Коэффициент корреляции
Содержание:
- Примеры расчета хи-квадрата Пирсона
- Функция КОРРЕЛ для определения взаимосвязи и корреляции в Excel
- Результаты корреляционного анализа
- Как выполняется корреляция в Excel?
- Дополнительное замечание про распределения:
- Значения коэффициента корреляции
- Как вы можете рассчитать корреляцию с помощью Excel? — 2019
- 3) уравнение линейной регрессии на
- Выборочный r и популяционный ρ
- Графическое представление коэффициента Фехнера
Примеры расчета хи-квадрата Пирсона
Пример 1:
Необходимо определить наличие влияния предшествующей степени нарушения кровообращения на исход комиссуротомии (хирургическое разделение спаек при стенозе клапанного отверстия сердца). Пациенты поступали на комиссуротомию с различными исходными уровнями нарушения кровообращения. После комиссуротомии пациенты были выписаны с различными исходами операции.
Таблица: наблюдаемые (Observed) частоты распределения влияния степени нарушения кровообращения на результаты операции комиссуротомии
| Степень нарушения кровообращения | Всего больных | Выписан с хорошим результатом операции | Выписан с удовлетворительным результатом операции | Выписан с ухудшением |
| II | 30 | 20 | 8 | 2 |
| III | 80 | 43 | 20 | 17 |
| IV | 60 | 10 | 40 | 10 |
| Всего | 170 | 73 | 68 | 29 |
| H0-гипотеза | 100% | 43% | 40% | 17% |
Расчет ожидаемых (Expected) величин (на основании групповых частот)
Второй этап
Сопоставление наблюдаемых и ожидаемых частот с нахождением их разницы (O-E)
| Степень нарушения кровообращения | Выписан с хорошим результатом операции | Выписан с удовлетворительным результатом операции | Выписан с ухудшением |
| II | +7 | -4 | -3 |
| III | +9 | -12 | +3 |
| IV | -16 | +16 | |
| Всего |
Третий этап
Рассчитываем сумму отношений квадрата разности значений и делим ожидаемые данные (хи-квадрат) (O-E)2/E
| Степень нарушения кровообращения | Выписан с хорошим результатом операции | Выписан с удовлетворительным результатом операции | Выписан с ухудшением |
| II | 49/13=3,77 | 16/12=1,33 | 9/5=1,80 |
| III | 81/34=2,38 | 144/32=4,50 | 9/14=0,64 |
| IV | 256/26=9,85 | 256/24=10,66 | 0/10*=0,10 |
| Всего | 16 | 16,49 | 2,54 |
как видно из данной таблицы одно из ожидаемых значений равно 0, в данном случае будет подставлена 1, корректнее применить точный критерий Фишера (см. Условия применения хи-квадрата Пирсона)
Четвертый этап
Необходимо соотнести полученное значение хи-квадрата с критическим значением хи-квадрата.Возникает вопрос, откуда брать критическое значение? Критическое значение хи-квадрата, как и для большинства, статистических критериев зависит от степени свободы и уровня достоверности (alpha), который Вы выбираете.В нашем случае, наше количество степеней свободы равно (3-1)*(3-1)=4, уровень значимости, который мы хотим соблюсти равен 0,05Обратимся к таблице критических значение хи-квадрата:
- Xи-квадрат (для d.f.=4 p=0.05) = 9.488
- Xи-квадрат (для d.f.=4 p=0.01) = 13.27735,03 > 13,277;
- p<0,01
Пример корректной интерпретации: Предшествующая степень нарушения кровообращения влияет на исход комиссуротомии (однако! Мы не можем говорить о направленности связи, то есть: улучшает-ухудшает сказать не можем), оптимально указать степень свободы, точное значение хи-квадрата, если есть возможность рассчитать точное значение достоверности, то так же стоит указать и его или остановиться на критическом значении достоверности (p<0,05 или p<0,01 и так далее).В нашем случае:d.f.=4, x2=35,03, p< 0.01Пример 2: Вернемся к нашему примеру с влиянием курения на развитие артериальной гипертензии:Исходная четырехпольная таблица:
| Повышенное АД | АД в пределах норма | Всего | |
| «Курильщики» | 40 | 30 | 70 |
| «Не курят» | 32 | 48 | 80 |
| Всего | 72 | 78 | 150 |
Для четырехпольных таблиц существует упрощенная формула расчета значения хи-квадрата:
| Исход + | Исход 0 | Всего | |
| Фактор + | a | b | a+b |
| Фактор 0 | c | d | c+d |
| Всего | a+c | b+d | N |
- x2= (40х48 – 32х30)х150 / (70)(80)(72)(78) = (1920 – 960)2х150/31449600 = 138240000/31449600 = 4,395
- Сравним полученное значение хи-квадрата с критическим значением (для степени свободы 1, и уровнем значимости 3,841)
Правильная интерпретация: Курение оказывает влияние на формирование повышенного артериального давления df=1, x2= 4,395, p<0,05
Функция КОРРЕЛ для определения взаимосвязи и корреляции в Excel
КОРРЕЛ – функция, применяемая для подсчета коэффициента корреляции между 2-мя массивами. Разберем на четырех примерах все способности этой функции.
Примеры использования функции КОРРЕЛ в Excel
Первый пример. Есть табличка, в которой расписана информация об усредненных показателях заработной платы работников компании на протяжении одиннадцати лет и курсе $. Необходимо выявить связь между этими 2-умя величинами. Табличка выглядит следующим образом:
24
Алгоритм расчёта выглядит следующим образом:
25
Отображенный показатель близок к 1. Результат:
26
Определение коэффициента корреляции влияния действий на результат
Второй пример. Два претендента обратились за помощью к двум разным агентствам для реализации рекламного продвижения длительностью в пятнадцать суток. Каждые сутки проводился социальный опрос, определяющий степень поддержки каждого претендента. Любой опрошенный мог выбрать одного из двух претендентов или же выступить против всех. Необходимо определить, как сильно повлияло каждое рекламное продвижение на степень поддержки претендентов, какая компания эффективней.
27
Используя нижеприведенные формулы, рассчитаем коэффициент корреляции:
- =КОРРЕЛ(А3:А17;В3:В17).
- =КОРРЕЛ(А3:А17;С3:С17).
Результаты:
28
Из полученных результатов становится понятно, что степень поддержки 1-го претендента повышалась с каждыми сутками проведения рекламного продвижения, следовательно, коэффициент корреляции приближается к 1. При запуске рекламы другой претендент обладал большим числом доверия, и на протяжении 5 дней была положительная динамика. Потом степень доверия понизилась и к пятнадцатым суткам опустилась ниже изначальных показателей. Низкие показатели говорят о том, что рекламное продвижение отрицательно повлияло на поддержку. Не стоит забывать, что на показатели могли повлиять и остальные сопутствующие факторы, не рассматриваемые в табличной форме.
Анализ популярности контента по корреляции просмотров и репостов видео
Третий пример. Человек для продвижения собственных роликов на видеохостинге Ютуб применяет соцсети для рекламирования канала. Он замечает, что существует некая взаимосвязь между числом репостов в соцсетях и количеством просмотров на канале. Можно ли про помощи инструментов табличного процессора произвести прогноз будущих показателей? Необходимо выявить резонность применения уравнения линейной регрессии для прогнозирования числа просмотров видеозаписей в зависимости от количества репостов. Табличка со значениями:
29
Теперь необходимо провести определение наличия связи между 2-мя показателями по нижеприведенной формуле:
0,7;ЕСЛИ(КОРРЕЛ(A3:A8;B3:B8)>0,7;»Сильная прямая зависимость»;»Сильная обратная зависимость»);»Слабая зависимость или ее отсутствие»)’ class=’formula’>
Если полученный коэффициент выше 0,7, то целесообразней применять функцию линейной регрессии. В рассматриваемом примере делаем:
30
Теперь производим построение графика:
31
Применяем это уравнение, чтобы определить число просматриваний при 200, 500 и 1000 репостов: =9,2937*D4-206,12. Получаем следующие результаты:
32
Функция ПРЕДСКАЗ позволяет определить число просмотров в моменте, если было проведено, к примеру, двести пятьдесят репостов. Применяем: 0,7;ПРЕДСКАЗ(D7;B3:B8;A3:A8);»Величины не взаимосвязаны»)’ class=’formula’>. Получаем следующие результаты:
33
Особенности использования функции КОРРЕЛ в Excel
Данная функция имеет нижеприведенные особенности:
- Не учитываются ячейки пустого типа.
- Не учитываются ячейки, в которых находится информация типа Boolean и Text.
- Двойное отрицание «—» применяется для учёта логических величин в виде чисел.
- Количество ячеек в исследуемых массивах обязаны совпадать, иначе будет выведено сообщение #Н/Д.
Результаты корреляционного анализа
Если результат корреляционного анализа положительный, то взаимосвязь двух переменных прямо пропорциональная. Это означает, что при увеличении одной переменной, вторая будет также увеличиваться. Как правило, такой результат принято называть “позитивной корреляцией”.
Если результат корреляционного анализа отрицательный, то взаимосвязь двух переменных обратно пропорциональная. Это означает, что при увеличении одной переменной, вторая будет уменьшаться. Такой эффект называется “отрицательной корреляцией”.
Таким образом, чем ближе значение КА к (+1) или (-1), тем сильнее взаимосвязь между двумя переменными. Соответственно, если результат анализа стремится к нулю, то взаимосвязь между двумя переменными отсутствует. Статистически значимыми принято считать значения, результат которых выше 0,5 в обоих направлениях.
Корреляционный анализ следует использовать, когда вы считаете, что есть связь между двумя переменными и вы хотите в этом убедиться. Также, КА можно использовать между несколькими переменными, проводя последовательную оценку, для определения наибольшей взаимосвязи.
Применение корреляционного анализа
Применение КА широко распространено, поскольку он позволяет выявить неожиданные взаимосвязи, которые позволяют делать более глубокий анализ и использовать полученные результаты для извлечения выгоды. Анализ полезен при тестировании гипотез ценообразования и продаж, развития стратегии и продуктового портфеля.
Например, корреляционный анализ поможет ответить на такие вопросы:
- Влияет ли скидка на увеличение продаж?
- Влияет ли уменьшение цены на увеличение продаж?
- Являются ли лояльные клиенты самыми прибыльными?
Самый простой пример: такие факторы, как жаркая погода и продажи мороженного можно подвергнуть корреляционному анализу. Логично сделать заключение, что жаркая погода является причиной того, что люди покупают больше мороженного. При этом, жаркая погода может стать причиной увеличения продаж хлора для бассейнов. Но при этом продажа мороженного никак не коррелируется с продажей хлора.
Более того, корреляционный анализ применяется в рамках концепции Lean SixSigma для поиска коренных причин проблемы и их взаимного влияния друг на друга.
Как выполняется корреляция в Excel?
«Корреляция» в переводе с латинского обозначает «соотношение», «взаимосвязь». Количественная характеристика взаимосвязи может быть получена при вычислении коэффициента корреляции.
Этот популярный в статистических анализах коэффициент показывает, связаны ли какие-либо параметры друг с другом (например, рост и вес; уровень интеллекта и успеваемость; количество травм и продолжительность работы).
Использование корреляции
Вычисление корреляции особенно широко используется в экономике, социологических исследованиях, медицине и биометрии — везде, где можно получить два массива данных, между которыми может обнаружиться связь.
Рассчитать корреляцию можно вручную, выполняя несложные арифметические действия. Однако процесс вычисления оказывается очень трудоемким, если набор данных велик. Особенность метода в том, что он требует сбора большого количества исходных данных, чтобы наиболее точно отобразить, есть ли связь между признаками.
Поэтому серьезное использование корреляционного анализа невозможно без применения вычислительной техники. Одной из наиболее популярных и доступных программ для решения этой задачи является Microsoft Office Excel.
Как выполнить корреляцию в Excel?
Самым трудоемким этапом определения корреляции является набор массива данных. Сравниваемые данные располагаются обычно в двух колонках или строчках. Таблицу следует делать без пропусков в ячейках. Современные версии Excel (с 2007 и младше) не требуют установок дополнительных настроек для статистических расчетов; необходимые манипуляции можно сделать в разделе формул:
- Выбрать пустую ячейку, в которую будет выведен результат расчетов.
- Нажать в главном меню Excel пункт «Формулы».
- Среди кнопок, сгруппированных в «Библиотеку функций», выбрать «Другие функции».
- В выпадающих списках выбрать функцию расчета корреляции (Статистические — КОРРЕЛ).
- В Excel откроется панель «Аргументы функции». «Массив 1» и «Массив 2» — это диапазоны сравниваемых данных. Для автоматического заполнения этих полей можно просто выделить нужные ячейки таблицы.
- Нажать «ОК», закрыв окно аргументов функции. В ячейке появится подсчитанный коэффициент корреляции.
Корреляция может быть прямая (если коэффициент больше нуля) и обратная (от -1 до 0).
Первая означает, что при росте одного параметра растет и другой. Обратная (отрицательная) корреляция отражает факт, что при росте одной переменной другая уменьшается.
Корреляция может быть близка к нулю. Это обычно свидетельствует, что исследуемые параметры не связаны друг с другом. Но иногда нулевая корреляция возникает, если сделана неудачная выборка, которая не отразила связь, либо связь имеет сложный нелинейный характер.
Если коэффициент показывает среднюю или сильную взаимосвязь (от ±0,5 до ±0,99), следует помнить, что это лишь статистическая взаимосвязь, которая вовсе не гарантирует влияние одного параметра на другой. Также нельзя исключать ситуации, что оба параметра независимы друг от друга, но на них воздействует какой-нибудь третий неучтенный фактор.
Excel помогает моментально вычислить коэффициент корреляции, но обычно только количественных методов недостаточно для установления причинно-следственных связей в соотносимых выборках.
Дополнительное замечание про распределения:
нормально ли, что анализируя данные геофизического мониторинга, мы никогда не встречаемся с нормальным распределением?
Да-да, я в курсе про Центральную предельную теорему. Но еще больше я склонен верить практике обработки тысяч различных экспериментальных сигналов — прежде всего, данных геофизического мониторинга, но далеко не только его. Поэтому большая просьба к тем «чистым» математикам, которых задевает утверждение, что отсутствие нормальности — это нормально: не надо ругаться! Просто возьмите десяток-другой экспериментальных рядов, полученных в результате длительных (многие недели и месяцы) наблюдений и содержащих достаточное количество точек данных (десятки тысяч и более). И попробуйте найти среди них такие, чье распределение неотличимо от нормального, например, по критерию хи-квадрат. К сожалению или к счастью, жизнь несколько отличается от
Можно с уверенностью утверждать, что для подавляющего большинства сигналов, получаемых при долговременном мониторинге, условия ЦПТ не выполнены. Во-первых, нет никаких гарантий, что поведение контролируемой величины зависит от многих малых и независимых причинных факторов — наоборот, обычно они коррелированы между собой, а вклад некоторых преобладает
Но еще более важно, что практически все природные процессы нестационарны, что сразу же выводит их за рамки явлений, к которым может быть применена ЦПТ. Впрочем, это уже отдельный вопрос, который обсуждается в
Значения коэффициента корреляции
Охарактеризовать силу корреляционной связи можно прибегнув к шкале Челдока, в которой определенному числовому значению соответствует качественная характеристика.
- 0-0,3 – корреляционная связь очень слабая;
- 0,3-0,5 – слабая;
- 0,5-0,7 – средней силы;
- 0,7-0,9 – высокая;
- 0,9-1 – очень высокая сила корреляции.
Шкала может использоваться и для отрицательной корреляции. В этом случае качественные характеристики заменяются на противоположные.
Можно воспользоваться упрощенной шкалой Челдока, в которой выделяется всего 3 градации силы корреляционной связи:
- очень сильная – показатели ±0,7 — ±1;
- средняя – показатели ±0,3 — ±0,699;
- очень слабая – показатели 0 — ±0,299.
Данный статистический показатель позволяет не только проверить предположение о существовании линейной взаимосвязи между признаками, но и установить ее силу.
История разработки критерия корреляции
Критерий корреляции Пирсона был разработан командой британских ученых во главе с Карлом Пирсоном (1857-1936) в 90-х годах 19-го века, для упрощения анализа ковариации двух случайных величин. Помимо Карла Пирсона над критерием корреляции Пирсона работали также Фрэнсис Эджуорт и Рафаэль Уэлдон.
Для чего используется критерий корреляции Пирсона?
Критерий корреляции Пирсона позволяет определить, какова теснота (или сила) корреляционной связи между двумя показателями, измеренными в количественной шкале. При помощи дополнительных расчетов можно также определить, насколько статистически значима выявленная связь.
Например, при помощи критерия корреляции Пирсона можно ответить на вопрос о наличии связи между температурой тела и содержанием лейкоцитов в крови при острых респираторных инфекциях, между ростом и весом пациента, между содержанием в питьевой воде фтора и заболеваемостью населения кариесом.
Условия и ограничения применения критерия хи-квадрат Пирсона
- Сопоставляемые показатели должны быть измерены в количественной шкале (например, частота сердечных сокращений, температура тела, содержание лейкоцитов в 1 мл крови, систолическое артериальное давление).
- Посредством критерия корреляции Пирсона можно определить лишь наличие и силу линейной взаимосвязи между величинами. Прочие характеристики связи, в том числе направление (прямая или обратная), характер изменений (прямолинейный или криволинейный), а также наличие зависимости одной переменной от другой – определяются при помощи регрессионного анализа.
- Количество сопоставляемых величин должно быть равно двум. В случае анализ взаимосвязи трех и более параметров следует воспользоваться методом факторного анализа.
- Критерий корреляции Пирсона является параметрическим, в связи с чем условием его применения служит нормальное распределение каждой из сопоставляемых переменных. В случае необходимости корреляционного анализа показателей, распределение которых отличается от нормального, в том числе измеренных в порядковой шкале, следует использовать коэффициент ранговой корреляции Спирмена.
- Следует четко различать понятия зависимости и корреляции. Зависимость величин обуславливает наличие корреляционной связи между ними, но не наоборот.
Например, рост ребенка зависит от его возраста, то есть чем старше ребенок, тем он выше. Если мы возьмем двух детей разного возраста, то с высокой долей вероятности рост старшего ребенка будет больше, чем у младшего. Данное явление и называется зависимостью, подразумевающей причинно-следственную связь между показателями. Разумеется, между ними имеется и корреляционная связь, означающая, что изменения одного показателя сопровождаются изменениями другого показателя.
В другой ситуации рассмотрим связь роста ребенка и частоты сердечных сокращений (ЧСС). Как известно, обе эти величины напрямую зависят от возраста, поэтому в большинстве случаев дети большего роста (а значит и более старшего возраста) будут иметь меньшие значения ЧСС. То есть, корреляционная связь будет наблюдаться и может иметь достаточно высокую тесноту. Однако, если мы возьмем детей одного возраста, но разного роста, то, скорее всего, ЧСС у них будет различаться несущественно, в связи с чем можно сделать вывод о независимости ЧСС от роста.
Приведенный пример показывает, как важно различать фундаментальные в статистике понятия связи и зависимости показателей для построения верных выводов
Как вы можете рассчитать корреляцию с помощью Excel? — 2019
a:
Корреляция измеряет линейную зависимость двух переменных. Измеряя и связывая дисперсию каждой переменной, корреляция дает представление о силе взаимосвязи. Или, говоря иначе, корреляция отвечает на вопрос: сколько переменная A (независимая переменная) объясняет переменную B (зависимую переменную)?
Формула корреляции
Корреляция объединяет несколько важных и связанных статистических понятий, а именно дисперсию и стандартное отклонение. Разница — дисперсия переменной вокруг среднего, а стандартное отклонение — квадратный корень дисперсии.
Формула:
Поскольку корреляция требует оценки линейной зависимости двух переменных, то, что действительно необходимо, — это выяснить, какая сумма ковариации этих двух переменных и в какой степени такая ковариация отраженные стандартными отклонениями каждой переменной в отдельности.
Общие ошибки с корреляцией
Самая распространенная ошибка — предполагать, что корреляция, приближающаяся +/- 1, статистически значима. Считывание, приближающееся +/- 1, безусловно увеличивает шансы на фактическую статистическую значимость, но без дальнейшего тестирования это невозможно узнать.
Статистическое тестирование корреляции может усложняться по ряду причин; это совсем не так просто. Критическое предположение о корреляции состоит в том, что переменные независимы и связь между ними является линейной.
Вторая наиболее распространенная ошибка — забыть нормализовать данные в единую единицу. Если вычислять корреляцию по двум бетам, то единицы уже нормализованы: сама бета является единицей
Однако, если вы хотите скорректировать акции, важно, чтобы вы нормализовали их в процентном отношении, а не изменяли цены. Это происходит слишком часто, даже среди профессионалов в области инвестиций
Для корреляции цен на акции вы, по сути, задаете два вопроса: каково возвращение за определенное количество периодов и как этот доход коррелирует с возвратом другой безопасности за тот же период? Это также связано с тем, что корреляция цен на акции затруднена: две ценные бумаги могут иметь высокую корреляцию, если доход составляет ежедневно процентов за последние 52 недели, но низкая корреляция, если доход ежемесячно > изменения за последние 52 недели. Какая из них лучше»? На самом деле нет идеального ответа, и это зависит от цели теста. ( Улучшите свои навыки excel, пройдя курс обучения Excel в Академии Excel. ) Поиск корреляции в Excel
Существует несколько методов расчета корреляции в Excel
Самый простой способ — получить два набора данных и использовать встроенную формулу корреляции:
Это удобный способ расчета корреляции между двумя наборами данных. Но что, если вы хотите создать корреляционную матрицу во множестве наборов данных? Для этого вам нужно использовать плагин анализа данных Excel. Плагин можно найти на вкладке «Данные» в разделе «Анализ».
Выберите таблицу возвратов. В этом случае наши столбцы имеют названия, поэтому мы хотим установить флажок «Ярлыки в первой строке», поэтому Excel знает, как обрабатывать их как заголовки. Затем вы можете выбрать вывод на том же листе или на новом листе.
Как только вы нажмете enter, данные будут автоматически сделаны. Вы можете добавить текст и условное форматирование, чтобы очистить результат.
3) уравнение линейной регрессии на
Это и есть та самая оптимальная прямая , которая проходит максимально близко ко всем точкам. Обычно её находят методом наименьших квадратов, и мы пойдём знакомым путём
Заполним расчётную таблицу:
Обратите внимание, что в отличие от задач урока МНК у нас появился дополнительный столбец , он потребуется в дальнейшем, для расчёта коэффициента корреляции
Сократим оба уравнения на 2, всё попроще будет:
Систему решим по формулам Крамера: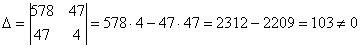 , значит, система имеет единственное решение.
, значит, система имеет единственное решение.

Таким образом, искомое уравнение регрессии:
Данное уравнение показывает, что с увеличением количества прогулов («икс») на 1 единицу суммарная успеваемость падает в среднем на 6,0485 – примерно на 6 баллов. Об этом нам рассказал коэффициент «а»
И обратите особое внимание, что эта функция возвращает нам средние (среднеожидаемые) значения «игрек» для различных значений «икс»
Почему это регрессия именно « на » и о происхождении самого термина «регрессия» я рассказал чуть ранее, в параграфе . Если кратко, то полученные с помощью уравнения средние значения успеваемости («игреки») регрессивно возвращают нас к первопричине – количеству прогулов. Вообще, регрессия – не слишком позитивное слово, но какое уж есть.
Найдём пару удобных точек для построения прямой: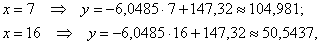
отметим их на чертеже (малиновый цвет) и проведём линию регрессии: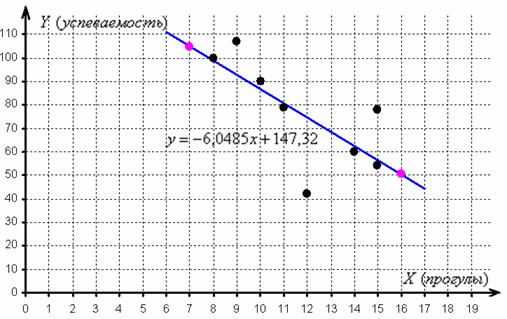
Говорят, что уравнение регрессии аппроксимирует (приближает) эмпирические данные (точки), и с помощью него можно интерполировать (восстановить) неизвестные промежуточные значения, так при количестве прогулов среднеожидаемая успеваемость составит балла.
И, конечно, осуществимо прогнозирование, так при среднеожидаемая успеваемость составит баллов. Единственное, нежелательно брать «иксы», которые расположены слишком далеко от эмпирических точек, поскольку прогноз, скорее всего, не будет соответствовать действительности. Например, при значение может вообще оказаться невозможным, ибо у успеваемости есть свой фиксированный «потолок». И, разумеется, «икс» или «игрек» в нашей задаче не могут быть отрицательными.
Второй вопрос касается тесноты зависимости. Очевидно, что чем ближе эмпирические точки к прямой, тем теснее линейная корреляционная зависимость – тем уравнение регрессии достовернее отражает ситуацию, и тем качественнее полученная модель. И наоборот, если многие точки разбросаны вдали от прямой, то признак зависит от вовсе не линейно (если вообще зависит) и линейная функция плохо отражает реальную картину.
Прояснить данный вопрос нам поможет:
Выборочный r и популяционный ρ
Аналогично среднему значению и стандартному отклонению, коэффициент корреляции является сводной статистикой. Он описывает выборку; в данном случае, выборку спаренных значений: роста и веса. Коэффициент корреляции известной выборки обозначается буквой r, тогда как коэффициент корреляции неизвестной популяции обозначается греческой буквой ρ (рхо).
Как мы убедились в предыдущей серии постов о тестировании гипотез, мы не должны исходить из того, что результаты, полученные в ходе измерения нашей выборки, применимы к популяции в целом. К примеру, наша популяция может состоять из всех пловцов всех недавних Олимпийских игр. И будет совершенно недопустимо обобщать, например, на другие олимпийские виды спорта, такие как тяжелая атлетика или фитнес-плавание.
Даже в допустимой популяции — такой как пловцы, выступавшие на недавних Олимпийских играх, — наша выборка коэффициента корреляции является всего лишь одной из многих потенциально возможных. То, насколько мы можем доверять нашему r, как оценке параметра ρ, зависит от двух факторов:
-
Размера выборки
-
Величины r
Безусловно, чем больше выборка, тем больше мы ей доверяем в том, что она представляет всю совокупность в целом. Возможно, не совсем интуитивно очевидно, но величина тоже оказывает влияние на степень нашей уверенности в том, что выборка представляет параметр . Это вызвано тем, что большие коэффициенты вряд ли возникли случайным образом или вследствие случайной ошибки при отборе.
Проверка статистических гипотез
В предыдущей серии постов мы познакомились с проверкой статистических гипотез, как средством количественной оценки вероятности, что конкретная гипотеза (как, например, что две выборки взяты из одной и той же популяции) истинная. Чтобы количественно оценить вероятность, что корреляция существует в более широкой популяции, мы воспользуемся той же самой процедурой.
В первую очередь, мы должны сформулировать две гипотезы, нулевую гипотезу и альтернативную:
H — это гипотеза, что корреляция в популяции нулевая. Другими словами, наше консервативное представление состоит в том, что измеренная корреляция целиком вызвана случайной ошибкой при отборе.
H1 — это альтернативная возможность, что корреляция в популяции не нулевая. Отметим, что мы не определяем направление корреляции, а только что она существует. Это означает, что мы выполняем двустороннюю проверку.
Стандартная ошибка коэффициента корреляции r по выборке задается следующей формулой:
Эта формула точна, только когда r находится близко к нулю (напомним, что величина ρ влияет на нашу уверенность), но к счастью, это именно то, что мы допускаем согласно нашей нулевой гипотезы.
Мы можем снова воспользоваться t-распределением и вычислить t-статистику:
В приведенной формуле df — это степень свободы наших данных. Для проверки корреляции степень свободы равна n — 2, где n — это размер выборки. Подставив это значение в формулу, получим:
В итоге получим t-значение 102.21. В целях его преобразования в p-значение мы должны обратиться к t-распределению. Библиотека scipy предоставляет интегральную функцию распределения (ИФР) для t-распределения в виде функции , и комплементарной ей (1-cdf) функции выживания . Значение функции выживания соответствует p-значению для односторонней проверки. Мы умножаем его на 2, потому что выполняем двустороннюю проверку:
P-значение настолько мало, что в сущности равно 0, означая, что шанс, что нулевая гипотеза является истинной, фактически не существует. Мы вынуждены принять альтернативную гипотезу о существовании корреляции.
Графическое представление коэффициента Фехнера
Пример №1. При разработке глинистого раствора с пониженной водоотдачей в высокотемпературных условиях проводили параллельное испытание двух рецептур, одна из которых содержала 2% КМЦ и 1% Na2CO3, а другая 2% КМЦ, 1% Na2CO3 и 0,1% бихромата калия. В результате получена следующие значения Х (водоотдача через 30 с).
| X1 | 9 | 9 | 11 | 9 | 8 | 11 | 10 | 8 | 10 |
| X2 | 10 | 11 | 10 | 12 | 11 | 12 | 12 | 10 | 9 |
Пример №2.
Коэффициент корреляции знаков, или коэффициент Фехнера, основан на оценке степени согласованности направлений отклонений индивидуальных значений факторного и результативного признаков от соответствующих средних. Вычисляется он следующим образом:
,
где na — число совпадений знаков отклонений индивидуальных величин от средней; nb — число несовпадений.
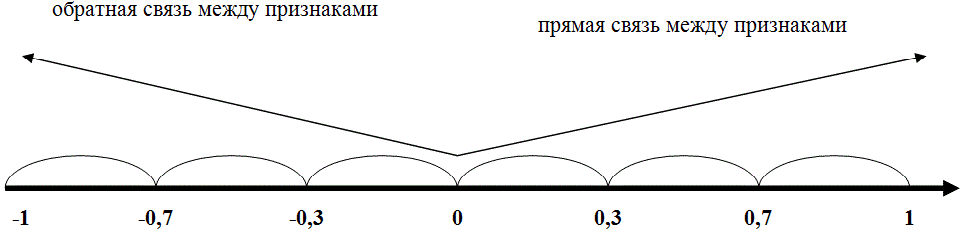
Коэффициент Фехнера может принимать значения от -1 до +1. Kф = 1 свидетельствует о возможном наличии прямой связи, Kф =-1 свидетельствует о возможном наличии обратной связи.
Рассмотрим на примере расчет коэффициента Фехнера по данным, приведенным в таблице:
|
Xi |
Yi |
Знаки отклонений значений признака от средней |
Совпадение (а) или несовпадение (в) знаков |
|
|
Для Xi |
Для Yi |
|||
|
8 |
40 |
— |
— |
А |
|
9 |
50 |
— |
+ |
В |
|
10 |
48 |
— |
+ |
В |
|
10 |
52 |
— |
+ |
В |
|
11 |
41 |
+ |
— |
В |
|
13 |
30 |
+ |
— |
В |
|
15 |
35 |
+ |
— |
В |
Для примера: .
Значение коэффициента свидетельствует о том, что можно предполагать наличие обратной связи.
Пример №2
Рассмотрим на примере расчет коэффициента Фехнера по данным, приведенным в таблице:
Средние значения:
|
Xi |
Yi |
Знаки отклонений от средней X |
Знаки отклонений от средней Y |
Совпадение (а) или несовпадение (b) знаков |
|
12 |
220 |
+ |
— |
B |
|
9 |
1070 |
— |
+ |
B |
|
8 |
1000 |
— |
+ |
B |
|
14 |
606 |
+ |
— |
B |
|
15 |
780 |
+ |
+ |
A |
|
10 |
790 |
— |
+ |
B |
|
10 |
900 |
— |
+ |
B |
|
15 |
544 |
+ |
— |
B |
|
93 |
5910 |
Значение коэффициента свидетельствует о том, что можно предполагать наличие обратной связи.
Интервальная оценка для коэффициента корреляции знаков
Пример №3.
Рассмотрим на примере расчет коэффициента корреляции знаков по данным, приведенным в таблице:
| Xi | Yi | Знаки отклонений от средней X | Знаки отклонений от средней Y | Совпадение (а) или несовпадение (b) знаков |
| 96 | 220 | + | — | B |
| 52 | 1070 | — | + | B |
| 60 | 1000 | — | + | B |
| 89 | 606 | + | — | B |
| 82 | 780 | + | + | A |
| 77 | 790 | — | + | B |
| 70 | 900 | — | + | B |
| 92 | 544 | + | — | B |
| 618 | 5910 |
Значение коэффициента свидетельствует о том, что можно предполагать наличие обратной связи.
Оценка коэффициента корреляции знаков. Значимость коэффициента корреляции знаков.
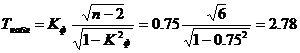 По таблице Стьюдента находим tтабл:
По таблице Стьюдента находим tтабл:
tтабл (n-m-1;a) = (6;0.05) = 1.943
Поскольку Tнабл > tтабл , то отклоняем гипотезу о равенстве 0 коэффициента корреляции знаков. Другими словами, коэффициент корреляции знаков статистически — значим.
Доверительный интервал для коэффициента корреляции знаков.
Доверительный интервал для коэффициента корреляции знаков.
r(-1;-0.4495)




