего трафика паролей;
- Библиотека, которая может быть встроена в автономные приложения;
- Предоставляет сервер в качестве отдельной программы для сетевого окружения клиент/сервер.
Недостатки практической разработки и администрирования баз данных MySQL Приобретена компанией Oracle:
- пользователи полагают, что MySQL больше не подпадает под категорию бесплатного и открытого программного обеспечения;
- больше не поддерживается сообществом;
- пользователи не могут исправлять ошибки и патчи;
- проигрывает другим решениям из-за медленных обновлений.
Ключи и индексы
В реляционных базах данных таблицы связываются друг с другом посредством совпадающих значений ключевых полей. Ключевым полем может быть практически любое поле в таблице. Ключ может быть первичным или внешним. Первичный ключ однозначно определяет запись в таблице, в то время как внешний ключ используется для связи с первичным ключом другой таблицы. Одними из основных требований, предъявляемым к системам управления базами данных, являются возможность представления данных в определённом, отличном от физического, порядке и возможность быстрого поиска определенной записи. Эффективным средством решения этих задач является использование индексов. Индекс представляет собой таблицу, которая содержит ключевые значения для каждой записи в таблице данных, записанные в порядке, требуемом для пользователя. Ключевые значения определяются на основе одного или нескольких полей таблицы. Кроме того, индекс содержит уникальные ссылки на соответствующие записи в таблице.
SQLite

Провозгласившая себя самой распространенной СУБД в мире, SQLite зародилась в 2000 году и используется Apple, , Microsoft и . Каждый релиз тщательно тестируется. Разработчики SQLite предоставляют пользователям списки ошибок, а также хронологию изменений кода каждой версии.
Достоинства
- Нет отдельного серверного процесса;
- Формат файла – кросс-платформенный;
- Транзакции соответствуют требованиям ACID;
- Доступна профессиональная поддержка.
Недостатки
Не рекомендуется для:
- клиент-серверных приложений;
- крупномасштабных сайтов;
- больших наборов данных;
- программ с высокой степенью многопоточности.
Что такое базы данных (БД) и зачем они нужны
База данных (БД) — это программа, которая позволяет хранить и обрабатывать информацию в структурированном виде.
БД это отдельная независимая программа, которая не входит в состав языка программирования. В базе данных можно сохранять любую информацию, чтобы позже получать к ней доступ.
Пример использования
Базы данных нужны для хранения информации. Чтобы получить полное понимание необходимости использования БД в современном веб-программировании, необходимо ответить на три вопроса:
- Какую информацию и зачем мы храним?
- В каком виде и как надо хранить эту информацию?
- Как и каким способом можно получить доступ к этой информации?
Предположим, вы решили сделать сайт, где каждый пользователь может вести личный дневник наблюдения за погодой в своем городе.
Такой сайт должен иметь как минимум одну форму ввода со следующими полями: город, дата, температура, облачность, погодное явление, и так далее.
Каждый день наблюдатель записывает показания погоды в эту форму, чтобы когда-нибудь в будущем вернуться на сайт и посмотреть, какая была погода месяц или даже год назад.
Из этого примера следует, что программист каким-то образом должен сохранять данные из формы для дальнейшего использования.
Кроме обычного просмотра дневника погоды за месяц в виде таблицы, можно сделать и более сложный проект.
Например, чтобы электронный дневник чем-то качественно отличался от своего бумажного аналога, будет неплохо добавить туда возможности для простого анализа: показать какой день был самым холодным в ноябре или какой продолжительности была самая длинная серия пасмурных дней.
Получается, что данные надо не просто как-то хранить, но и иметь возможность их обрабатывать и анализировать.
Именно для этих целей и существуют базы данных.
Типы данных в базах
В Access можно определить следующие типы полей:
- Текстовый – текстовая строка; максимальная длина задаётся параметром «размер», но не может быть больше 255
- Поле МЕМО – текст длиной до 65535 символов
- Числовой – в параметре «Размер поля» можно задать поле: байт, целое, дейсвительное и т.п.
- Дата/время – поле, хранящее данные о времени.
- Денежный – специальный формат для финансовых нужд, по сути являющийся числовым
- Счётчик – автоинкрементное поле. При добавлении новой записи внутренний счётчик таблицы увеличивается на единицу и записывается в данное поле новой записи. Таким образом, значения этого поля гарантированно различны для разных записей. Тип предназначен для ключевого поля
- Логический – да или нет, правда или ложь, включен или выключен
- Объект OLE– в этом поле могут храниться документы, картинки, звуки и т.п. Поле является частным случаем BLOB– полей ( Binary Large Object ), встречающихся в различных базах данных
- Гиперссылка – используется для хранения ссылок на ресурсы Интернета. Встречается не во всех форматах баз данных. К примеру, такого типа нет в dBaseи Paradox
- Подстановка
Типы данных в таблицах Access
- Текстовый
- Поле МЕМО
- Числовой
- Дата\время
- Денежный
- Счётчик
- Логический
- Объект OLE
- Гиперссылка
Не надо забывать про индексы. Связывать таблицы. Связь с обеспечением целостности контролирует каскадное удаление и модификацию данных.
Монопольный доступ к БД нужен для того, чтобы производить в ней фундаментальные изменения.
Нормализация базы данных
После предварительного проектирования базы данных можно применить правила нормализации, чтобы убедиться, что таблицы структурированы правильно.
В то же время не все базы данных необходимо нормализовать. В целом, базы с обработкой транзакций в реальном времени (OLTP), должны быть нормализованы.
Базы данных с интерактивной аналитической обработкой (OLAP), позволяющие проще и быстрее выполнять анализ данных, могут быть более эффективными с определенной степенью денормализации. Основным критерием здесь является скорость вычислений. Каждая форма или уровень нормализации включает правила, связанные с нижними формами.
Первая форма нормализации
Первая форма нормализации (сокращенно 1NF) гласит, что во время логического проектирования базы данных каждая ячейка в таблице может иметь только одно значение, а не список значений. Поэтому таблица, подобная той, которая приведена ниже, не соответствует 1NF:

Возможно, у вас возникнет желание обойти это ограничение, разделив данные на дополнительные столбцы. Но это также противоречит правилам: таблица с группами повторяющихся или тесно связанных атрибутов не соответствует первой форме нормализации. Например, приведенная ниже таблица не соответствует 1NF:

Вместо этого во время физического проектирования базы данных разделите данные на несколько таблиц или записей, пока каждая ячейка не будет содержать только одно значение, и дополнительных столбцов не будет. Такие данные считаются разбитыми до наименьшего полезного размера. В приведенной выше таблице можно создать дополнительную таблицу «Реквизиты продаж», которая будет соответствовать конкретным продуктам с продажами. «Продажи» будут иметь связь 1:M с «Реквизитами продаж».
Вторая форма нормализации
Вторая форма нормализации (2NF) предусматривает, что каждый из атрибутов должен полностью зависеть от первичного ключа. Каждый атрибут должен напрямую зависеть от всего первичного ключа, а не косвенно через другой атрибут.
Например, атрибут «возраст» зависит от «дня рождения», который, в свою очередь, зависит от «ID студента», имеет частичную функциональную зависимость. Таблица, содержащая эти атрибуты, не будет соответствовать второй форме нормализации.
Кроме этого таблица с первичным ключом, состоящим из нескольких полей, нарушает вторую форму нормализации, если одно или несколько полей не зависят от каждой части ключа.
Таким образом, таблица с этими полями не будет соответствовать второй форме нормализации, поскольку атрибут «название товара» зависит от идентификатора продукта, но не от номера заказа:
- Номер заказа (первичный ключ);
- ID товара (первичный ключ);
- Название товара.
Третья форма нормализации
Третья форма нормализации (3NF): каждый не ключевой столбец должен быть независим от любого другого столбца. Если при проектировании реляционной базы данных изменение значения в одном не ключевом столбце вызывает изменение другого значения, эта таблица не соответствует третьей форме нормализации.
В соответствии с 3NF, нельзя хранить в таблице любые производные данные, такие как столбец «Налог», который в приведенном ниже примере, напрямую зависит от общей стоимости заказа:

В свое время были предложены дополнительные формы нормализации. В том числе форма нормализации Бойса-Кодда, четвертая-шестая формы и нормализации доменного ключа, но первые три являются наиболее распространенными.
Многомерные данные
Некоторым пользователям может потребоваться доступ к нескольким разрезам одного типа данных, особенно в базах данных OLAP. Например, им может потребоваться узнать продажи по клиенту, стране и месяцу. В этой ситуации лучше создать центральную таблицу, на которую могут ссылаться таблицы клиентов, стран и месяцев. Например:

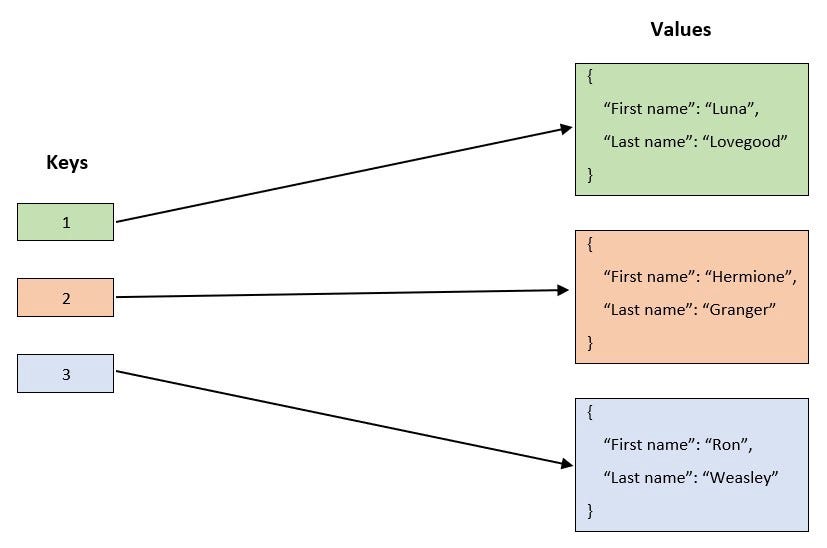
Ключ-значение
В этих БД запросы только на основе ключа — вы запрашиваете ключ и получаете его значение.
Такие БД не поддерживают запросы между различными значениями записей, вроде такого: выбрать все записи, где город — Нью-Йорк.Полезное свойство этих БД — поле времени жизни (Time-to-Live, TTL), в котором можно задать отдельно для каждой записи и состояния, когда их нужно удалить из БД.
Достоинства
Это очень быстрые БД. Во-первых, потому что используют уникальные ключи, во-вторых, потому что большинство БД типа ключ-значение хранят данные в оперативной памяти, что обеспечивает быстрый доступ к данным.
Недостатки
Необходимо определять уникальные ключи, хорошие идентификаторы, основанные на заранее известных вам данных. Зачастую они дороже, чем другие типы баз данных, так как используют оперативную память.
Использование
В основном используются для кэширования, потому что быстрые и не требуют сложных запросов. Поле времени жизни для кэширования также очень полезно. Такие БД могут использоваться для любых данных, которые требуют быстрых запросов и соответствуют формату ключ-значение. Примеры таких баз:
- Redis
- Memcached
Рейтинг
Итак, рейтинг 10 наиболее популярных баз данных, согласно ресурсу DB-Engines, выглядит следующим образом:
- Oracle;
- MySQL;
- Microsoft SQL Server;
- PostgreSQL;
- MongoDB;
- DB2;
- Cassandra;
- Microsoft Access;
- Redis;
- SQLite.
Итого, 7 из 10 представителей рейтинга – реляционные базы данных, а также по одному экземпляру документоориентированной БД (MongoDB), с распределёнными значениями (Cassandra) и использующей подход «ключ-значение» (Redis). Таким образом, на сегодняшний день доминирование реляционных баз данных неоспоримо, но что будет завтра?
Для ответа на этот вопрос обратимся на этом же ресурсе к разделу тренды. Если брать отметки времени в более чем в 2 или 4 года, то наибольший рост демонстрирует подход с использованием теории графов. В то же время за последний год максимальный рост популярности продемонстрировали БД на основе временных данных. Это относительно новый подход, он также считается NoSQL, преимущество сводится к созданию структуры на основе дат или временных диапазонов. На данный момент наиболее популярным представителем Time Series БД является InfluxDB.
А какие базы данных используете вы? И какая на ваш взгляд наиболее перспективная NoSQL БД?
Итоги
Важное замечание – не пытайтесь сразу все задачи решить в рамках одной СУБД. Это более чем нормально иметь несколько разных типов СУБД
Так же, не пытайтесь сразу определиться с производителем СУБД, или связать свою жизнь с одним конкретным брендом.
При выборе типа СУБД следует, прежде всего, исходить из типа решаемых задач, типов обрабатываемых данных, перспектив роста и масштабирования.
Обращайте так же внимание на популярность и наличие широкого круга разработчиков и средств разработки – это даст вам возможность, при необходимости, найти ответ на возникший вопрос быстро. В данной статье я намеренно не делаю акцент на выбор между облачными и on-premise решениями — эта тема одной из следующих статей
В данной статье я намеренно не делаю акцент на выбор между облачными и on-premise решениями — эта тема одной из следующих статей.
Итак, в таблице представленной ниже, кратко собрано то, что описано выше в статье.
|
Тип СУБД |
Когда выбирать |
Примеры популярных СУБД |
|
Реляционные |
Нужна транзакционность; высокая нормализация; большая доля операций на вставку |
Oracle, MySQL, Microsoft SQL Server, PostgreSQL |
|
Ключ-значение |
Задачи кэширования и брокеры сообщений |
Redis, Memcached |
|
Документные |
Для хранения объектов в одной сущности, но с разной структурой; хранение структур на основе JSON |
CouchDB, MongoDB, Amazon DocumentDB |
|
Графовые |
Задачи подобные социальным сетям; системы оценок и рекомендаций |
Neo4j, Amazon Neptune, InfiniteGraph, InfoGrid |
|
Колоночные |
Хранилища данных; выборки со сложными аналитическими вычислениями; количество строк в таблице превышает сотни миллионов |
Vertica, ClickHouse, Google BigTable, Sybase \ SAP IQ, InfoBright, Cassandra |
Надеюсь данная статья оказалась полезной.
В следующих статьях посмотрим на выбор между облачными и on-premise СУБД, платными и бесплатными, и многое другое.




