Команда grep: мощный инструмент для поиска текста в терминале
Содержание:
- Основное регулярное выражение
- grep примеры использования
- Основные команды grep
- Examples
- Поиск без учета регистра
- Точное соответствие строк
- Использование нескольких поисковых запросов
- Назначение операторов find и grep
- Регулярные выражения Linux
- 1.1, общая форма команды find
- Добавление контекста
- grep -E
- find — синтаксис и зачем оно нужно
- Искать полные слова
- Invert match using grep -v
- Catch space or tab
- Начало и конец строк
- Использование sed в Linux
Основное регулярное выражение
GNU Grep имеет два набора функций регулярных выражений, Basic и Extended. По умолчанию интерпретирует шаблон как основное регулярное выражение.
При использовании в основном режиме регулярных выражений все остальные символы, кроме метасимволов, на самом деле являются регулярными выражениями, которые соответствуют друг другу. Ниже приведен список наиболее часто используемых метасимволов:
Используйте символ ^ (символ каретки), чтобы сопоставить выражение в начале строки. В следующем примере строка ^kangaroo будет соответствовать только в том случае, если она встречается в самом начале строки.
grep «^kangaroo» file.txt
Используйте символ $ (доллар), чтобы соответствовать выражению в конце строки. В следующем примере строка kangaroo$ будет соответствовать только в том случае, если она встречается в самом конце строки.
grep «kangaroo$» file.txt
Используйте . (точка) символ для соответствия любому отдельному символу. Например, чтобы сопоставить все, что начинается с kan затем имеет два символа и заканчивается строкой roo, вы можете использовать следующий шаблон:
grep «kan..roo» file.txt
использование (скобки) для соответствия любому отдельному символу, заключенному в скобки. Например, найдите строки, которые содержат accept или « accent, вы можете использовать следующий шаблон:
grep «accet» file.txt
использование (скобки) для соответствия любому отдельному символу, заключенному в скобки. Следующий шаблон будет соответствовать любой комбинации строк, содержащих co(any_letter_except_l)a, такой как coca, cobalt и т. Д., Но не будет совпадать со строками, содержащими cola,
grep «coa» file.txt
Чтобы избежать специального значения следующего символа, используйте символ (обратная косая черта).
grep примеры использования
В принципе для работы grep не обязательно указывать даже файл или директорию, но это крайне желательно, если Вы хотите найти всё быстрее и точнее. Например:
Найдет файлы с упоминанием меня любимого, если таковые есть. Точнее не файлы, а строки с упоминанием указанного слова, т.е в данном случае sonikelf. Здесь стоит упомянуть, что строкой grep считает все символы, находящиеся между двумя символами новой строки.
| grep sonikelf file.txt | поиск sonikelf в файле file.txt, с выводом полностью совпавшей строкой |
| grep -o sonikelf file.txt | поиск sonikelf в файле file.txt и вывод только совпавшего куска строки |
| grep -i sonikelf file.txt | игнорирование регистра при поиске |
| grep -bn sonikelf file.txt | показать строку (-n) и столбец (-b), где был найден sonikelf |
| grep -v sonikelf file.txt | инверсия поиска (найдет все строки, которые не совпадают с шаблоном sonikelf) |
| grep -A 3 sonikelf file.txt | вывод дополнительных трех строк, после совпавшей |
| grep -B 3 sonikelf file.txt | вывод дополнительных трех строк, перед совпавшей |
| grep -C 3 sonikelf file.txt | вывод три дополнительные строки перед и после совпавшей |
| grep -r sonikelf $HOME | рекурсивный поиск по директории $HOME и всем вложенным |
| grep -c sonikelf file.txt | подсчет совпадений |
| grep -L sonikelf *.txt | вывести список txt-файлов, которые не содержат sonikelf |
| grep -l sonikelf *.txt | вывести список txt-файлов, которые содержат sonikelf |
| grep -w sonikelf file.txt | совпадение только с полным словом sonikelf |
| grep -f sonikelfs.txt file.txt | поиск по нескольким sonikelf из файла sonikelfs.txt, шаблоны разделяются новой строкой |
| grep -I sonikelf file.txt | игнорирование бинарных файлов |
| grep -v -f file2 file1 > file3 | вывод строк, которые есть в file1 и нет в file2 |
| grep -in -e ‘python’ `find -type f` | рекурсивный поиск файлов, содержащих слово python с выводом номера строки и совпадений |
| grep -inc -e ‘test’ `find -type f` | grep -v :0 | рекурсивный поиск файлов, содержащих слово python с выводом количества совпадений |
| grep . *.py | вывод содержимого всех py-файлов, предваряя каждую строку именем файла |
| grep «Http404» apps/**/*.py | рекурсивный поиск упоминаний Http404 в директории apps в py-файлах |
Основные команды grep
Вывести все упоминания слова
Предположим вы запустили
CentOS Linux
и хотите посмотреть все установленные пакеты в названии которых есть слово
kernel
yum list installed | grep kernel
abrt-addon-kerneloops.x86_64 2.1.11-60.el7.centos @base
kernel.x86_64 3.10.0-1160.el7 @anaconda
kernel.x86_64 3.10.0-1160.2.2.el7 @updates
kernel.x86_64 3.10.0-1160.6.1.el7 @updates
kernel-devel.x86_64 3.10.0-1160.2.2.el7 @updates
kernel-devel.x86_64 3.10.0-1160.6.1.el7 @updates
kernel-headers.x86_64 3.10.0-1160.6.1.el7 @updates
kernel-tools.x86_64 3.10.0-1160.6.1.el7 @updates
kernel-tools-libs.x86_64 3.10.0-1160.6.1.el7 @updates
И наоборот, можно посмотреть все строки где нет слова kernel
: нужно добавить опцию -v
yum list installed | grep -v kernel
Если вам нужно найти что-то в файле, можно вместо | воспользоваться выражением
grep ‘\bkernel\b’ huge_file
Где huge_file это имя файла в текущей директории в котором мы ищем отдельные слова kernel.
То есть слова akernel или kernelz найдены не будут
Вывести всё, что начинается со слова
Если нам теперь не нужны пакеты, в которых слово
kernel
в середине, а только те, которые начинаются с
kernel добавим перед словом знак ^
yum list installed | grep ^kernel
kernel.x86_64 3.10.0-1160.el7 @anaconda
kernel.x86_64 3.10.0-1160.2.2.el7 @updates
kernel.x86_64 3.10.0-1160.6.1.el7 @updates
kernel-devel.x86_64 3.10.0-1160.2.2.el7 @updates
kernel-devel.x86_64 3.10.0-1160.6.1.el7 @updates
kernel-headers.x86_64 3.10.0-1160.6.1.el7 @updates
kernel-tools.x86_64 3.10.0-1160.6.1.el7 @updates
kernel-tools-libs.x86_64 3.10.0-1160.6.1.el7 @updates
grep -E ‘ion$’ huge_file
compensation
generation
Допустим вы знаете только начало и конец слова
grep -E ‘^to..le$’ huge_file
topbicycle
Несколько символов подряд
Найти слова с пятью гласными подряд
grep -E ‘{5}’ /usr/share/dict/words
cadiueio
Chaouia
cooeeing
euouae
Guauaenok
miaoued
miaouing
Pauiie
queueing
Examples
Tip
If you haven’t already seen our section, we suggest reviewing that section first.
grep chope /etc/passwd
Search /etc/passwd for user chope.
grep "May 31 03" /etc/httpd/logs/error_log
Search the Apache error_log file for any error entries that happened on May 31st at 3 A.M. By adding quotes around the string, this allows you to place spaces in the grep search.
grep -r "computerhope" /www/
Recursively search the directory /www/, and all subdirectories, for any lines of any files which contain the string «computerhope«.
grep -w "hope" myfile.txt
Search the file myfile.txt for lines containing the word «hope«. Only lines containing the distinct word «hope» are matched. Lines where «hope» is part of a word (e.g., «hopes») are not be matched.
grep -cw "hope" myfile.txt
Same as previous command, but displays a count of how many lines were matched, rather than the matching lines themselves.
grep -cvw "hope" myfile.txt
Inverse of previous command: displays a count of the lines in myfile.txt which do not contain the word «hope».
grep -l "hope" /www/*
Display the file names (but not the matching lines themselves) of any files in /www/ (but not its subdirectories) whose contents include the string «hope«.
Поиск без учета регистра
По умолчанию чувствителен к регистру. Это означает, что символы верхнего и нижнего регистра рассматриваются как разные.
Чтобы игнорировать регистр при поиске, вызовите с параметром (или ).
Например, при поиске без какой-либо опции следующая команда не покажет никаких результатов, т.е. есть совпадающие строки:
Но если вы выполните поиск без учета регистра с использованием параметра , он будет соответствовать как заглавным, так и строчным буквам:
Указание «Зебра» будет соответствовать «зебре», «ZEbrA» или любой другой комбинации букв верхнего и нижнего регистра для этой строки.
Точное соответствие строк
В (регулярное выражение строки) будет соответствовать только строкам, в которых вся линия соответствует поисковому запросу. Давайте поищем метку даты и времени, которая, как мы знаем, появляется в файле журнала только один раз:
grep -x "20 января - 06 15:24:35" geek-1.log

Найдена и отображена единственная совпадающая строка.
Противоположность этому показывает только те линии, которые не матч. Это может быть полезно при просмотре файлов конфигурации. Комментарии — это здорово, но иногда среди них бывает сложно выделить настоящие настройки. Вот файл:

Мы можем эффективно отфильтровать строки комментариев следующим образом:
sudo grep -v "#" / etc / sudoers

Это намного проще разобрать.
Использование нескольких поисковых запросов
В Параметр (расширенное регулярное выражение) позволяет искать несколько слов. (В опция заменяет устаревший версия .)
Эта команда ищет два условия поиска: «средний» и «без памяти».
grep -E -w -i "средний | memfree" geek-1.log

Все совпадающие строки отображаются для каждого из условий поиска.

Вы также можете искать несколько терминов, которые не обязательно являются целыми словами, но могут быть и целыми словами.
В Параметр (шаблоны) позволяет использовать несколько условий поиска в командной строке. Мы используем скобки регулярных выражений для создания шаблона поиска. Оно говорит для соответствия любому из символов, содержащихся в скобках «[]». Это означает будет соответствовать либо «kB», либо «KB» при поиске.

Обе строки совпадают, и на самом деле некоторые строки содержат обе строки.

Назначение операторов find и grep
Команда find в Linux является оператором командной строки для работы с файлами в обход существующей иерархии. Она позволяет производить поиск файлов с использованием множества фильтров, а также выполнять некие действия над файлами после их успешного поиска. Среди критериев поиска файлов – практически все доступные атрибуты, от даты создания до разрешения.
Команда grep в Linux также относится к поисковым, но внутри файлов. Буквальный перевод команды – «глобальная печать регулярных выражений», но под печатью здесь понимается вывод результатов работы на устройство по умолчанию, каковым обычно является монитор. Обладая огромным потенциалом, оператор используется достаточно часто и позволяет производить поиск внутри одного или нескольких файлов по заданным фрагментам (шаблонам). Поскольку терминология в Linuxе существенно отличается от таковой в среде Windows, очень многие пользователи испытывают значительные трудности с использованием этих команд. Постараемся устранить этот недостаток.
Регулярные выражения Linux
В регулярных выражениях могут использоваться два типа символов:
- обычные буквы;
- метасимволы.
Обычные символы — это буквы, цифры и знаки препинания, из которых состоят любые строки. Все тексты состоят из букв и вы можете использовать их в регулярных выражениях для поиска нужной позиции в тексте.
Метасимволы — это кое-что другое, именно они дают силу регулярным выражениям. С помощью метасимволов вы можете сделать намного больше чем поиск одного символа. Вы можете искать комбинации символов, использовать динамическое их количество и выбирать диапазоны. Все спецсимволы можно разделить на два типа, это символы замены, которые заменяют собой обычные символы, или операторы, которые указывают сколько раз может повторяться символ. Синтаксис регулярного выражения будет выглядеть таким образом:
обычный_символ спецсимвол_оператор
спецсимвол_замены спецсимвол_оператор
Если оператор не указать, то будет считаться, что символ обязательно должен встретится в строке один раз. Таких конструкций может быть много. Вот основные метасимволы, которые используют регулярные выражения bash:
- \ — с обратной косой черты начинаются буквенные спецсимволы, а также он используется если нужно использовать спецсимвол в виде какого-либо знака препинания;
- ^ — указывает на начало строки;
- $ — указывает на конец строки;
- * — указывает, что предыдущий символ может повторяться 0 или больше раз;
- + — указывает, что предыдущий символ должен повторится больше один или больше раз;
- ? — предыдущий символ может встречаться ноль или один раз;
- {n} — указывает сколько раз (n) нужно повторить предыдущий символ;
- {N,n} — предыдущий символ может повторяться от N до n раз;
- . — любой символ кроме перевода строки;
- — любой символ, указанный в скобках;
- х|у — символ x или символ y;
- — любой символ, кроме тех, что указаны в скобках;
- — любой символ из указанного диапазона;
- — любой символ, которого нет в диапазоне;
- \b — обозначает границу слова с пробелом;
- \B — обозначает что символ должен быть внутри слова, например, ux совпадет с uxb или tuxedo, но не совпадет с Linux;
- \d — означает, что символ — цифра;
- \D — нецифровой символ;
- \n — символ перевода строки;
- \s — один из символов пробела, пробел, табуляция и так далее;
- \S — любой символ кроме пробела;
- \t — символ табуляции;
- \v — символ вертикальной табуляции;
- \w — любой буквенный символ, включая подчеркивание;
- \W — любой буквенный символ, кроме подчеркивания;
- \uXXX — символ Unicdoe.
Важно отметить, что перед буквенными спецсимволами нужно использовать косую черту, чтобы указать, что дальше идет спецсимвол. Правильно и обратное, если вы хотите использовать спецсимвол, который применяется без косой черты в качестве обычного символа, то вам придется добавить косую черту
Например, вы хотите найти в тексте строку 1+ 2=3. Если вы используете эту строку в качестве регулярного выражения, то ничего не найдете, потому что система интерпретирует плюс как спецсимвол, который сообщает, что предыдущая единица должна повториться один или больше раз. Поэтому его нужно экранировать: 1 \+ 2 = 3. Без экранирования наше регулярное выражение соответствовало бы только строке 11=3 или 111=3 и так далее. Перед равно черту ставить не нужно, потому что это не спецсимвол.
1.1, общая форма команды find
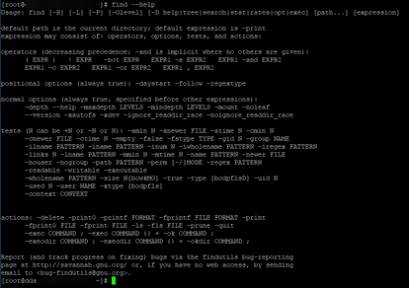
Общая форма команды find, приведенная в документе man:
на самом делеЭти параметры обычно не используются (по крайней мере, в моей повседневной работе, я не использовал их), общая форма приведенной выше команды поиска может быть упрощена до:
| команда | Описание |
|---|---|
| path | Путь к каталогу, который ищется командой find. Например, используйте. Для представления текущего каталога и / для представления корневого каталога системы. |
| expression | Выражение можно разделить на |
| -options | Укажите общие параметры команды find, подробно описанные в следующем разделе. |
| Команда find выводит сопоставленные файлы на стандартный вывод | |
| -exec | Команда find выполняет команду оболочки, заданную этим параметром для соответствующего файла. Соответствующая команда имеет вид,нотас участиемПространство между |
| -ok | Он имеет тот же эффект, что и -exec, за исключением того, что команда оболочки, заданная этим параметром, выполняется в более безопасном режиме.Перед выполнением каждой команды будет выдано приглашение, позволяющее пользователю определить, выполнять ли ее. |
пример 1:Удалить файлы с нулевым размером файла
(Вы также можете сделать это: rm -i Или найдите ./ -size 0 | xargs rm -f &)
Пример 2:Чтобы вывести список соответствующих файлов с помощью команды ls -l, вы можете поместить команду ls -l в опцию -exec команды find:
Пример 3:В каталоге / logs найдите файлы, время изменения которых составляет до 5 дней, и удалите их:
Пример 4:Найдите в текущем каталоге все файлы, имена которых заканчиваются на .conf и время изменения которых превышает 5 дней, и удалите их, но перед удалением выведите подсказку.
Некоторые люди также описывают структуру команды find следующим образом:
Добавление контекста
Часто бывает полезно иметь возможность видеть некоторые дополнительные строки — возможно, несовпадающие — для каждой совпадающей строки. это может помочь определить, какие из совпадающих строк вам интересны.
Чтобы отобразить несколько строк после совпадающей строки, используйте параметр -A (после контекста). В этом примере мы запрашиваем три строки:
grep -A 3 -x "20-янв-06 15:24:35" geek-1.log

Чтобы увидеть некоторые строки перед совпадающей строкой, используйте (контекст перед) вариант.
grep -B 3 -x "20-янв-06 15:24:35" geek-1.log

И чтобы включить строки до и после совпадающей строки, используйте (контекст) вариант.
grep -C 3 -x "20-янв-06 15:24:35" geek-1.log

grep -E
С некоторыми задачами обычный grep не справляется, поэтому нужен расширеный режим.
Найти в файле file
все foobar или foo bar с ровно одним пробелом
grep -E ‘foo\s?bar’ file
Найти в файле file
все foobar или foo bar с ровно двумя пробелами
grep -E ‘foo\s{2}bar’ file
Более сложный пример. Сотрудникам
TopBicycle
нужно понять у каких велосипедов в списке отсутствует или неправильно записан порядковый номер.
Номер должен быть в формате 111-11-1111 то есть три цифры дефис две цифры дефис четыре цифры
cat bikes.txt
Stels,Pilot,111-22-3333
Merida,BigNine,,
Stark,Cobra,xxx-xx-xxx
Forward,Tracer,1234-0
Author,Grand,444-55-6666
Stels,Pilot21,111-22-3344
Giant,Lannister,555-66-7777
Helkama,Jopo,,
grep -vE ‘\b{3}-{2}-{4}\b’ bikes.txt
Merida,BigNine,,
Stark,Cobra,xxx-xx-xxx
Forward,Tracer,1234-0
Helkama,Jopo,,
Правильные записи
grep -E ‘\b{3}-{2}-{4}\b’ bikes.txt
Stels,Pilot,111-22-3333
Author,Grand,444-55-6666
Stels,Pilot21,111-22-3344
Giant,Lannister,555-66-7777
find — синтаксис и зачем оно нужно
find — утилита поиска файлов по имени и другим свойствам, используемая в UNIX‐подобных операционных системах. С лохматых тысячелетий есть и поддерживаться почти всеми из них.
Базовый синтаксис ключей (забран с Вики):
-name — искать по имени файла, при использовании подстановочных образцов параметр заключается в кавычки
Опция `-name’ различает прописные и строчные буквы; чтобы использовать поиск без этих различий, воспользуйтесь опцией `-iname’;
-type — тип искомого: f=файл, d=каталог, l=ссылка (link), p=канал (pipe), s=сокет;
-user — владелец: имя пользователя или UID;
-group — владелец: группа пользователя или GID;
-perm — указываются права доступа;
-size — размер: указывается в 512-байтных блоках или байтах (признак байтов — символ «c» за числом);
-atime — время последнего обращения к файлу (в днях);
-amin — время последнего обращения к файлу (в минутах);
-ctime — время последнего изменения владельца или прав доступа к файлу (в днях);
-cmin — время последнего изменения владельца или прав доступа к файлу (в минутах);
-mtime — время последнего изменения файла (в днях);
-mmin — время последнего изменения файла (в минутах);
-newer другой_файл — искать файлы созданные позже, чем другой_файл;
-delete — удалять найденные файлы;
-ls — генерирует вывод как команда ls -dgils;
-print — показывает на экране найденные файлы;
-print0 — выводит путь к текущему файлу на стандартный вывод, за которым следует символ ASCII NULL (код символа 0);
-exec command {} \; — выполняет над найденным файлом указанную команду; обратите внимание на синтаксис;
-ok — перед выполнением команды указанной в -exec, выдаёт запрос;
-depth или -d — начинать поиск с самых глубоких уровней вложенности, а не с корня каталога;
-maxdepth — максимальный уровень вложенности для поиска. «-maxdepth 0» ограничивает поиск текущим каталогом;
-prune — используется, когда вы хотите исключить из поиска определённые каталоги;
-mount или -xdev — не переходить на другие файловые системы;
-regex — искать по имени файла используя регулярные выражения;
-regextype тип — указание типа используемых регулярных выражений;
-P — не разворачивать символические ссылки (поведение по умолчанию);
-L — разворачивать символические ссылки;
-empty — только пустые каталоги.
Примерно тоже самое, только больше и в не самом удобочитаемом виде, т.к надо делать запрос по каждому ключу отдельно, можно получить по
Результатам будет нечто такое из чего можно вычленять справку по отдельному ключу или команде (кликабельно):
В качестве развлечения можно использовать:
Дабы получить мануал из самой системы по базису и ключам (тоже кликабельно);

Немного о примерах использования. Точно так же, оттуда же и тп. Просто для понимания как оно работает вообще. Наиболее просто, конечно, осознать это потренировавшись в той же консоли на реальной системе.
Искать полные слова
При поиске строки отобразит все строки, в которых строка встроена в строки большего размера.
Например, если вы ищете «gnu», все строки, в которых «gnu» встроено в слова большего размера, такие как «cygnus» или «magnum», будут найдены:
Чтобы вернуть только те строки, в которых указанная строка представляет собой целое слово (заключенное в символы, отличные от слов), используйте параметр (или ).
Символы слова включают буквенно-цифровые символы ( , и ) и символы подчеркивания ( ). Все остальные символы считаются несловесными символами.
Если вы запустите ту же команду, что и выше, включая параметр , команда вернет только те строки, где включен как отдельное слово.
Invert match using grep -v
You had different options to show the lines matched, to show the lines before match, and to show the lines after match, and to highlight match. So definitely You’d also want the option -v to do invert match.
When you want to display the lines which does not matches the given string/pattern, use the option -v as shown below. This example will display all the lines that did not match the word «go».
$ grep -v "go" demo_text 4. Vim Word Navigation You may want to do several navigation in relation to the words, such as: WORD - WORD consists of a sequence of non-blank characters, separated with white space. word - word consists of a sequence of letters, digits and underscores. Example to show the difference between WORD and word * 192.168.1.1 - single WORD * 192.168.1.1 - seven words.
Catch space or tab
As we mentioned earlier in our explanation of how to search for a string, you can wrap text inside quotes if it contains spaces. The same method will work for tabs, but we’ll explain how to put a tab in your grep command in a moment.
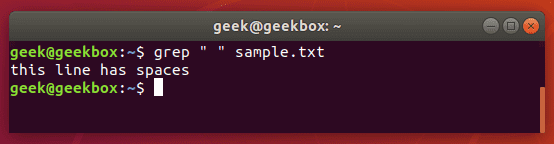
Put a space or multiple spaces inside quotes to have grep search for that character.
$ grep " " sample.txt
There are a few different ways you can search for a tab with grep, but most of the methods are experimental or can be inconsistent across different distributions.
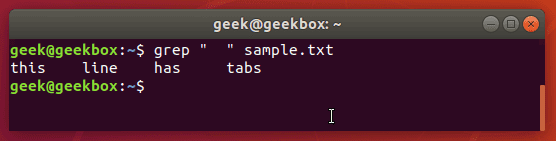
The easiest way is to just search for the tab character itself, which you can produce by hitting ctrl+v on your keyboard, followed by tab.
Normally, pressing tab in a terminal window tells the terminal that you want to auto-complete a command, but pressing the ctrl+v combination beforehand will cause the tab character to be written out as you’d normally expect it to in a text editor.
$ grep " " sample.txt
Knowing this little trick is especially useful when greping through configuration files in Linux since tabs are frequently used to separate commands from their values.
Начало и конец строк
Мы можем заставить для отображения только тех совпадений, которые находятся либо в начале, либо в конце строки. Оператор регулярного выражения «^» соответствует началу строки. Практически все строки в файле журнала будут содержать пробелы, но мы будем искать строки, в которых пробел является первым символом:
grep "^" geek-1.log

Отображаются строки с пробелом в качестве первого символа — в начале строки.

Чтобы соответствовать концу строки, используйте оператор регулярного выражения «$». Мы будем искать строки, заканчивающиеся на «00».
grep "00 $" geek-1.log

На дисплее отображаются строки, в конце которых указано «00».

Использование sed в Linux
sed (от англ. Stream EDitor) — потоковый текстовый редактор (а также язычок программирования), использующий различные предопределённые текстовые преобразования к последовательному потоку текстовых этих. Sed можно утилизировать как grep, выводя строки по шаблону базового регулярного выражения:
Может быть использовать его для удаления строк (удаление всех пустых строк):
Основным инструментом работы с sed является выражение типа:
Так, образчик, если выполнить команду:
Выше рассмотрены различия меж «grep», «egrep» и «fgrep». Невзирая на различия в наборе используемых регулярных представлений и скорости выполнения, параметры командной строчки остаются одинаковыми для всех трех версий grep.




