Регрессионный анализ в microsoft excel
Содержание:
- Разбор результатов анализа
- Пример решения нахождения модели множественной регрессии
- Расчет коэффициента корреляции
- Разбор результатов анализа
- Матрица парных коэффициентов корреляции в Excel
- Основные задачи и виды регрессии
- Использование MS EXCEL для расчета корреляции
- Подключение пакета анализа
- Регрессионный анализ в Excel
- Коэффициент корреляции: что нужно знать, формула, пример расчёта в Excel
- Анализ коэффициентов
- Другие виды регрессии
- Линейная регрессия в программе Excel
- Изучение результатов и выводы
Разбор результатов анализа
Результаты регрессионного анализа выводятся в виде таблицы в том месте, которое указано в настройках.

Одним из основных показателей является R-квадрат. В нем указывается качество модели. В нашем случае данный коэффициент равен 0,705 или около 70,5%. Это приемлемый уровень качества. Зависимость менее 0,5 является плохой.
Ещё один важный показатель расположен в ячейке на пересечении строки «Y-пересечение» и столбца «Коэффициенты». Тут указывается какое значение будет у Y, а в нашем случае, это количество покупателей, при всех остальных факторах равных нулю. В этой таблице данное значение равно 58,04.
Значение на пересечении граф «Переменная X1» и «Коэффициенты» показывает уровень зависимости Y от X. В нашем случае — это уровень зависимости количества клиентов магазина от температуры. Коэффициент 1,31 считается довольно высоким показателем влияния.
Как видим, с помощью программы Microsoft Excel довольно просто составить таблицу регрессионного анализа. Но, работать с полученными на выходе данными, и понимать их суть, сможет только подготовленный человек.
Мы рады, что смогли помочь Вам в решении проблемы.
Помогла ли вам эта статья?
Да Нет
-
Откройте программу Microsoft Excel.
- Проверьте, активен ли «Data Analysis» ToolPak, нажав на вкладку «Data».
Если вы не видите опцию, вам нужно будет включить надстройки, а именно:
- Откройте меню «File» (или нажмите Alt+F) и выберите «Options»
- Нажмите команду «Add-Ins» в левой части окна
- Нажмите кнопку «Go» рядом с опцией «Manage: Add-ins» в нижней части окна
- В новом окне установите флажок рядом с «Analysis ToolPak», затем нажмите «OK»
- Пункт add-in — теперь включен
-
Введите данные или откройте файл данных. Данные должны быть расположены непосредственно в смежных столбцах и метки должны быть в первой строке каждого столбца.
-
Выберите вкладку «Data», затем нажмите кнопку «Data Analysis» в группе «Analysis» (скорее всего на или вблизи правой части вариантов вкладки Data).
-
Введите зависящие данные (Y), поместив сначала курсор в поле «Input Y-Range», а затем выделите столбец данных в книге.
- Независимые переменные вводятся, поместив сначала курсор в поле «Input X-Range», а затем выделяя несколько столбцов в книге (например, $C$1:
$E$53).
- ПРИМЕЧАНИЕ: Столбцы независимых переменных данных ДОЛЖНЫ при их заполнении быть рядом друг с другом для правильного выполнения операции.
- Если вы используете метки (которые должны, опять же, быть в первой строке каждого столбца), установите флажок рядом с «Labels».
- Уровень достоверности по умолчанию составляет 95%. Если вы хотите изменить это значение, нажмите флажок «Confidence Level» и измените смежное значение.
- В разделе «Output Options» добавьте имя в поле «New Worksheet Ply».
-
Выберите нужные параметры в категории «Residuals». Графические остаточные выводы данных создаются с помощью опций «Residual Plots» и «Line Fit Plots».
-
Нажмите «OK» и анализ будет создан.
Регрессионный и корреляционный анализ – статистические методы исследования. Это наиболее распространенные способы показать зависимость какого-либо параметра от одной или нескольких независимых переменных.
Ниже на конкретных практических примерах рассмотрим эти два очень популярные в среде экономистов анализа. А также приведем пример получения результатов при их объединении.
Пример решения нахождения модели множественной регрессии
Множественная регрессия с двумя переменными
Модель множественной регрессии вида Y = b +b1X1 + b2X2; 1) Найтинеизвестные b, b1,b2 можно, решим систему трехлинейных уравнений с тремя неизвестными b,b1,b2: Для решения системы можете воспользоваться решение системы методом Крамера2) Или использовав формулы Для этого строим таблицу вида:
Для этого строим таблицу вида:
| Y | x1 | x2 | (y-yср)2 | (x1-x1ср)2 | (x2-x2ср)2 | (y-yср)(x1-x1ср) | (y-yср)(x2-x2ср) | (x1-x1ср)(x2-x2ср) |
Выборочные дисперсии эмпирических коэффициентов множественной регрессии можно определить следующим образом: Здесь z’jj — j-тый диагональный элемент матрицы Z-1 =(XTX)-1.  Приэтом: где m — количество объясняющихпеременных модели.В частности, для уравнения множественной регрессии
Приэтом: где m — количество объясняющихпеременных модели.В частности, для уравнения множественной регрессии
с двумя объясняющими переменными используются следующие формулы:
 Или
Или  или,,. Здесьr12 — выборочный коэффициент корреляции между объясняющимипеременными X1 и X2; Sbj — стандартная ошибкакоэффициента регрессии; S — стандартная ошибка множественной регрессии (несмещенная оценка).По аналогии с парной регрессией после определения точечных оценокbj коэффициентов βj (j=1,2,…,m) теоретического уравнения множественной регрессии могут быть рассчитаны интервальные оценки указанных коэффициентов.
или,,. Здесьr12 — выборочный коэффициент корреляции между объясняющимипеременными X1 и X2; Sbj — стандартная ошибкакоэффициента регрессии; S — стандартная ошибка множественной регрессии (несмещенная оценка).По аналогии с парной регрессией после определения точечных оценокbj коэффициентов βj (j=1,2,…,m) теоретического уравнения множественной регрессии могут быть рассчитаны интервальные оценки указанных коэффициентов.
Доверительный интервал, накрывающий с надежностью (1-α) неизвестное значение параметра βj, определяется как
Расчет коэффициента корреляции
Теперь давайте попробуем посчитать коэффициент корреляции на конкретном примере. Имеем таблицу, в которой помесячно расписана в отдельных колонках затрата на рекламу и величина продаж. Нам предстоит выяснить степень зависимости количества продаж от суммы денежных средств, которая была потрачена на рекламу.
Способ 1: определение корреляции через Мастер функций
Одним из способов, с помощью которого можно провести корреляционный анализ, является использование функции КОРРЕЛ. Сама функция имеет общий вид КОРРЕЛ(массив1;массив2).
- Выделяем ячейку, в которой должен выводиться результат расчета. Кликаем по кнопке «Вставить функцию», которая размещается слева от строки формул.
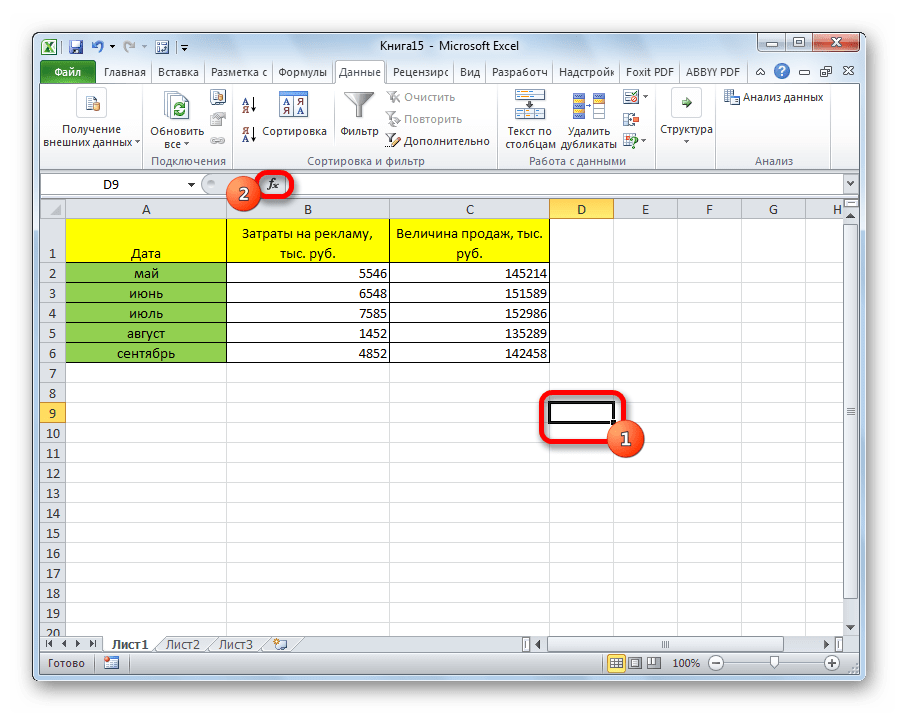
В списке, который представлен в окне Мастера функций, ищем и выделяем функцию КОРРЕЛ. Жмем на кнопку «OK».
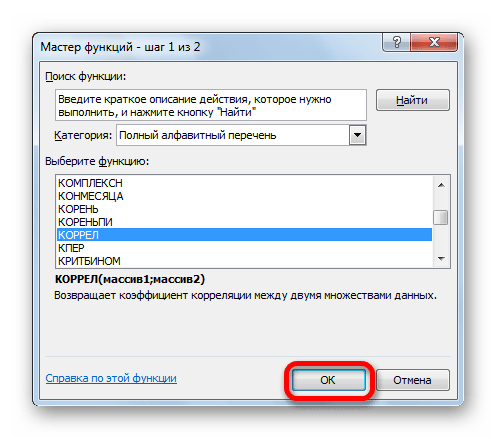
Открывается окно аргументов функции. В поле «Массив1» вводим координаты диапазона ячеек одного из значений, зависимость которого следует определить. В нашем случае это будут значения в колонке «Величина продаж». Для того, чтобы внести адрес массива в поле, просто выделяем все ячейки с данными в вышеуказанном столбце.
В поле «Массив2» нужно внести координаты второго столбца. У нас это затраты на рекламу. Точно так же, как и в предыдущем случае, заносим данные в поле.
Жмем на кнопку «OK».
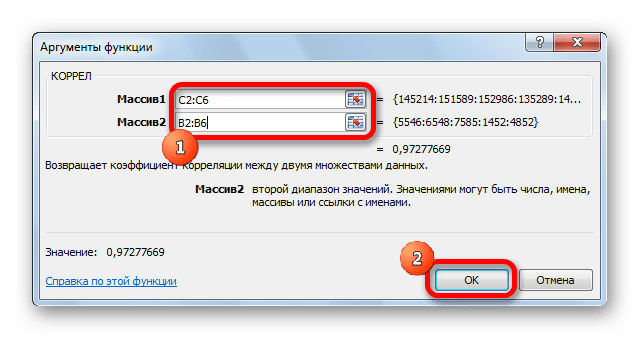
Как видим, коэффициент корреляции в виде числа появляется в заранее выбранной нами ячейке. В данном случае он равен 0,97, что является очень высоким признаком зависимости одной величины от другой.
Способ 2: вычисление корреляции с помощью пакета анализа
Кроме того, корреляцию можно вычислить с помощью одного из инструментов, который представлен в пакете анализа. Но прежде нам нужно этот инструмент активировать.
- Переходим во вкладку «Файл».
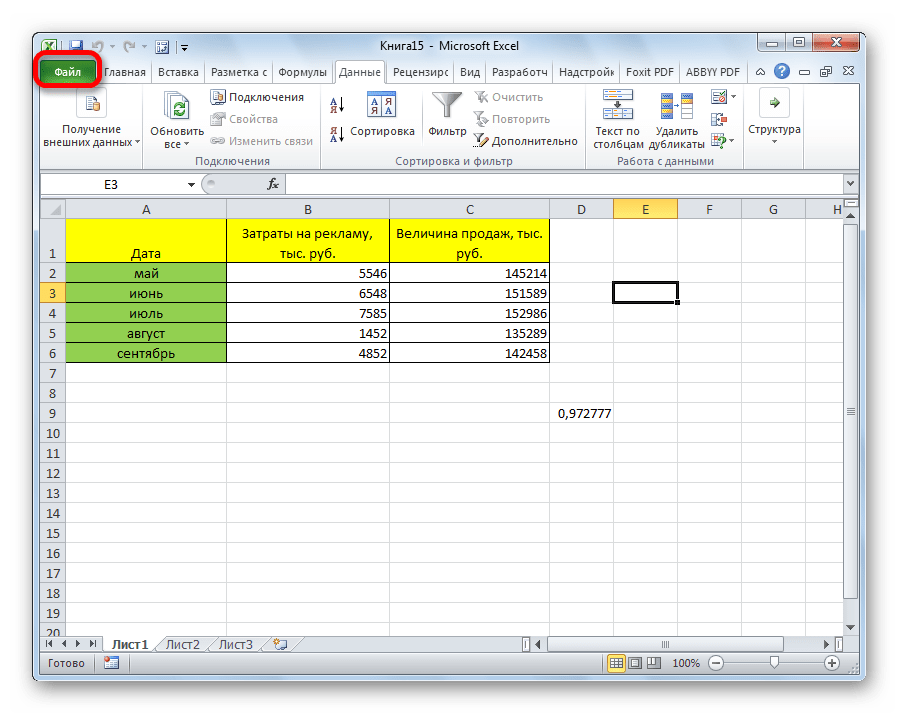
В открывшемся окне перемещаемся в раздел «Параметры».
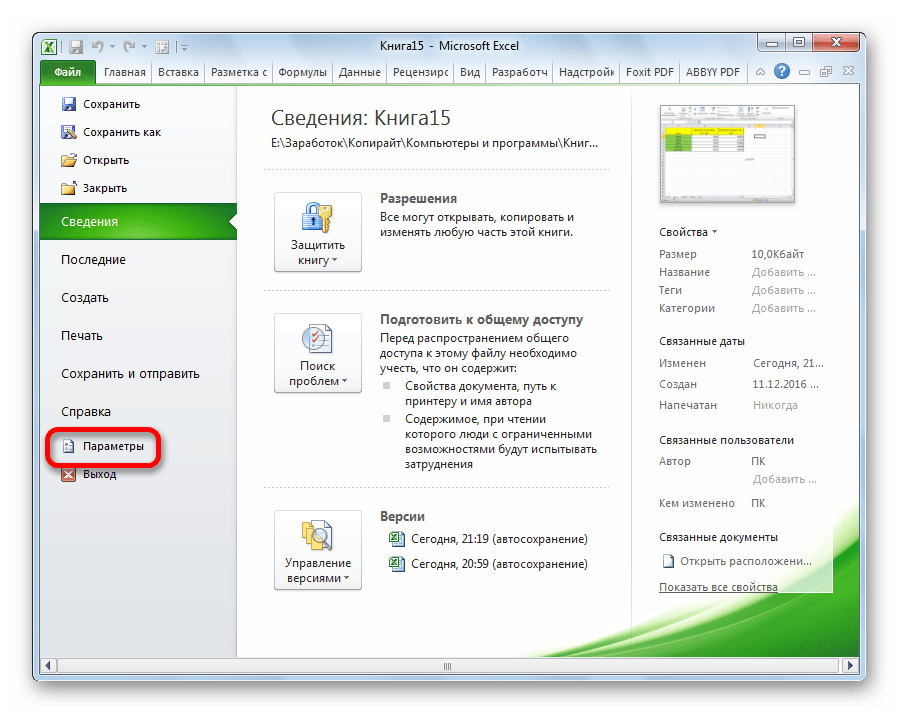
Далее переходим в пункт «Надстройки».
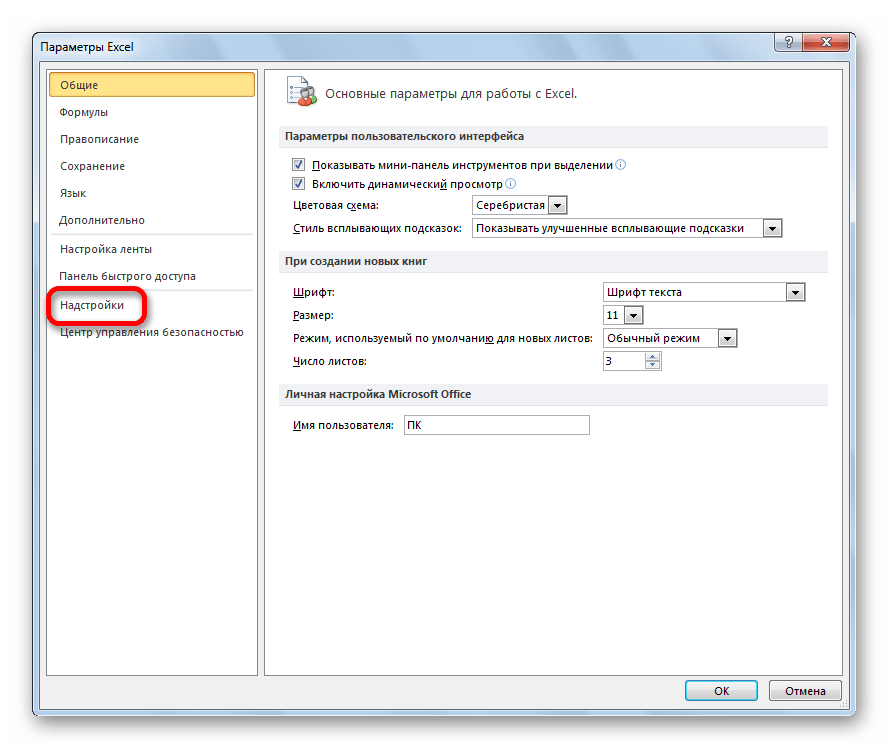
В нижней части следующего окна в разделе «Управление» переставляем переключатель в позицию «Надстройки Excel», если он находится в другом положении. Жмем на кнопку «OK».
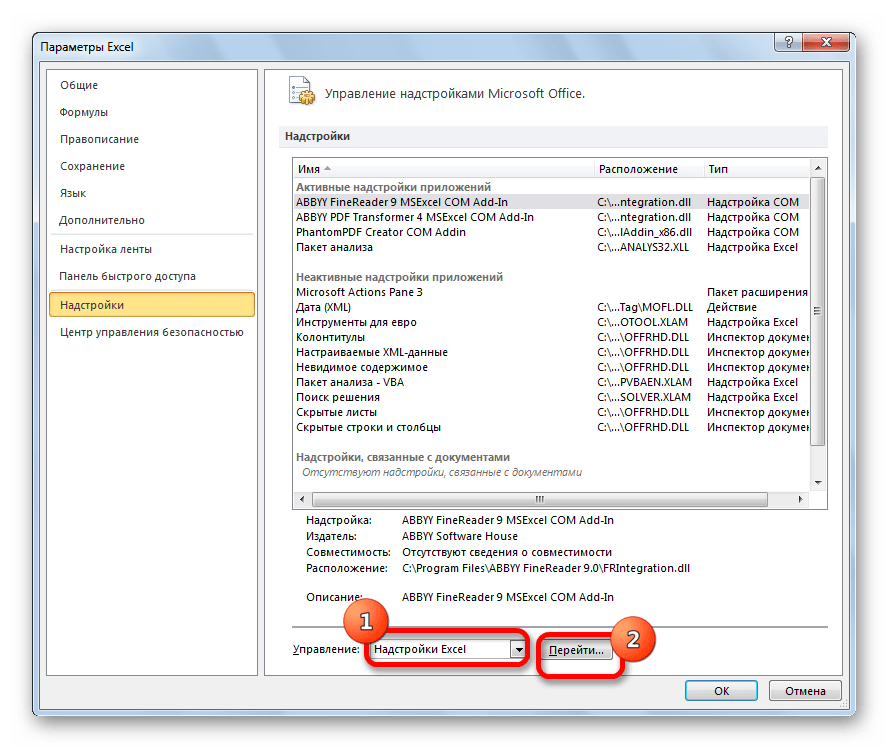
В окне надстроек устанавливаем галочку около пункта «Пакет анализа». Жмем на кнопку «OK».
После этого пакет анализа активирован. Переходим во вкладку «Данные». Как видим, тут на ленте появляется новый блок инструментов – «Анализ». Жмем на кнопку «Анализ данных», которая расположена в нем.
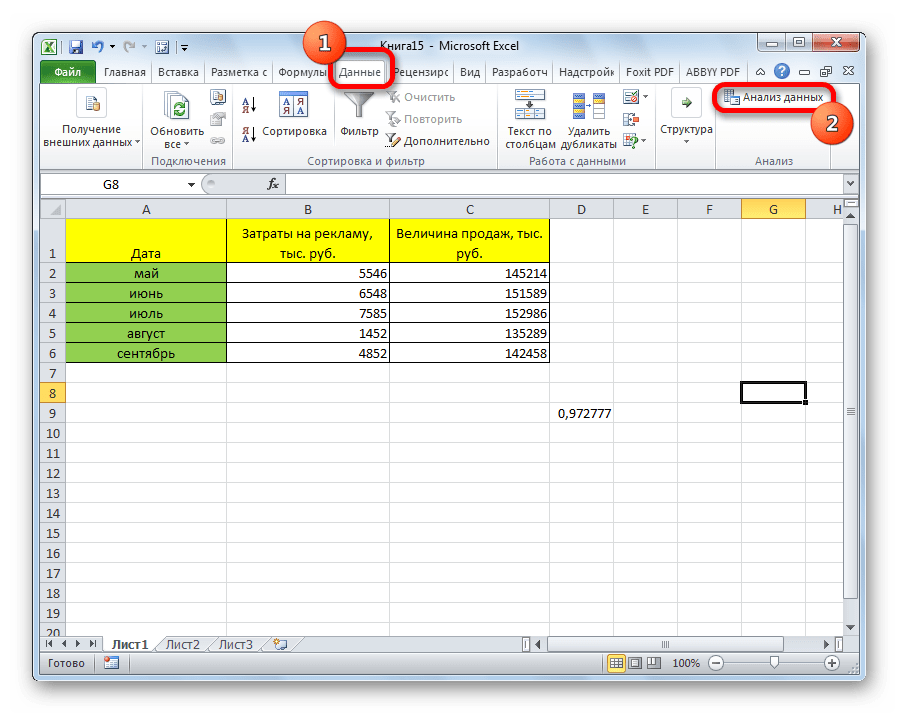
Открывается список с различными вариантами анализа данных. Выбираем пункт «Корреляция». Кликаем по кнопке «OK».
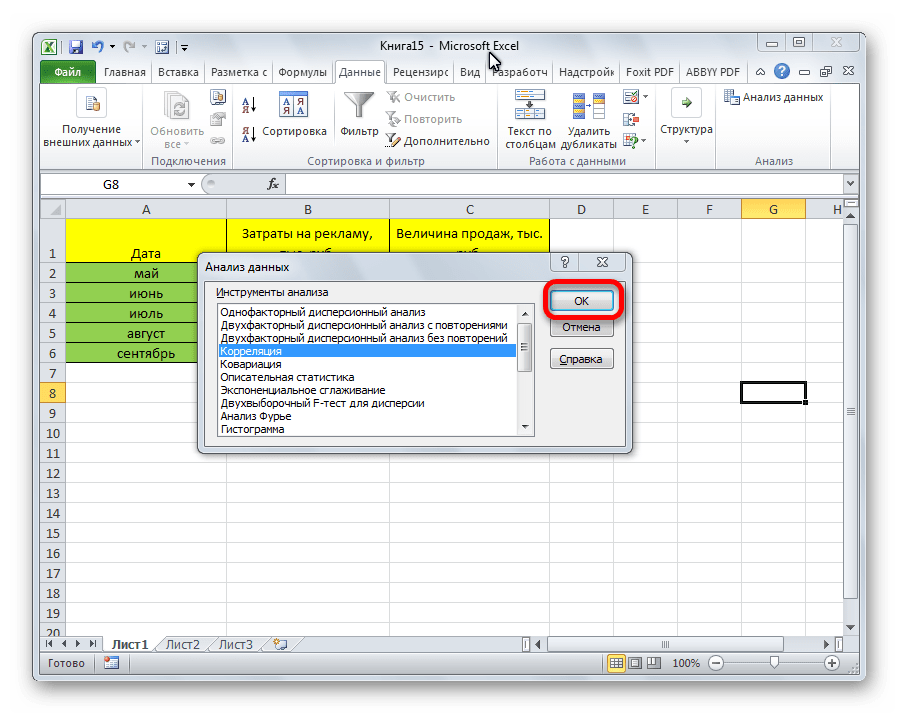
Открывается окно с параметрами корреляционного анализа. В отличие от предыдущего способа, в поле «Входной интервал» мы вводим интервал не каждого столбца отдельно, а всех столбцов, которые участвуют в анализе. В нашем случае это данные в столбцах «Затраты на рекламу» и «Величина продаж».
Параметр «Группирование» оставляем без изменений – «По столбцам», так как у нас группы данных разбиты именно на два столбца. Если бы они были разбиты построчно, то тогда следовало бы переставить переключатель в позицию «По строкам».
В параметрах вывода по умолчанию установлен пункт «Новый рабочий лист», то есть, данные будут выводиться на другом листе. Можно изменить место, переставив переключатель. Это может быть текущий лист (тогда вы должны будете указать координаты ячеек вывода информации) или новая рабочая книга (файл).
Когда все настройки установлены, жмем на кнопку «OK».
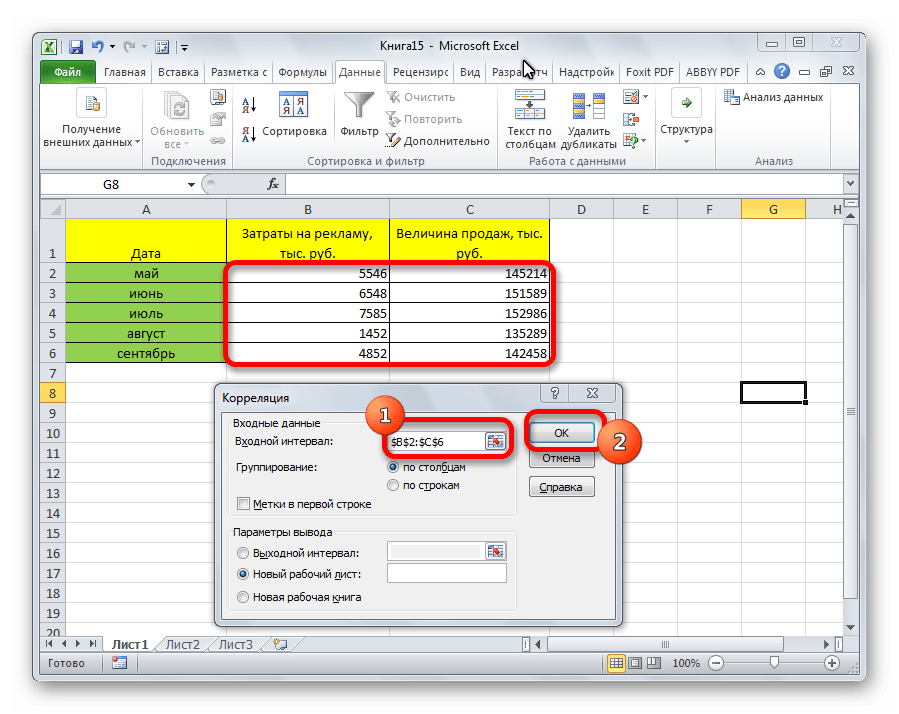
Так как место вывода результатов анализа было оставлено по умолчанию, мы перемещаемся на новый лист. Как видим, тут указан коэффициент корреляции. Естественно, он тот же, что и при использовании первого способа – 0,97. Это объясняется тем, что оба варианта выполняют одни и те же вычисления, просто произвести их можно разными способами.
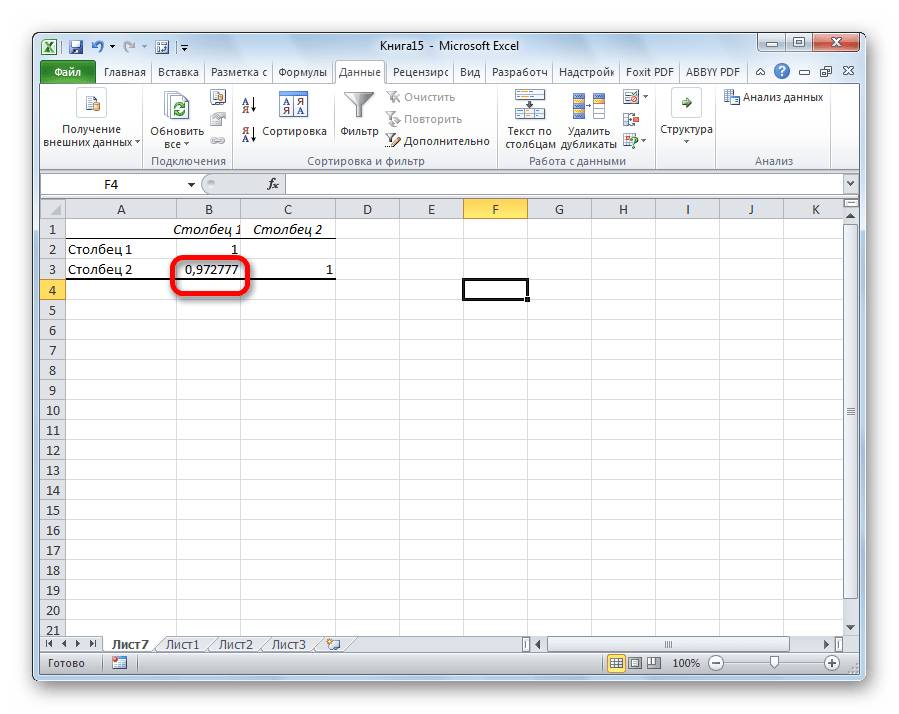
Как видим, приложение Эксель предлагает сразу два способа корреляционного анализа. Результат вычислений, если вы все сделаете правильно, будет полностью идентичным. Но, каждый пользователь может выбрать более удобный для него вариант осуществления расчета.
Опишите, что у вас не получилось.
Наши специалисты постараются ответить максимально быстро.
Разбор результатов анализа
Результаты регрессионного анализа выводятся в виде таблицы в том месте, которое указано в настройках.
Одним из основных показателей является R-квадрат. В нем указывается качество модели. В нашем случае данный коэффициент равен 0,705 или около 70,5%. Это приемлемый уровень качества. Зависимость менее 0,5 является плохой.
Ещё один важный показатель расположен в ячейке на пересечении строки «Y-пересечение» и столбца «Коэффициенты». Тут указывается какое значение будет у Y, а в нашем случае, это количество покупателей, при всех остальных факторах равных нулю. В этой таблице данное значение равно 58,04.
Значение на пересечении граф «Переменная X1» и «Коэффициенты» показывает уровень зависимости Y от X. В нашем случае — это уровень зависимости количества клиентов магазина от температуры. Коэффициент 1,31 считается довольно высоким показателем влияния.
Как видим, с помощью программы Microsoft Excel довольно просто составить таблицу регрессионного анализа. Но, работать с полученными на выходе данными, и понимать их суть, сможет только подготовленный человек.
Мы рады, что смогли помочь Вам в решении проблемы.
Помогла ли вам эта статья?
Да Нет
Метод линейной регрессии позволяет нам описывать прямую линию, максимально соответствующую ряду упорядоченных пар (x, y). Уравнение для прямой линии, известное как линейное уравнение, представлено ниже:
ŷ = a + bx
где:
ŷ — ожидаемое значение у при заданном значении х,
x — независимая переменная,
a — отрезок на оси y для прямой линии,
b — наклон прямой линии.
На рисунке ниже это понятие представлено графически:
На рисунке выше показана линия, описанная уравнением ŷ =2+0.5х. Отрезок на оси у — это точка пересечения линией оси у; в нашем случае а = 2. Наклон линии, b, отношение подъема линии к длине линии, имеет значение 0.5. Положительный наклон означает, что линия поднимается слева направо. Если b = 0, линия горизонтальна, а это значит, что между зависимой и независимой переменными нет никакой связи. Иными словами, изменение значения x не влияет на значение y.
Часто путают ŷ и у. На графике показаны 6 упорядоченных пар точек и линия, в соответствии с данным уравнением
ŷ = 2 + 0.5x
На этом рисунке показана точка, соответствующая упорядоченной паре х = 2 и у = 4
Обратите внимание, что ожидаемое значение у в соответствии с линией при х = 2 является ŷ. Мы можем подтвердить это с помощью следующего уравнения:
ŷ = 2 + 0.5х =2 +0.5(2) =3.
Значение у представляет собой фактическую точку, а значение ŷ — это ожидаемое значение у с использованием линейного уравнения при заданном значении х.
Следующий шаг — определить линейное уравнение, максимально соответствующее набору упорядоченных пар, об этом мы говорили в предыдущей статье, где определяли вид уравнения по методу наименьших квадратов.
Матрица парных коэффициентов корреляции в Excel
Корреляционная матрица представляет собой таблицу, на пересечении строк и столбцов которой находятся коэффициенты корреляции между соответствующими значениями. Имеет смысл ее строить для нескольких переменных.
Матрица коэффициентов корреляции в Excel строится с помощью инструмента «Корреляция» из пакета «Анализ данных».
Между значениями y и х1 обнаружена сильная прямая взаимосвязь. Между х1 и х2 имеется сильная обратная связь. Связь со значениями в столбце х3 практически отсутствует.
Где x·y , x , y — средние значения выборок; σ(x), σ(y) — среднеквадратические отклонения.
Кроме того, коэффициент линейной парной корреляции может быть определен через коэффициент регрессии b: , где σ(x)=S(x), σ(y)=S(y) — среднеквадратические отклонения, b — коэффициент перед x в уравнении регрессии y=a+bx .
Другие варианты формул:
или К xy — корреляционный момент (коэффициент ковариации)
Линейный коэффициент корреляции принимает значения от –1 до +1 (см. шкалу Чеддока). Например, при анализе тесноты линейной корреляционной связи между двумя переменными получен коэффициент парной линейной корреляции, равный –1 . Это означает, что между переменными существует точная обратная линейная зависимость.
Геометрический смысл коэффициента корреляции
Свойства коэффициента корреляции
- |r xy | ≤ 1;
- если X и Y независимы, то r xy =0, обратное не всегда верно;
- если |r xy |=1, то Y=aX+b, |r xy (X,aX+b)|=1, где a и b постоянные, а ≠ 0;
- |r xy (X,Y)|=|r xy (a 1 X+b 1 , a 2 X+b 2)|, где a 1 , a 2 , b 1 , b 2 – постоянные.
Инструкция
. Укажите количество исходных данных. Полученное решение сохраняется в файле Word
(см. Пример нахождения уравнения регрессии). Также автоматически создается шаблон решения в Excel
. .
1.Открыть программу Excel
2.Создать столбцы с данными. В нашем примере мы будем считать взаимосвязь, или корреляцию, между агрессивностью и неуверенностью в себе у детей-первоклассников. В эксперименте участвовали 30 детей, данные представлены в таблице эксель:
1 столбик — № испытуемого
2 столбик — агрессивность в баллах
3 столбик — неуверенность в себе в баллах
3.Затем необходимо выбрать пустую ячейку рядом с таблицей и нажать на значок f(x) в панели Excel
4.Откроется меню функций, среди категорий необходимо выбрать Статистические, а затем среди списка функций по алфавиту найти КОРРЕЛи нажать ОК
5.Затем откроется меню аргументов функции, которое позволит выбрать нужные нам столбики с данными. Для выбора первого столбика Агрессивность нужно нажать на синюю кнопочку у строки Массив1
6.Выберем данные для Массива1из столбика Агрессивность и нажмем на синюю кнопочку в диалоговом окне
7. Затем аналогично Массиву 1 нажмём на синюю кнопочку у строки Массив2
8.Выберем данные для Массива2 — столбик Неуверенность в себеи опять нажмем синюю кнопку, затем ОК
9.Вот, коэффициент корреляции r-Пирсона посчитан и записан в выбранной ячейке.В нашем случае он положительный и приблизительно равен 0,225. Это говорит об умеренной положительной связи между агрессивностью и неуверенностью в себе у детей-первоклассников
Таким образом, статистическим выводом эксперимента будет: r = 0,225, выявлена умеренная положительная взаимосвязь между переменными агрессивность и неуверенность в себе.
В некоторых исследованиях требуется указывать р-уровень значимости коэффициента корреляции, однако программа Excel, в отличие от SPSS, не предоставляет такой возможности. Ничего страшного, есть (А.Д. Наследов).
Также Вы можете и приложить её к результатам исследования.
Основные задачи и виды регрессии
Регрессия представляет собой зависимость между заданными переменными, за счет чего можно определить прогноз будущего поведения данных переменных. Переменные — это различные периодические явления, включая и поведение человека. Такой анализ программы Excel применяется для того, чтобы проанализировать воздействие на конкретную зависимую переменную значений одной или некоторым количеством переменных. К примеру, на продажи в магазине влияет несколько факторов, включая ассортимент, цены и место локализации магазина. Благодаря регрессии в Excel можно определять степень влияния каждого из указанных факторов по результатам имеющихся продаж, а после применить полученные данные для прогнозирования продаж на другой месяц или для другого магазина, расположенного рядом.
Обычно регрессия представлена в виде простого уравнения, раскрывающего зависимости и силу связи между двумя группами переменных, где одна группа является зависимой или эндогенной, а другая — независимой или экзогенной. При наличии группы взаимосвязанных показателей зависимая переменная Y определяется исходя из логики рассуждений, а остальные выступают в роли независимых Х-переменных.
Основные задачи построения регрессионной модели заключаются в следующем:
- Отбор значимых независимых переменных (Х1, Х2, …, Xk).
- Выбор вида функции.
- Построение оценок для коэффициентов.
- Построение доверительных интервалов и функции регрессии.
- Проверка значимости вычисленных оценок и построенного уравнения регрессии.
Регрессионный анализ бывает нескольких видов:
- парный (1 зависимая и 1 независимая переменные);
- множественный (несколько независимых переменных).
Уравнения регрессии бывает двух видов:
- Линейные, иллюстрирующие строгую линейную связь между переменными.
- Нелинейные — уравнения, которые могут включать степени, дроби и тригонометрические функции.
Инструкция построения модели
Чтобы выполнить заданное построение в Excel, необходимо следовать указаниям:

Для дальнейшего вычисления следует использоваться функцию «Линейн ()», указывая Значения Y, Значения Х, Конст и статистику. После этого определите множество точек на линии регрессии с помощью функции «Тенденция» — Значения Y, Значения Х, Новые значения, Конст. При помощи заданных параметров вычислите неизвестное значение коэффициентов, опираясь на заданные условия поставленной задачи.
КОРРЕЛЯЦИОННО-РЕГРЕССИОННЫЙ АНАЛИЗ В MS EXCEL
1. Создайте файл исходных данных в MS Excel (например, таблица 2)
2. Построение корреляционного поля
Для построения корреляционного поля в командной строке выбираем меню Вставка/ Диаграмма . В появившемся диалоговом окне выберите тип диаграммы: Точечная ; вид: Точечная диаграмма , позволяющая сравнить пары значений (Рис. 22).
Рисунок 22 – Выбор типа диаграммы
Рисунок 23– Вид окна при выборе диапазона и рядов Рисунок 25 – Вид окна, шаг 4
2. В контекстном меню выбираем команду Добавить линию тренда.
3. В появившемся диалоговом окне выбираем тип графика (в нашем примере линейная) и параметры уравнения, как показано на рисунке 26.
Нажимаем ОК. Результат представлен на рисунке 27.
Рисунок 27 – Корреляционное поле зависимости производительности труда от фондовооруженности
Аналогично строим корреляционное поле зависимости производительности труда от коэффициента сменности оборудования. (рисунок 28).

от коэффициента сменности оборудования
3. Построение корреляционной матрицы.
Для построения корреляционной матрицы в меню Сервис выбираем Анализ данных.
С помощью инструмента анализа данных Регрессия , помимо результатов регрессионной статистики, дисперсионного анализа и доверительных интервалов, можно получить остатки и графики подбора линии регрессии, остатков и нормальной вероятности. Для этого необходимо проверить доступ к пакету анализа. В главном меню последовательно выберите Сервис/ Надстройки . Установите флажок Пакет анализа (Рисунок 29)
Рисунок 30 – Диалоговое окно Анализ данных
После нажатия ОК в появившемся диалоговом окне указываем входной интервал (в нашем примере А2:D26), группирование (в нашем случае по столбцам) и параметры вывода, как показано на рисунке 31.

Результат расчетов представлен в таблице 4.
голоса
Рейтинг статьи
Использование MS EXCEL для расчета корреляции
В качестве примера возьмем 2 переменные Х и Y и, соответственно, выборку состоящую из нескольких пар значений (Хi; Yi). Для наглядности построим диаграмму рассеяния.
Примечание: Подробнее о построении диаграмм см. статью Основы построения диаграмм. В файле примера для построения диаграммы рассеяния использована диаграмма График, т.к. мы здесь отступили от требования случайности переменной Х (это упрощает генерацию различных типов взаимосвязей: построение трендов и заданный разброс). В случае реальных данных необходимо использовать диаграмму типа Точечная (см. ниже).
Расчеты корреляции проведем для различных случаев взаимосвязи между переменными: линейной, квадратичной и при отсутствии связи.
Примечание: В файле примера можно задать параметры линейного тренда (наклон, пересечение с осью Y) и степень разброса относительно этой линии тренда. Также можно настроить параметры квадратичной зависимости.
В файле примера для построения диаграммы рассеяния в случае отсутствия зависимости переменных использована диаграмма типа Точечная. В этом случае точки на диаграмме располагаются в виде облака.
Примечание: Обратите внимание, что изменяя масштаб диаграммы по вертикальной или горизонтальной оси, облаку точек можно придать вид вертикальной или горизонтальной линии. Понятно, что при этом переменные останутся независимыми. Как было сказано выше, для расчета коэффициента корреляции в MS EXCEL существует функций КОРРЕЛ()
Также можно воспользоваться аналогичной функцией PEARSON() , которая возвращает тот же результат
Как было сказано выше, для расчета коэффициента корреляции в MS EXCEL существует функций КОРРЕЛ() . Также можно воспользоваться аналогичной функцией PEARSON() , которая возвращает тот же результат.
Для того, чтобы удостовериться, что вычисления корреляции производятся функцией КОРРЕЛ() по вышеуказанным формулам, в файле примера приведено вычисление корреляции с помощью более подробных формул:
Примечание: Квадрат коэффициента корреляции r равен коэффициенту детерминации R2, который вычисляется при построении линии регрессии с помощью функции КВПИРСОН() . Значение R2 также можно вывести на диаграмме рассеяния, построив линейный тренд с помощью стандартного функционала MS EXCEL (выделите диаграмму, выберите вкладку Макет, затем в группе Анализ нажмите кнопку Линия тренда и выберите Линейное приближение). Подробнее о построении линии тренда см., например, в статье о методе наименьших квадратов.
Подключение пакета анализа
Но, для того, чтобы использовать функцию, позволяющую провести регрессионный анализ, прежде всего, нужно активировать Пакет анализа. Только тогда необходимые для этой процедуры инструменты появятся на ленте Эксель.
- Перемещаемся во вкладку «Файл».


Открывается окно параметров Excel. Переходим в подраздел «Надстройки».

В самой нижней части открывшегося окна переставляем переключатель в блоке «Управление» в позицию «Надстройки Excel», если он находится в другом положении. Жмем на кнопку «Перейти».


Теперь, когда мы перейдем во вкладку «Данные», на ленте в блоке инструментов «Анализ» мы увидим новую кнопку – «Анализ данных».

Регрессионный анализ в Excel
Показывает влияние одних значений (самостоятельных, независимых) на зависимую переменную. К примеру, как зависит количество экономически активного населения от числа предприятий, величины заработной платы и др. параметров. Или: как влияют иностранные инвестиции, цены на энергоресурсы и др. на уровень ВВП.
Результат анализа позволяет выделять приоритеты. И основываясь на главных факторах, прогнозировать, планировать развитие приоритетных направлений, принимать управленческие решения.
Регрессия бывает:
- линейной (у = а + bx);
- параболической (y = a + bx + cx2);
- экспоненциальной (y = a * exp(bx));
- степенной (y = a*x^b);
- гиперболической (y = b/x + a);
- логарифмической (y = b * 1n(x) + a);
- показательной (y = a * b^x).
Рассмотрим на примере построение регрессионной модели в Excel и интерпретацию результатов. Возьмем линейный тип регрессии.
Задача. На 6 предприятиях была проанализирована среднемесячная заработная плата и количество уволившихся сотрудников. Необходимо определить зависимость числа уволившихся сотрудников от средней зарплаты.
Модель линейной регрессии имеет следующий вид:
У = а0 + а1х1 +…+акхк.
Где а – коэффициенты регрессии, х – влияющие переменные, к – число факторов.
В нашем примере в качестве У выступает показатель уволившихся работников. Влияющий фактор – заработная плата (х).
В Excel существуют встроенные функции, с помощью которых можно рассчитать параметры модели линейной регрессии. Но быстрее это сделает надстройка «Пакет анализа».
Активируем мощный аналитический инструмент:
- Нажимаем кнопку «Офис» и переходим на вкладку «Параметры Excel». «Надстройки».
- Внизу, под выпадающим списком, в поле «Управление» будет надпись «Надстройки Excel» (если ее нет, нажмите на флажок справа и выберите). И кнопка «Перейти». Жмем.
- Открывается список доступных надстроек. Выбираем «Пакет анализа» и нажимаем ОК.
После активации надстройка будет доступна на вкладке «Данные».
Теперь займемся непосредственно регрессионным анализом.
- Открываем меню инструмента «Анализ данных». Выбираем «Регрессия».
- Откроется меню для выбора входных значений и параметров вывода (где отобразить результат). В полях для исходных данных указываем диапазон описываемого параметра (У) и влияющего на него фактора (Х). Остальное можно и не заполнять.
- После нажатия ОК, программа отобразит расчеты на новом листе (можно выбрать интервал для отображения на текущем листе или назначить вывод в новую книгу).
В первую очередь обращаем внимание на R-квадрат и коэффициенты. R-квадрат – коэффициент детерминации
В нашем примере – 0,755, или 75,5%. Это означает, что расчетные параметры модели на 75,5% объясняют зависимость между изучаемыми параметрами. Чем выше коэффициент детерминации, тем качественнее модель. Хорошо – выше 0,8. Плохо – меньше 0,5 (такой анализ вряд ли можно считать резонным). В нашем примере – «неплохо»
R-квадрат – коэффициент детерминации. В нашем примере – 0,755, или 75,5%. Это означает, что расчетные параметры модели на 75,5% объясняют зависимость между изучаемыми параметрами. Чем выше коэффициент детерминации, тем качественнее модель. Хорошо – выше 0,8. Плохо – меньше 0,5 (такой анализ вряд ли можно считать резонным). В нашем примере – «неплохо».
Коэффициент 64,1428 показывает, каким будет Y, если все переменные в рассматриваемой модели будут равны 0. То есть на значение анализируемого параметра влияют и другие факторы, не описанные в модели.
Коэффициент -0,16285 показывает весомость переменной Х на Y. То есть среднемесячная заработная плата в пределах данной модели влияет на количество уволившихся с весом -0,16285 (это небольшая степень влияния). Знак «-» указывает на отрицательное влияние: чем больше зарплата, тем меньше уволившихся. Что справедливо.
Коэффициент корреляции: что нужно знать, формула, пример расчёта в Excel
Приветствую всех читателей моего блога! Давненько я не писал статей по основам инвестирования. Сегодня хочу рассказать вам таком понятии как корреляция, которая имеет отношение к созданию качественного инвестиционного портфеля и диверсификации ваших вложений.
Если говорить о том, что такое корреляция простыми словами, то это по сути связь между двумя явлениями, выраженными в числовой форме. Например, проанализировав данные по ВВП на душу населения и продолжительности жизни в странах мира, мы невооруженным глазом заметим тенденцию:
А благодаря расчёту коэффициента корреляции мы можем узнать силу взаимосвязи в конкретном числовом выражении. Это очень удобно и полезно при анализе данных в самых разных областях науки, в том числе в экономике и инвестировании.
Сегодня я расскажу вам подробнее о том, что такое корреляция простыми словами, без сложных формул и терминов. Также я покажу вам, как правильно и легко рассчитать коэффициент корреляции в Excel и как правильно интерпретировать результаты, чтобы использовать их для составления инвестиционного портфеля.
А чтобы не пропускать следующие статьи блога, подписывайтесь на мой Телеграм-канал! Там же я выкладываю отчёты по инвестициям, сообщаю об обновлениях в моем инвест-портфеле и иногда пишу заметки на интересные темы. Даже чатик инвесторов у нас есть, присоединяйтесь
Анализ коэффициентов
Число 64,1428 показывает, каким будет значение Y, если все переменные xi в рассматриваемой нами модели обнулятся. Иными словами можно утверждать, что на значение анализируемого параметра оказывают влияние и другие факторы, не описанные в конкретной модели.
Следующий коэффициент -0,16285, расположенный в ячейке B18, показывает весомость влияния переменной Х на Y. Это значит, что среднемесячная зарплата сотрудников в пределах рассматриваемой модели влияет на число уволившихся с весом -0,16285, т. е. степень ее влияния совсем небольшая. Знак «-» указывает на то, что коэффициент имеет отрицательное значение. Это очевидно, так как всем известно, что чем больше зарплата на предприятии, тем меньше людей выражают желание расторгнуть трудовой договор или увольняется.
Другие виды регрессии
В примере, который представлен выше, используется только две переменных. Такая ситуация является скорее редкостью. Для расчета нескольких или разных показателей используют иные методы регрессии.
Множественная
Техника применяется в случае, когда параметров Х больше одного. Чтобы корректно рассчитать характеристики можно использовать дополнительные инструменты: заданный тренд, коэффициент детерминации, проверка гипотез и иные. Выполнить расчеты может только подготовленный специалист.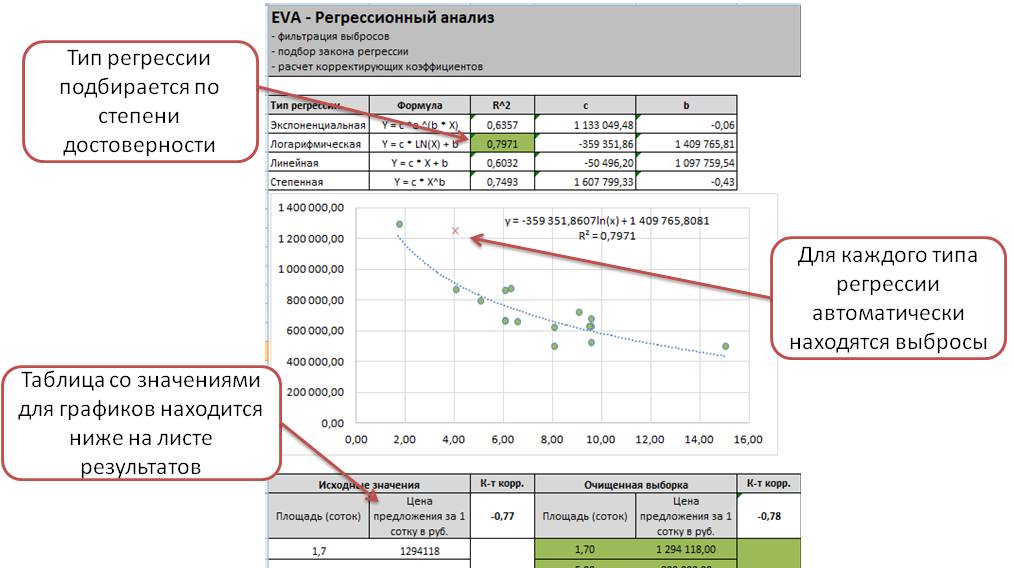
Степенная
Для этой модели формула расчета выглядит так: y = a*x˄b. Выбросы для данного метода вычисляются автоматически. Используется, если уровень достоверности техники выше остальных – графа R˄2.
Нелинейная
Для нелинейной методики важно рассчитать коэффициент корреляции. Характеристика указывает на наличие взаимосвязи различных показателей
Как правило, если параметр близок к единице, то взаимодействие есть, а анализ достаточно точный.
Дополнительным элементом является относительная ошибка. Характеристика должна находиться в пределах от 8% до 10% – значит, что расчеты точные и результаты можно использовать дальше.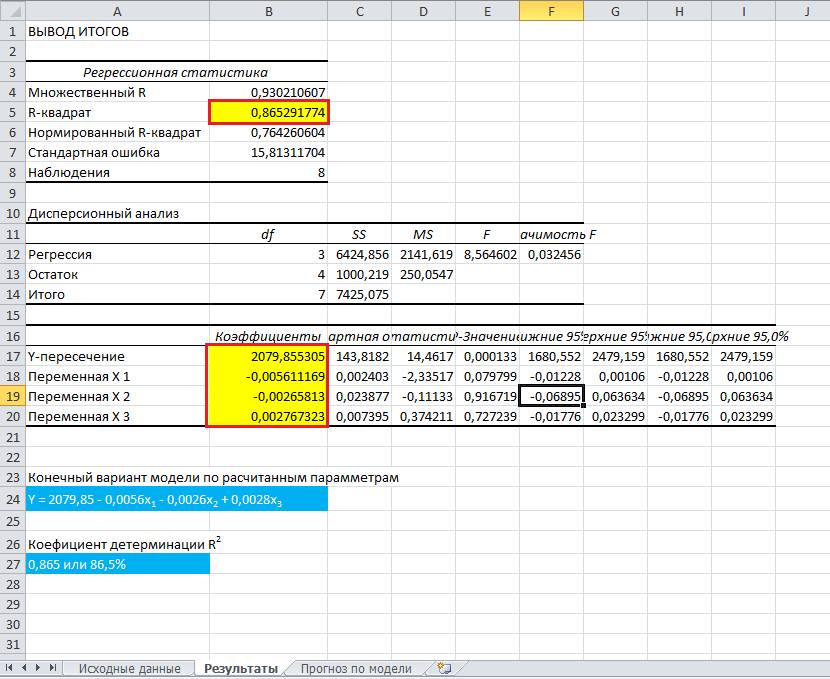
Кроме основных типов регрессионного анализа в Excel используют различные сочетания техник. К примеру, для исследования данных в банковской сфере, колебаний демографических показателей и других
Чтобы корректно пользоваться результатами, важно детально изучить механизм работы подобного исследования. Чаще всего обращаются к специалистам соответствующего профиля
Линейная регрессия в программе Excel
Внизу, в качестве примера, представлена таблица, в которой указана среднесуточная температура воздуха на улице, и количество покупателей магазина за соответствующий рабочий день. Давайте выясним при помощи регрессионного анализа, как именно погодные условия в виде температуры воздуха могут повлиять на посещаемость торгового заведения.
Общее уравнение регрессии линейного вида выглядит следующим образом: У = а0 + а1х1 +…+акхк . В этой формуле Y означает переменную, влияние факторов на которую мы пытаемся изучить. В нашем случае, это количество покупателей. Значение x – это различные факторы, влияющие на переменную. Параметры a являются коэффициентами регрессии. То есть, именно они определяют значимость того или иного фактора. Индекс k обозначает общее количество этих самых факторов.
- Кликаем по кнопке «Анализ данных». Она размещена во вкладке «Главная» в блоке инструментов «Анализ».

Открывается небольшое окошко. В нём выбираем пункт «Регрессия». Жмем на кнопку «OK».

Открывается окно настроек регрессии. В нём обязательными для заполнения полями являются «Входной интервал Y» и «Входной интервал X». Все остальные настройки можно оставить по умолчанию.
В поле «Входной интервал Y» указываем адрес диапазона ячеек, где расположены переменные данные, влияние факторов на которые мы пытаемся установить. В нашем случае это будут ячейки столбца «Количество покупателей». Адрес можно вписать вручную с клавиатуры, а можно, просто выделить требуемый столбец. Последний вариант намного проще и удобнее.
В поле «Входной интервал X» вводим адрес диапазона ячеек, где находятся данные того фактора, влияние которого на переменную мы хотим установить. Как говорилось выше, нам нужно установить влияние температуры на количество покупателей магазина, а поэтому вводим адрес ячеек в столбце «Температура». Это можно сделать теми же способами, что и в поле «Количество покупателей».

С помощью других настроек можно установить метки, уровень надёжности, константу-ноль, отобразить график нормальной вероятности, и выполнить другие действия. Но, в большинстве случаев, эти настройки изменять не нужно
Единственное на что следует обратить внимание, так это на параметры вывода. По умолчанию вывод результатов анализа осуществляется на другом листе, но переставив переключатель, вы можете установить вывод в указанном диапазоне на том же листе, где расположена таблица с исходными данными, или в отдельной книге, то есть в новом файле

После того, как все настройки установлены, жмем на кнопку «OK».

Изучение результатов и выводы
«Собираем» из округленных данных, представленных выше на листе табличного процессора Excel, уравнение регрессии:
СП = 0,103*СОФ + 0,541*VO – 0,031*VK +0,405*VD +0,691*VZP – 265,844.
В более привычном математическом виде его можно записать, как:
y = 0,103*x1 + 0,541*x2 – 0,031*x3 +0,405*x4 +0,691*x5 – 265,844
Данные для АО «MMM» представлены в таблице:
Подставив их в уравнение регрессии, получают цифру в 64,72 млн американских долларов. Это значит, что акции АО «MMM» не стоит приобретать, так как их стоимость в 70 млн американских долларов достаточно завышена.
Как видим, использование табличного процессора «Эксель» и уравнения регрессии позволило принять обоснованное решение относительно целесообразности вполне конкретной сделки.
Теперь вы знаете, что такое регрессия. Примеры в Excel, рассмотренные выше, помогут вам в решение практических задач из области эконометрики.
Регрессионный анализ является одним из самых востребованных методов статистического исследования. С его помощью можно установить степень влияния независимых величин на зависимую переменную. В функционале Microsoft Excel имеются инструменты, предназначенные для проведения подобного вида анализа. Давайте разберем, что они собой представляют и как ими пользоваться.
Но, для того, чтобы использовать функцию, позволяющую провести регрессионный анализ, прежде всего, нужно активировать Пакет анализа. Только тогда необходимые для этой процедуры инструменты появятся на ленте Эксель.
Теперь, когда мы перейдем во вкладку «Данные», на ленте в блоке инструментов «Анализ» мы увидим новую кнопку – «Анализ данных».




