30 лучших курсов по sql: бесплатное и платное обучение с нуля
Содержание:
- Оператор join: объединение записей из двух таблиц
- Transact-SQL справочник для начинающих — описание справочника
- Профайлы
- Создание базы данных на T-SQL (CREATE DATABASE)
- Лучшие проекты SQL для начинающих
- Путь изучения SQL
- Что нужно, для того чтобы создать базу данных в Microsoft SQL Server?
- Модель работы с базой данных
- Соединения (джойны)
- 5. Агрегирование
- 6. Подзапросы
- Оператор insert into: добавление записи в таблицу
- Системные представления
- Курсы и учебные пособия по SQL
- Кто работает с SQL?
- MySQL
- IDE для SQL
- SQL Учебник
- Операции записи
Оператор join: объединение записей из двух таблиц
В нашей таблице для хранения погодного дневника город сохраняется как идентификатор, поэтому при обычном чтении данных из этой таблицы вместо названия города стоит непонятное число. Чтобы подставить на место числа действительное значение, а конкретнее — название города, в SQL существуют операторы объединения — .
Поддержка операторов объединения и позволяет базе данных называться реляционной.
Поменяем запрос на показ погодных записей, чтобы он объединял две таблицы, а в поле города показывалось его название, а не идентификатор:
Важно усвоить три самых главных момента:
- При чтении из объединённых таблиц, в перечислении полей после SELECT нужно явно указывать в поле имени также имя таблицы, с которой производится объединение.
- Всегда есть основная таблица (тб1), из которой читается большинство полей и присоединяемая (тб2), имя которой определяется после оператора JOIN.
- Помимо указания имени второй таблицы, обязательно следует указать условие, по которому будет происходить объединение. В этом примере таким условием будет соответствие идентификатора города из тб1 (weather_log.city_id) первичному ключу города из тб2 (cities.id).
Transact-SQL справочник для начинающих — описание справочника
Данный справочник будет выглядеть следующим образом, сначала я приведу небольшое оглавление с навигацией, затем начнется сам справочник, по каждому пункту будут комментарии, пояснения и примеры. Также, если мы уже подробно рассматривали или использовали где-либо в материалах на нашем сайте тот или иной объект или действие, я, конечно же, буду ставить ссылки, для того чтобы Вы могли посмотреть подробные примеры или как использовать то или иное действие на практике.
Так как охватить абсолютно все просто невозможно, поэтому не удивляйтесь, если Вы что-то здесь не обнаружили. Еще раз повторю, что данный справочник создан для начинающих программистов на Transact-SQL, а также для простых админов, которым периодически требуется выгружать какие-то данные с SQL сервера.
Профайлы
Профайлы содержат информацию, не оказывающую влияния на логику функционирования системы на базе 1С:Предприятия 8. Такая информация не является необходимой, но ее сохранение может, например, повысить комфортность работы пользователя. В профайлах можно хранить формат и расположение окон и диалогов, настройки шрифтов, цветов, отборов и т. п. Потеря такой информации не может привести к нарушению работоспособности системы.
Подробнее назначение профайлов и хранение настроек пользователя описаны в разделе «Сохранение параметров настроек пользователя между сеансами«.
Профайлы различаются по принадлежности хранимой в них информации. Виды профайлов, используемых в 1С:Предприятии 8, представлены в таблице:
|
Принадлежность данных |
Примеры хранимых данных |
Расположение |
|---|---|---|
|
Компьютер клиента |
— Открыто ли табло.- Настройки текстового редактора. |
<Данные приложений пользователя>/1C/1cv82/1Cv8.pfl, например:C:/Documents and Settings/User/Application Data/1C/1cv82/1Cv8.pfl |
|
Компьютер клиента |
— Файлы клиентских настроек, информация о резервных кластерах и другая служебная информация |
Например C:\Documents and Settings\All Users\Application Data\1C\1Cv82\1cv8conn.pfl |
|
Информационная база |
— Режим аутентификации при старте 1С:Предприятия из отладчика.- Каталог последнего сохранения хранилища конфигурации в файл. |
Таблица files базы данных, в которой размешена информационная база. |
|
Информационная база и пользователь |
— Настройки динамических списков.- Настройки отборов по журналу регистрации. |
Таблица files базы данных, в которой размешена информационная база. |
|
Компьютер и информационная база |
— Настройки сравнения файлов конфигураций.- Настройки глобального поиска по текстам конфигурации. |
<Данные приложений пользователя>/1C/1cv82/<Идентификатор информационной базы>/1Cv8.pfl, например:C:/Documents and Settings/User/Application Data/1C/1cv82/ 4129dbdb-b495-41cb-99ea-ef315060a03e/1Cv8.pfl |
|
Компьютер, информационная база и пользователь |
— Расположение окна синтакс — помощника.- Список переменных для быстрого просмотра в отладчике. |
<Данные приложений пользователя>/1C/1cv82/<Идентификатор информационной базы>/<Идентификатор пользователя>/1Cv8.pfl, например:C:/Documents and Settings/User/Application Data/1C/1cv82/ 4129dbdb-b495-41cb-99ea-ef315060a03e/ E8D87DA4-A087-4145-95E7-D613E0F7CB64/1Cv8.pfl |
|
1С:Предприятие 8 в режиме Конфигуратора |
— Расположение окон конфигуратора.- Цвета редактора модулей в конфигураторе. |
<Данные приложений пользователя>/1C/1cv82/1Cv8cmn.pfl, например:C:/Documents and Settings/User/Application Data/1C/1cv82/1Cv8cmn.pfl |
|
1С:Предприятие 8 в режиме Конфигуратор и Предприятие |
— Расположение некоторых окон (подсказка, отладчик)- Параменты групповой разработки- Параметры использования внешних компонент) |
<Данные приложений пользователя>/1C/1cv82/<Идентификатор информационной базы>/<Идентификатор пользователя>/1Cv8cmn.pfl, например:C:/Documents and Settings/User/Application Data/1C/1cv82/ 4129dbdb-b495-41cb-99ea-ef315060a03e/ E8D87DA4-A087-4145-95E7-D613E0F7CB64/1Cv8cmn.pfl |
|
Диалог запуска 1С:Предприятия 8 |
— Размеры и расположение диалога запуска.- Настройки диалогов установки параметров информационных баз. |
<Данные приложений пользователя>/1C/1cv82/1Cv8strt.pfl, например:C:/Documents and Settings/User/Application Data/1C/1cv82/1Cv8strt.pfl |
Данные из профайлов читаются при старте 1С:Предприятия 8 и записываются при его штатном завершении. По этой причине в случае нештатного завершения некоторые пользовательские настройки могут не сохраниться.
Создание базы данных на T-SQL (CREATE DATABASE)
Процесс создания базы данных на языке T-SQL, наверное, еще проще, так как для того чтобы создать БД с настройками по умолчанию (как мы это сделали чуть выше), необходимо написать всего три слова в редакторе SQL запросов – инструкцию CREATE DATABASE и название БД.
Сначала открываем редактор SQL запросов, для этого щелкаем на кнопку «Создать запрос» на панели инструментов.
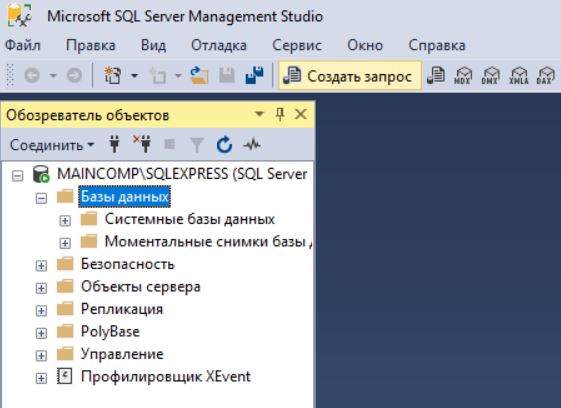
Затем вводим следующую инструкцию, и запускаем ее на выполнение, кнопка «Выполнить».
CREATE DATABASE TestDB;
Где CREATE – это команда языка T-SQL для создания объектов на SQL сервере, командой DATABASE мы указываем, что хотим создать базу данных, а TestDB — это имя новой базы данных.
Конечно же, на данном этапе многие не знают ни Microsoft SQL Server, ни языка T-SQL, многие, наверное, как раз и создают базу данных для того, чтобы начать знакомиться с этой СУБД и начать изучать язык SQL. Поэтому чтобы Вам легче было это делать, советую почитать книгу «SQL код» – это самоучитель по языку SQL для начинающих программистов, которую написал я, и в которой я подробно, и в то же время простым языком, рассказываю о языке SQL.
С помощью инструкции CREATE DATABASE можно задать абсолютно все параметры, которые отображались у нас в графическом интерфейсе SSMS. Например, если бы мы заменили вышеуказанную инструкцию следующей, то у нас база данных создалась бы в каталоге DataBases на диске D.
--Создание БД TestDB
CREATE DATABASE TestDB
ON PRIMARY --Первичный файл
(
NAME = N'TestDB', --Логическое имя файла БД
FILENAME = N'D:\DataBases\TestDB.mdf' --Имя и местоположение файла БД
)
LOG ON --Явно указываем файлы журналов
(
NAME = N'TestDB_log', --Логическое имя файла журнала
FILENAME = N'D:\DataBases\TestDB_log.ldf' --Имя и местоположение файла журнала
)
GO

Лучшие проекты SQL для начинающих
Лучший способ изучить любую концепцию программирования — это начать работу с проектами, а не просто грабить теорию и синтаксис. Проекты помогут вам найти решения проблем, с которыми вы столкнетесь в реальных ситуациях, они дадут вам более глубокое понимание тем, помогут вам применить свои теоретические знания для создания потрясающих продуктов и, очевидно, улучшат ваше резюме. и портфолио.
Проекты — это проверка ваших навыков. Чтобы начать как новичок, вам следует начать с небольших проектов с меньшим количеством функций и модулей, чтобы при появлении ошибок вы не сдавались. После того, как вам нужно создать несколько небольших проектов, вы можете добавить к ним дополнительные функции или создать новый сложный проект в целом.
Вот список лучших проектов SQL для начинающих.
1. Система управления библиотекой
Вы можете создать простое веб-приложение с подключением к базе данных SQL, где вы сохранили подробную информацию о книгах, такую как автор, цена, публикации, контент, жанр и т. Д. Вы можете создать портал, где студенты, исследователи и преподаватели могут использовать свои удостоверения личности для регистрации книг на определенный период времени, наложения штрафов, если книги не возвращаются в установленные сроки, создание платежного портала, создание другой базы данных для хранения данных профиля пользователей и т. д.
2. Приложение для розничной торговли через Интернет
Вы можете создать другое веб-приложение, которое позволяет пользователям создавать профили, отображать список товаров вместе с данными о ценах, поставщиках и т. Д., Позволять им добавлять продукты на свои карты, добавлять информацию о кредитных картах, совершать покупки, отслеживать доставку и т. Д. .
3. Система бронирования железнодорожных билетов.
Вы можете создать платформу, которая позволяет пользователям бронировать железнодорожные билеты и имеет такие функции, как вход в систему, функция оплаты, отображение списка поездов между пунктами и их расписанием, а также количество доступных мест, маршруты поездов и т. Д.
4. Система управления больницей
Вы можете сотрудничать с клиникой или создать отдельное приложение, которое позволяет пациентам и врачам взаимодействовать и консультироваться друг с другом посредством видеоконференцсвязи, назначать лекарства, оплачивать сборы, управлять приемами, планировать звонки, отображать список лекарств и их информацию и т. Д.
5. Система управления человеческими ресурсами
Вы можете создать другое приложение, которое позволит небольшим компаниям и организациям управлять своими человеческими ресурсами. Он отслеживает их сотрудников и их производительность, такие детали, как шкала заработной платы, отдел, обязанности, сроки, назначенные проекты и другую важную информацию.
Путь изучения SQL
Предыдущие знания концепций управления базами данных и реляционных баз данных могут быть полезны, однако вам не обязательно знать их, чтобы начать работу с SQL. Вот полный план действий, который поможет вам начать работу с SQL.
- Начните с изучения основных концепций управления базами данных, таких как типы баз данных, транзакции, реляционные модели, методы нормализации, таблицы, различные ключи в схемах и т. Д.
- После того, как вы изучите основы управления базами данных, вы можете продолжить изучение основных тем и концепций SQL. Некоторые из них —
- Синтаксис SQL, типы данных, переменные и т. Д.
- Команды Select, Where, And, Or, Not, Order By.
- Команды вставки, обновления, удаления.
- Мин, Макс, Счетчик, Среднее, Сумма, команды.
- Like, In, Between, Top, Group By, команды.
- Такие соединения, как внутренние, внешние, левые, правые, полные, собственные.
- SQL, имеющий, существует, любой, все, регистр, нулевые функции и т. Д.
- Команды, относящиеся к базе данных SQL, такие как создание, удаление, резервное копирование и т. Д.
- Команды таблицы SQL, такие как создание, изменение, обновление, удаление и т. Д.
- Ограничения SQL, такие как ненулевое значение, уникальность, проверка, значение по умолчанию, автоинкремент и т. Д.
- Ключи SQL, такие как первичный, уникальный, внешний и т. Д.
- Расширенные концепции SQL, такие как представления, триггеры, функции, PL / SQL, внедрение, хостинг и т. Д.
- После того, как вы приобрели знания по всем вышеперечисленным темам, вы можете приступить к созданию баз данных и таблиц и выполнению команд, которые вы изучили в теории.
Если вы будете следовать этой дорожной карте, вы сможете изучить концепции баз данных, а также команды SQL, которые определенно помогут вам получить хорошее представление обо всей концепции управления базами данных и помогут вам получить преимущество над другими кандидатами для обеспечения безопасности хорошая карьера в СУБД.
Что нужно, для того чтобы создать базу данных в Microsoft SQL Server?
В данном разделе я представлю своего рода этапы создания базы данных в Microsoft SQL Server, т.е. это как раз то, что Вы должны знать и что у Вас должно быть, для того чтобы создать базу данных:
- У Вас должна быть установлена СУБД Microsoft SQL Server. Для обучения идеально подходит бесплатная редакция Microsoft SQL Server Express. Если Вы еще не установили SQL сервер, то вот подробная видео-инструкция, там я показываю, как установить Microsoft SQL Server 2017 в редакции Express;
- У Вас должна быть установлена среда SQL Server Management Studio (SSMS). SSMS – это основной инструмент, с помощью которого осуществляется разработка баз данных в Microsoft SQL Server. Эта среда бесплатная, если ее у Вас нет, то в вышеупомянутой видео-инструкции я также показываю и установку этой среды;
- Спроектировать базу данных. Перед тем как переходить к созданию базы данных, Вы должны ее спроектировать, т.е. определить все сущности, которые Вы будете хранить, определить характеристики, которыми они будут обладать, а также определить все правила и ограничения, применяемые к данным, в процессе их добавления, хранения и изменения. Иными словами, Вы должны определиться со структурой БД, какие таблицы она будет содержать, какие отношения будут между таблицами, какие столбцы будет содержать каждая из таблиц. В нашем случае, т.е. при обучении, этот этап будет скорей формальным, так как правильно спроектировать БД начинающий не сможет. Но начинающий должен знать, что переходить к созданию базы данных без предварительного проектирования нельзя, так как реализовать БД, не имея четкого представления, как эта БД должна выглядеть в конечном итоге, скорей всего не получится;
- Создать пустую базу данных. В среде SQL Server Management Studio создать базу данных можно двумя способами: первый — с помощью графического интерфейса, второй — с помощью языка T-SQL;
- Создать таблицы в базе данных. К этому этапу у Вас уже будет база данных, но она будет пустая, так как в ней еще нет никаких таблиц. На этом этапе Вам нужно будет создать таблицы и соответствующие ограничения;
- Наполнить БД данными. В базе данных уже есть таблицы, но они пусты, поэтому сейчас уже можно переходить к добавлению данных в таблицы;
- Создать другие объекты базы данных. У Вас уже есть и база данных, и таблицы, и данные, поэтому можно разрабатывать другие объекты БД, такие как: представления, функции, процедуры, триггеры, с помощью которых реализуется бизнес-правила и логика приложения.
Вот это общий план создания базы данных, который Вы должны знать, перед тем как начинать свое знакомство с Microsoft SQL Server и языком T-SQL.
В этой статье мы рассмотрим этап 4, это создание пустой базы данных, будут рассмотрены оба способа создания базы данных: и с помощью графического интерфейса, и с помощью языка T-SQL. Первые три этапа Вы должны уже сделать, т.е. у Вас уже есть установленный SQL Server и среда Management Studio, и примерная структура базы данных, которую Вы хотите реализовать, как я уже сказал, на этапе обучения этот пункт можно пропустить, а в следующих материалах я покажу, как создавать таблицы в Microsoft SQL Server пусть с простой, но с более-менее реальной структурой.
Модель работы с базой данных
Модель базы данных «1С:Предприятия 8» имеет ряд особенностей, отличающих ее от классических моделей систем управления базами данных (например, основанных на реляционных таблицах), с которыми имеют дело разработчики в универсальных системах.
Основное отличие заключается в том, что разработчик «1С:Предприятия 8» не обращается к базе данных напрямую. Непосредственно он работает с платформой «1С:Предприятия 8». При этом он может:
- описывать структуры данных в конфигураторе,
- манипулировать данными с помощью объектов встроенного языка,
- составлять запросы к данным, используя язык запросов.
Платформа «1С:Предприятия 8» обеспечивает операции исполнения запросов, описания структур данных и манипулирования данными, транслируя их в соответствующие команды. Это могут быть команды системы управления базами данных, в случае клиент-серверного варианта работы, или команды собственного движка базы данных для файлового варианта.
Соединения (джойны)
Теперь мы хотим увидеть названия (не обязательно уникальные) всех книг Дэна Брауна, которые были взяты из библиотеки, и когда эти книги нужно вернуть:
Результат:
| Title | Return Date |
|---|---|
| The Lost Symbol | 2016-03-23 00:00:00 |
| Inferno | 2016-04-13 00:00:00 |
| The Lost Symbol | 2016-04-19 00:00:00 |
По большей части запрос похож на предыдущий за исключением секции . Это означает, что мы запрашиваем данные из другой таблицы. Мы не обращаемся ни к таблице “books”, ни к таблице “borrowings”. Вместо этого мы обращаемся к новой таблице, которая создалась соединением этих двух таблиц.
— это, считай, новая таблица, которая была сформирована комбинированием всех записей из таблиц «books» и «borrowings», в которых значения совпадают. Результатом такого слияния будет:

А потом мы делаем запрос к этой таблице так же, как в примере выше. Это значит, что при соединении таблиц нужно заботиться только о том, как провести это соединение. А потом запрос становится таким же понятным, как в случае с «простым запросом» из пункта 3.
Давайте попробуем чуть более сложное соединение с двумя таблицами.
Теперь мы хотим получить имена и фамилии людей, которые взяли из библиотеки книги автора “Dan Brown”.
На этот раз давайте пойдем снизу вверх:
Шаг Step 1 — откуда берем данные? Чтобы получить нужный нам результат, нужно соединить таблицы “member” и “books” с таблицей “borrowings”. Секция JOIN будет выглядеть так:
Шаг 2 — какие данные показываем? Нас интересуют только те данные, где автор книги — “Dan Brown”
Шаг 3 — как показываем данные? Теперь, когда данные получены, нужно просто вывести имя и фамилию тех, кто взял книги:
Супер! Осталось лишь объединить три составные части и сделать нужный нам запрос:
Что даст нам:
| First Name | Last Name |
|---|---|
| Mike | Willis |
| Ellen | Horton |
| Ellen | Horton |
Отлично! Но имена повторяются (они не уникальны). Мы скоро это исправим.
5. Агрегирование
Грубо говоря, агрегирования нужны для конвертации нескольких строк в одну. При этом, во время агрегирования для разных колонок используется разная логика.
Давайте продолжим наш пример, в котором появляются повторяющиеся имена. Видно, что Ellen Horton взяла больше одной книги, но это не самый лучший способ показать эту информацию. Можно сделать другой запрос:
Что даст нам нужный результат:
| First Name | Last Name | Number of books borrowed |
|---|---|---|
| Mike | Willis | 1 |
| Ellen | Horton | 2 |
Почти все агрегации идут вместе с выражением . Эта штука превращает таблицу, которую можно было бы получить запросом, в группы таблиц. Каждая группа соответствует уникальному значению (или группе значений) колонки, которую мы указали в . В нашем примере мы конвертируем результат из прошлого упражнения в группу строк. Мы также проводим агрегирование с , которая конвертирует несколько строк в целое значение (в нашем случае это количество строк). Потом это значение приписывается каждой группе.
Каждая строка в результате представляет собой результат агрегирования каждой группы.
Можно прийти к логическому выводу, что все поля в результате должны быть или указаны в , или по ним должно производиться агрегирование. Потому что все другие поля могут отличаться друг от друга в разных строках, и если выбирать их ‘ом, то непонятно, какие из возможных значений нужно брать.
В примере выше функция обрабатывала все строки (так как мы считали количество строк). Другие функции вроде или обрабатывают только указанные строки. Например, если мы хотим узнать количество книг, написанных каждым автором, то нужен такой запрос:
Результат:
| author | sum |
|---|---|
| Robin Sharma | 4 |
| Dan Brown | 6 |
| John Green | 3 |
| Amish Tripathi | 2 |
Здесь функция обрабатывает только колонку и считает сумму всех значений в каждой группе.
6. Подзапросы

Подзапросы это обычные SQL-запросы, встроенные в более крупные запросы. Они делятся на три вида по типу возвращаемого результата.
Оператор insert into: добавление записи в таблицу
Начнём с добавления новых данных в таблицу. Для добавления записи используется следующий синтаксис:
В начале добавим город в таблицу городов:
При добавлении записи не обязательно указывать значения для всех полей. Многие из полей имеют значения по умолчанию, которые сами заполняются при сохранении.
Теперь создадим запись о погоде за сегодняшний день.
При определении таблицы weather_log мы решили ссылаться на город, путём записи в поле city_id идентификатора города из таблицы cities. Так как мы только что добавили новый город, ничего не мешает использовать его идентификатор в записи о погоде.
Идентификатором города будет первичный ключ, который также был определён в качестве первого поля таблицы. Нумерация этого поля начинается с единицы, значит первая добавленная запись имеет идентификатор . Зная это, запрос на добавление записи о погоде в Санкт-Петербурге за третье сентября 2017 года выглядит так:
Системные представления
В СУБД MS SQL Server есть таки системные объекты, которые могут предоставить иногда достаточно полезную информацию, например системные представления. Сейчас мы разберем парочку таких представлений. Обращаться к ним можно также как и к обычным представлениям (например, select * from название представление)
- sys.all_objects – содержит все объекты базы данных, включая такие параметры как: название, тип, дата создания и другие.
- sys.all_columns – возвращает все колонки таблиц с подробными их характеристиками.
- sys.all_views – возвращает все представления базы данных.
- sys.tables – все таблицы базы данных.
- sys.triggers – все триггеры базы данных.
- sys.databases – все базы данных на сервере.
- sys.sysprocesses – активные процессы, сессии в базе данных.
Их на самом деле очень много, поэтому все разобрать, не получиться. Если Вы хотите посмотреть, как их можно использовать на практике, то это мы уже делали, например, в материалах Как узнать активные сеансы пользователей в MS Sql 2008
Курсы и учебные пособия по SQL
Вот список онлайн-курсов и руководств, которые можно использовать для более подробного и практического изучения SQL. Использование этих курсов предоставит вам четкое руководство и путь, по которому нужно идти, а также некоторые проекты, которые улучшат ваше портфолио и помогут вам начать карьеру.
- Это один из самых подробных курсов, которые вам встретятся. Чтобы начать работу с этим курсом, вам не нужно иметь никаких предварительных знаний о базах данных, SQL или MySQL. Это для начинающих. Однако, если у вас есть предыдущий опыт программирования, вы сможете лучше понять концепции.
- Он проведет вас через подробные концепции с практическими проектами из реального мира, которые помогут вам лучше изучить концепции. Выполнив это руководство, вы сможете легко разрабатывать и создавать сложные базы данных.
Функции —
- Вы сможете создавать базы данных, использовать существующие и взаимодействовать с ними.
- Написание сложных SQL-запросов станет для вас легким делом.
- Вы создадите веб-приложение, используя MySQL и Node.
Ресурсы — 20 часов видео, 141 статья, 4 ресурса, сертификат.Цена — 8640 индийских рупий.Рейтинг — 4,6 по 51 134 оценкам.
2. Excel в MySQL: аналитические методы для бизнес-специализации
- Это специализация, предоставляемая Университетом Дьюка через платформу Coursera. Эта специализация состоит из 5 курсов. С помощью этого курса вы сможете превратить данные в ценную информацию и внести изменения в бизнес-процессы, анализируя ключевые показатели.
- Вы узнаете, как управлять большими данными с помощью Excel и SQL и проводить анализ таких больших объемов данных. Вы также изучите методы визуализации данных с использованием таблиц.
Функции —
- Вы сможете управлять большими данными с помощью MySQL и Excel.
- Вы научитесь визуализации данных с помощью Tableau.
- Освоите анализ данных.
- Вы будете создавать модели, прогнозы, проекты и выполнять анализ.
- Вы будете работать над реальным проектом.
Ресурс — 5 курсов, около 7 месяцев содержания.Цена — 3576 индийских рупий в месяц.Рейтинг — 4,6 по 18 019 оценок.
3. Введение в базы данных — Автор EdX
Это курс для самостоятельного изучения от EdX, который охватывает все темы, связанные с базами данных и SQL, от начального до продвинутого уровня. Его преподают и проводят отраслевые эксперты, и он поможет вам развить навыки программирования баз данных, чтобы расширить свои знания. Благодаря их лекциям вы узнаете, как создать базу данных SQL, вы изучите фундаментальные основы баз данных и т. Д.
Функции —
- Вы узнаете, как создавать SQL-запросы для выполнения операций CRUD в базе данных.
- Вы изучите такие концепции, как ссылочная целостность и ограничения целостности.
- Вы сможете рисовать модели данных, такие как ER, и применять SQL-запросы к схемам на основе этих моделей.
- Вы сможете изучить процедуры, триггеры, функции и т. Д.
- Вы поймете управление параллелизмом.
Ресурс — 4 месяца содержания по 6-8 часов в неделю. Статьи, видеоуроки, викторины.Цена — 33144 INR.Рейтинг — 4.5.
Кто работает с SQL?
Умение составлять SQL-запросы – важный навык для любого аналитика. Даже если в продукт уже интегрирована аналитическая система, бывают нетривиальные случаи, когда ее функционала недостаточно. Тогда специалисты и обращаются к SQL-запросам для работы с сырыми данными напрямую.
При работе с игрой или приложением бывают ситуации, когда другим членам команды нужно быстро получить какие-либо данные, но они не хотят обращаться к аналитику и отвлекать его от основной работы. Именно поэтому знание основ SQL пригодится разработчикам, продакт-менеджерам, геймдизайнерам и другим специалистам, работающим с данными.
MySQL
Существует множество различных реляционных СУБД. Самая известная СУБД — это Microsoft Access, входящая в состав офисного пакета приложений Microsoft Office.
Нет никаких препятствий для использования в качестве СУБД MS Access, но для задач веб-программирования гораздо лучше подходит альтернативная программа — MySQL.
В отличие от MS Access, MySQL абсолютно бесплатна, может работать на серверах с Linux, обладает гораздо большей производительностью и безопасностью, что делает её идеальным кандидатом на роль базы данных в веб-разработке.
Подавляющее большинство сайтов и приложений на PHP используют в качестве СУБД именно MySQL.
IDE для SQL
IDE или интегрированная среда разработки — это графический инструмент, который позволяет вам управлять всеми файлами, связанными с вашим приложением, и работать с такими инструментами, как полезные пакеты, функции автозаполнения, подсветка синтаксиса и т. Д., Чтобы улучшить ваш опыт разработки.
Хотя это правда, что вы можете создавать базы данных и таблицы и управлять ими прямо из самой командной строки, однако использование IDE всегда будет полезно для получения обзора всех баз данных, запросов, таблиц и других компонентов с высоты птичьего полета. Фактически, есть IDE, в которых есть раздел справки, в котором объясняются основные команды и их использование. Вы можете просто заполнить текстовые поля, выбрать различные предварительно отформатированные команды, нажать кнопку «ОК», и ваша работа будет выполнена. Это так просто. Более того, существуют IDE, которые также позволяют создавать резервные копии и восстанавливать базы данных и таблицы.
Следовательно, всегда разумно выбрать среду IDE, которая удовлетворяет ваши требования, прежде чем вы запачкаете руки SQL. Вот список лучших IDE, которые вы можете использовать для составления сложных SQL-запросов.
1. DBeaver
DBeaver— это среда разработки баз данных на основе Java с открытым исходным кодом. Его можно использовать бесплатно, и в нем есть мощные функции, которые обеспечат бесперебойную разработку.
Функции —
- Он позволяет экспортировать таблицы в файлы CSV и дамп, а также восстанавливать таблицы.
- Он позволяет сохранять наиболее часто используемые команды SQL. Вы можете загрузить эти сохраненные команды позже для других проектов.
- Также есть несколько цветовых тем.
- Он имеет инструмент управления сеансом.
- Он позволяет сравнивать две таблицы БД и их структуры.
- Выполненные запросы эстетично отображаются в отдельном интерфейсе.
- Он позволяет графически редактировать ячейки таблиц базы данных и фиксировать их.
2. PHPMyAdmin
PHPMyAdmin — это многофункциональный инструмент с открытым исходным кодом на основе HTML, который вы можете использовать для управления своими базами данных.
Функции —
- Это позволяет вам управлять пользователями и разрешениями.
- Он может поддерживать множество языков.
- Это позволяет создавать и редактировать запросы и столбцы результирующих строк.
- Вы можете сохранить свои запросы на более позднее время.
- IDE обладает широкими возможностями настройки для скрытия или отображения таблиц, комментариев, кодировок, временных меток и т. Д.
- Вы можете создавать резервные копии баз данных, конвертировать их в файлы CSV, импортировать дампы SQL и т. Д.
- Это позволяет вам управлять несколькими серверами.
- Вы можете использовать QBE для создания сложных запросов.
3. Adminer
Adminer можно использовать как альтернативу PHPMyAdmin. Он основан на веб-интерфейсе, поддерживает множество плагинов, позволяет работать с несколькими базами данных, такими как Oracle, SQLite и т. Д.
Особенности —
- Подключайтесь к базам данных, создавайте новые и т. Д.
- Вы можете распечатать схемы баз данных, даже если они связаны внешними ключами.
- Вы можете устанавливать и управлять разрешениями и правами пользователей и даже изменять их как администратор.
- Раздел справки неплохой, можно отображать переменные, у которых есть реферальные ссылки на документацию.
- Вы можете легко управлять разделами таблиц и событий.
SQL Учебник
SQL ГлавнаяSQL ВведениеSQL СинтаксисSQL SELECTSQL SELECT DISTINCTSQL WHERESQL AND, OR, NOTSQL ORDER BYSQL INSERT INTOSQL Значение NullSQL Инструкция UPDATESQL Инструкция DELETESQL SELECT TOPSQL MIN() и MAX()SQL COUNT(), AVG() и …SQL Оператор LIKESQL ПодстановочныйSQL Оператор INSQL Оператор BETWEENSQL ПсевдонимыSQL JOINSQL JOIN ВнутриSQL JOIN СлеваSQL JOIN СправаSQL JOIN ПолноеSQL JOIN СамSQL Оператор UNIONSQL GROUP BYSQL HAVINGSQL Оператор ExistsSQL Операторы Any, AllSQL SELECT INTOSQL INSERT INTO SELECTSQL Инструкция CASESQL Функции NULLSQL ХранимаяSQL Комментарии
Операции записи
Большинство операций записи в базе данных довольно просты, если сравнивать с более сложными операциями чтения.
7.1 Update
Синтаксис запроса семантически совпадает с запросом на чтение. Единственное отличие в том, что вместо выбора колонок ‘ом, мы задаем знаения ‘ом.
Если все книги Дэна Брауна потерялись, то нужно обнулить значение количества. Запрос для этого будет таким:
делает то же самое, что раньше: выбирает строки. Вместо , который использовался при чтении, мы теперь используем . Однако, теперь нужно указать не только имя колонки, но и новое значение для этой колонки в выбранных строках.
7.2 Delete
Запрос это просто запрос или без названий колонок. Серьезно. Как и в случае с и , блок остается таким же: он выбирает строки, которые нужно удалить. Операция удаления уничтожает всю строку, так что не имеет смысла указывать отдельные колонки. Так что, если мы решим не обнулять количество книг Дэна Брауна, а вообще удалить все записи, то можно сделать такой запрос:
7.3 Insert
Пожалуй, единственное, что отличается от других типов запросов, это . Формат такой:
Где , , это названия колонок, а , и это значения, которые нужно вставить в эти колонки, в том же порядке. Вот, в принципе, и все.
Взглянем на конкретный пример. Вот запрос с , который заполняет всю таблицу «books»:







