Noindex и nofollow: как, зачем и для чего используют в seo
Содержание:
- Yapılandırılmış veriyi kullanma
- Что делать если вы обнаружили на статье мета-тег
- How to avoid crawlability and (de)indexation mistakes
- Meta name robots index и follow
- Тег и атрибут rel=“nofollow”
- Для чего нужен атрибут rel nofollow
- Правила применения и зачем нужен nofollow?
- Практическая реализация заголовка X-Robots-Tag
- Тег и как его применять
- SEO best practices with robots meta directives
- Мета-тег
- data-nosnippet HTML özelliğini kullanma
- Что такое мета тег Robots
- Нужно ли удалять публикации, отмеченные мета-тегом с канала
- Как использовать noindex и nofollow в meta robots
- Что писать в теге meta description?
- Мета-тег
- Why is the robots meta tag important for SEO?
- Common Meta Robots Mistakes
- What Are Robots Meta Tags?
- Использование структурированных данных
- Выводы
Yapılandırılmış veriyi kullanma
Robots meta etiketleri, Google’ın arama sonuçları olarak görüntülemek üzere web sayfalarından otomatik olarak ayıkladığı içerik miktarını belirler. Ancak, birçok yayıncı, belirli bilgileri arama sunumu için kullanılabilir hale getirmek amacıyla schema.org yapılandırılmış verilerini de kullanır. Robots meta etiketi sınırlamaları, diğer reklam öğeleri için belirtilen yapılandırılmış verinin ve değerleri dışında bu yapılandırılmış verilerin kullanımını etkilemez. Bu değerlerine dayalı önizleme maksimum uzunluğunu belirtmek için robots meta etiketini kullanın. Örneğin, bir sayfadaki yapılandırılmış verisi, metin önizlemesi başka türlü sınırlandırılacak olsa bile, yemek tarifi bandına dahil edilmeye uygundur. Bir metin önizlemesinin uzunluğunu ile sınırlayabilirsiniz ancak zengin sonuçlar için bilgiler yapılandırılmış veri kullanılarak sağlandığında, robots meta etiketi geçerli olmaz.
Web sayfalarınızla ilgili yapılandırılmış verilerin kullanımını yönetmek için bilgiler ekleyerek veya kaldırarak yapılandırılmış veri türlerini ve değerlerin kendilerini değiştirin. Bu şekilde, yalnızca sunmak istediğiniz verileri sağlamış olursunuz. Ayrıca, yapılandırılmış verilerin, bir öğesi içinde belirtildiklerinde arama sonuçları için kullanılabilir durumda kalacaklarını unutmayın.
Что делать если вы обнаружили на статье мета-тег
Ещё раз подчеркну, что наличие мета-тега — норма на новых, не прошедших модерацию каналов. Проверка (или, как говорят, «выход на алл») может занять какое-то время. Иногда каналы успевают достигнуть порога монетизации, в этом случае монетизация не будет подключена до прохождения проверки.
Если канал не новый, то возможны разные ситуации:
- Иногда мета-тег снимается простым переопубликованием (т.е. нужно отредактировать и снова её опубликовать, ничего не меняя).
- Если это не помогло, то высока вероятность того, что статья ограничена (возможно ошибочно). В этом случае поможет только обращение в службу поддержки Дзена, правда добиться этого не всегда бывает просто.
How to avoid crawlability and (de)indexation mistakes
You want to show all valuable pages, avoid duplicate content, issues and keep specific pages out of the index. If you manage a huge website then crawl budget management is another thing to pay attention to.
Let’s have a look at the most common mistakes people make regarding robots directives.
Mistake #1: Adding noindex directives to pages disallowed in robots.txt
Never disallow crawling of content that you’re trying to get deindexed in robots.txt. Doing so prevents search engines from recrawling the page and discovering the noindex directive.
If you feel you may have made that mistake in the past, crawl your site with Ahrefs Site Audit. Look for pages with “Noindex page receives organic traffic” errors.
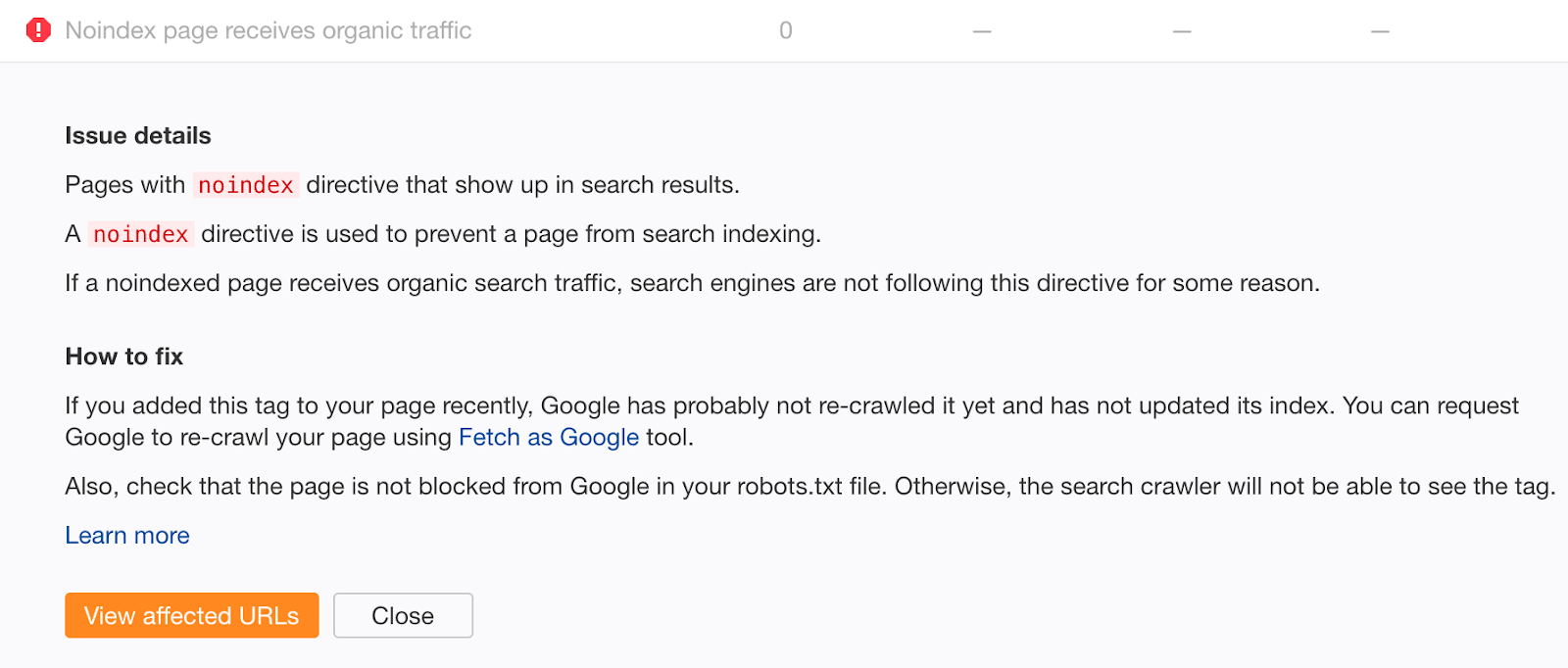
Noindexed pages that receive organic traffic are clearly still indexed. If you didn’t add the noindex tag recently, chances are this is due to a crawl block in your robots.txt file. Check for issues and fix them as appropriate.
Mistake #2: Bad sitemaps management
If you’re trying to get content deindexed using a meta robots tag or x‑robots-tag, don’t remove it from your sitemap until it’s been successfully deindexed. Otherwise, Google may be slower to recrawl the page.
To potentially speed up the deindexing process further, set the lastmod date in your sitemap to the date you added the noindex tag. This encourages recrawling and reprocessing.
Sidenote. John is talking about 404 pages here. That said, we’re assuming that this also makes sense for other changes like when you add or remove a noindex directive.
IMPORTANT NOTE
Don’t include noindexed pages in your sitemap in the long-term. Once content has been deindexed, remove it from your sitemap.
If you’re worried that old, successfully deindexed content may still exist in your sitemap, check the “Noindex page sitemap” error in Ahrefs Site Audit.
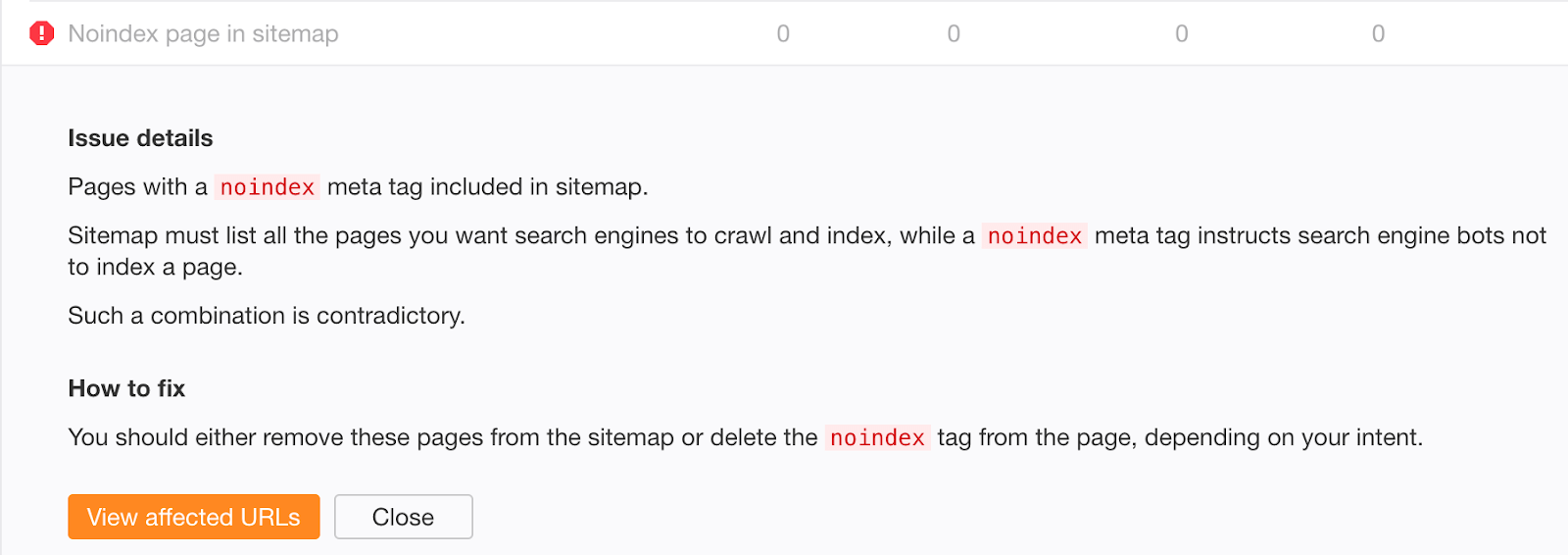
Mistake #3: Not removing noindex directives from the production environment
Preventing robots from crawling and indexing anything in the staging environment is a good practice. However, it sometimes gets pushed into production, forgotten, and your organic traffic plunges.
Even worse, the organic traffic drop might not be that noticeable if you’re involved in a site migration using 301 redirects. If the new URLs contain the noindex directive or are disallowed in robots.txt, you’ll still receive organic traffic from the old ones for some time. It can take Google up to a few weeks to deindex the old URLs.
Whenever there are such changes on your website, keep an eye on the “Noindex page” warnings in Ahrefs Site Audit:
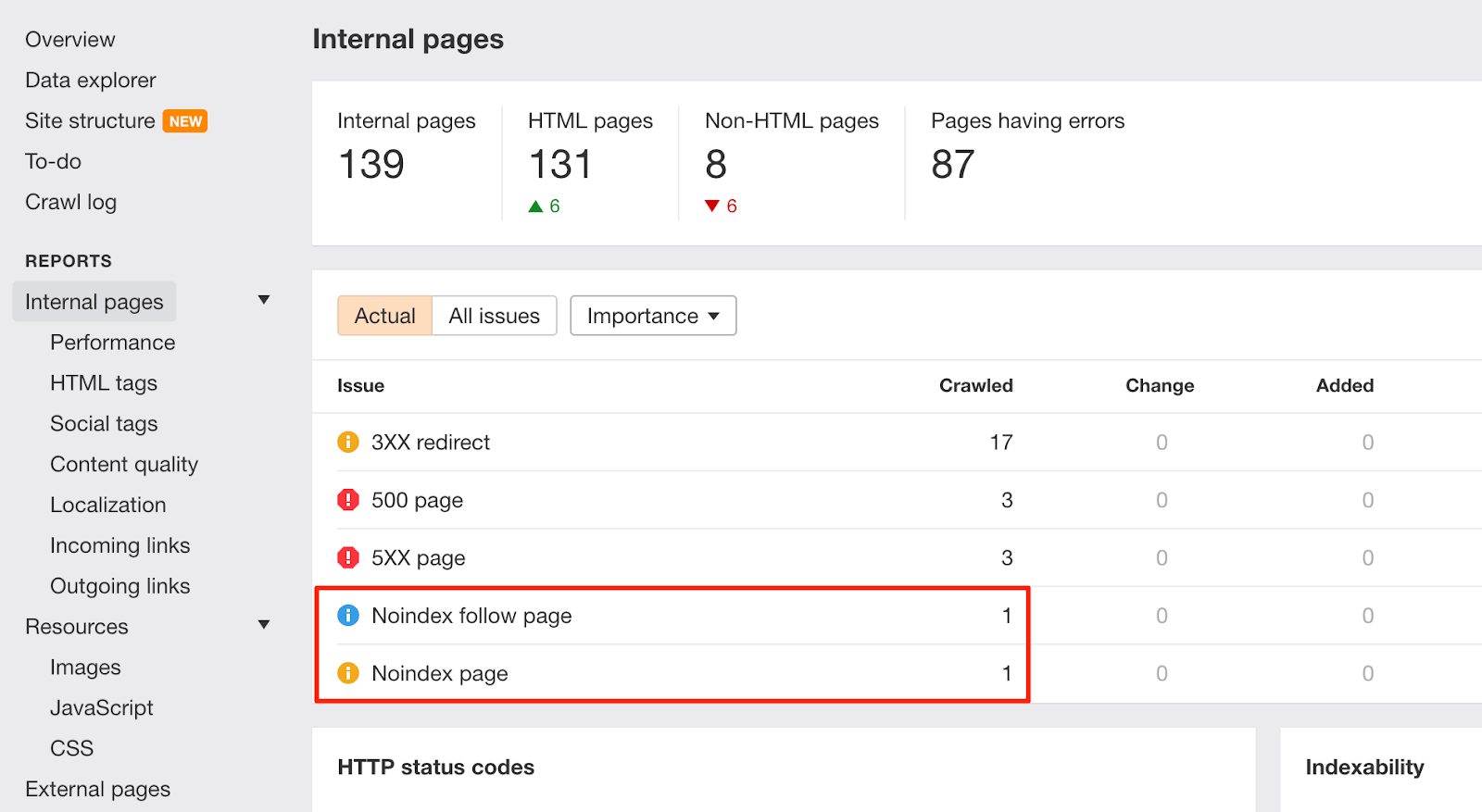
To help prevent similar issues in the future, enrich the dev team’s checklist with instructions for removing disallow rules from robots.txt and noindex directives before pushing to production.
Mistake #4: Adding “secret” URLs to robots.txt instead of noindexing them
Developers often try to hide pages about upcoming promotions, discounts, or product launches by disallowing access to them in the site’s robots.txt file. This is bad practice because humans can still view a robots.txt file. As such, these pages are easily leaked.
Fix this by keeping “secret” pages out of robots.txt and noindexing them instead.
Meta name robots index и follow
Чтобы одновременно можно было переходить индексировать страницу и переходить по ссылкам следует записать:
<meta name=»robots» content=»index, follow»>
Чтобы не заносить в базу данных поисковой машины картинки пишут:
<meta name=»robots» content=»noimageindex»>
Meta name robots content noarchive
Поисковые машины Google и Yandex для каждого сканируемого сайта, делают и сохраняют его снимок. Архивированный вариант хранится в кэше, что дает возможность поисковику отображать эту страницу по специальной ссылке в результатах поиска, когда она по каким-то техническим причинам недоступна. Веб-страница, хранимая в кэше, отображается такой, какой она была в тот момент, когда ее сохранил поисковый робот. О том, что пользователь просматривает кэшированную страницу говорит сообщение в верхней части сайта. Можно обратиться к кэш-версии страницы, нажав на кнопку «сохранено в кэше», в результатах поиска.
Если вы не желаете, чтобы в поисковых системах была подобная ссылка, можно дописать в head такой тег:
<meta name=»robots» content=»noarchive»>
Для того чтобы кнопка «Сохранено в кэше» не выводилась в определенной поисковой системе можно написать:
<meta name=»имя_робота» content=»noarchive»>
Такая запись убирает только ссылку «Сохранено» на архивированную страницу, поисковая система и дальше будет индексировать сайт и отображать его фрагмент.
Тег и атрибут rel=“nofollow”
Давайте взглянем на тот случай, когда такая комбинация нецелесообразна.
Зачем использовать тег <noindex> и атрибут rel=”nofollow” вместе?
В случае, когда мы хотим скрыть от индексации и сделать текст внутри ссылки невидимым для таких поисковых систем как Yandex и Rambler(подробнее о разных поисковиках читайте выше). Google же прочитает название ссылки, но не внесет ее в свой index благодаря атрибуту rel=”nofollow”.
Вместе это выглядит так:
<noindex><a href="http://mysite.com/" rel="nofollow">название ссылки</a></noindex>
Мы видим, как ссылку с атрибутом rel=”nofollow” обернули в тег <noindex>. Это верный способ написания кода.
Для чего нужен атрибут rel nofollow
<a href =”http://website.ru” rel=”nofollow”>скрытая ссылка</a>
Зеленые вебмастера, которые впервые узнали о рел нофоллоу, сразу думают: «Отлично! Теперь я всем ссылкам его пропишу и вес не будет утекать никуда».
На самом деле поисковик вполне себе переходит по ссылкам с этим атрибутом и они вполне себе забирают ссылочный вес у ваших страниц. То есть смысла в этом атрибуте, как и в noindex, нет. Ссылки закрывать эффективно только через Ajax, да и это я думаю не навсегда
Но, если же вы все-таки решили сконцентрировать внимание на этой точке, которая в лучшем случае даст вам микроскопический рост, то вот еще один видос от ТопЭксперт:
Правила применения и зачем нужен nofollow?
Чтобы понять, в каких случаях может вообще пригодиться этот атрибут,
рассмотрим, как к нему относятся популярнейшие поисковые системы.
Яндекс
Когда на вашем ресурсе содержатся разделы, предназначенные специально для обсуждения записей, написания комментариев к статьям или форум, важно следить за тем, какие исходящие ссылки оставляют в них посетители. Желательно модерировать каждый комментарий
Благодаря этому владелец сайта сможет предотвратить размещение различных вредоносных ссылок от спамеров. Хотя поисковик и не учитывает их, спам сильно влияет на репутацию веб-ресурса и к нему может быть применен фильтр. В связи с этим следует проверять все комментарии, и если есть какие-то сомнения относительно качества размещаемой ссылки, пропишите для них атрибут rel=”nofollow”. Сейчас, в измененном руководстве Яндекс, данный текст был удален и осталось только правило применения rel=»nofollow» Руководство Яндекс о nofollow
Если у вашего сайта есть раздел, где пользователи могут комментировать записи, есть большой риск, что в комментариях появятся ссылки на вредоносные страницы. Спамеры «любят» сайты с комментариями без модерации. Атрибут nofollow для спам-ссылок спасет ваш ресурс и сохранит его чистую репутацию в глазах поисковой системы. Если же вы доверяете сайту, на который ссылается посетитель или вы сами ссылаетесь, то нет необходимости прописывать nofollow. Руководство Google о nofollow
Эти сообщения взяты с официальных сайтов поисковиков. Как видите, в Яндекс и Google написаны аналогичные вещи: значение nofollow нужно использовать в тех случаях, когда вы хотите сообщить ботам о недоверии в отношении сайта, на который ведет ссылка.
Только в Яндекс упор делается, что ссылка с rel=»nofollow» не будет индексироваться поисковой системой, а в Google говорится о том, что робот не будет переходить по такой ссылке.
Рассмотрим более конкретный пример, когда для ссылки требуется прописать запрещающий атрибут:
Материал сомнительного качества. Если вам не нравится содержание страницы, на которую посетитель оставляет ссылку в комментарии, и вы не желаете жертвовать репутацией своего сайта, прописывайте в теги данной ссылки значение rel=”nofollow”. Спамеры, заметив на вашем ресурсе тенденцию, когда к непроверенным ссылкам добавляется блокирующий атрибут, вскоре прекратят попытки навредить сайту. Если же вы видите, что пользователь оставляет ссылку на качественный материал, вручную или автоматически nofollow можно удалить.
Вам может быть интересна эта статья: Как ускорить индексацию сайта — подборка всех эффективных способов
Практическая реализация заголовка X-Robots-Tag
Заголовок можно добавить в HTTP-ответы с помощью файлов конфигурации в серверном ПО сайта. Например, на серверах Apache такие настройки хранятся в файлах .htaccess и httpd.conf. Преимущество использования заголовка в HTTP-ответах состоит в том, что с его помощью можно задать директивы сканирования на уровне всего сайта, а поддержка регулярных выражений обеспечивает дополнительную гибкость.
Например, чтобы добавить заголовок с директивой в HTTP-ответ для PDF-файлов со всего сайта, включите небольшой фрагмент кода в корневой файл .htaccess/httpd.conf (Apache) или .conf (NGINX).
Apache:
<Files ~ "\.pdf$"> Header set X-Robots-Tag "noindex, nofollow" </Files>
NGINX:
location ~* \.pdf$ {
add_header X-Robots-Tag "noindex, nofollow";
}
Заголовки можно использовать для тех файлов, для которых HTML-метатеги robots недоступны, например для изображений. В приведенном ниже примере директива добавляется для файлов изображений (.png, .jpeg, .jpg, .gif) на всём сайте:
Apache:
<Files ~ "\.(png|jpe?g|gif)$"> Header set X-Robots-Tag "noindex" </Files>
NGINX:
location ~* \.(png|jpe?g|gif)$ {
add_header X-Robots-Tag "noindex";
}
Заголовки также можно задать для отдельных статических файлов.
Apache:
# the htaccess file must be placed in the directory of the matched file. <Files "unicorn.pdf"> Header set X-Robots-Tag "noindex, nofollow" </Files>
NGINX:
location = /secrets/unicorn.pdf {
add_header X-Robots-Tag "noindex, nofollow";
}
Тег и как его применять
Тег — это структурная единица HTML разметки, а все что внутри, называют содержанием элемента.
Что такое тег <noindex>?
<noindex> — тег, который используется для закрытия определенных участков текста. Контент внутри будет недоступен для индексации поисковыми системами, такими как Yandex и Rambler. То есть, с его помощью, мы запрещаем боту сканировать часть контента. Эту конструкцию правильно использовать внутри <body></body> в таком виде:
<noindex>нас не увидят</noindex>
Важно помнить: не стандартизирован компанией Google и не относится к официальной разметке HTML. Поэтому, будет вызывать ошибки в коде
Так как Google этот тег не знает, то и скрыть контент от индексации не сможет.
Валидность HTML сохраняется с использованием специальной конструкции:
<!--noindex-->Мы спрятались 0_0<!--/noindex-->
Когда использовать?
На тот случай, когда мы не хотим затрагивать основной контент страницы, а только скрыть определенные служебные участки текста. Тогда на помощь приходить тег который не разрешит поисковикам добавить выбранный участок в индексную базу.
“А смысл нам что-то скрывать?” — спросите вы.
А поисковый робот ответит: “Берегите уникальность своего контента и это вернется вам высокими позициями в выдаче”.
Поисковые системы любят сайты с уникальным наполнением и за это благодарят их высокими позициями в выдаче. На ранжирование влияет ряд негативных факторов:
- выдержки из законодательства;
- цитирование чужих авторов;
- служебный контент на вашем ресурсе;
- периодически дублирующий текст;
- сохранить контент от переспама ключевыми словами для Yandex и Rambler.
SEO best practices with robots meta directives
-
All meta directives (robots or otherwise) are discovered when a URL is crawled. This means that if a robots.txt file disallows the URL from crawling, any meta directive on a page (either in the HTML or the HTTP header) will not be seen and will, effectively, be ignored.
-
In most cases, using a meta robots tag with parameters «noindex, follow» should be employed as a way to to restrict crawling or indexation instead of using robots.txt file disallows.
-
It is important to note that malicious crawlers are likely to completely ignore meta directives and as such, this protocol does not make a good security mechanism. If you have private information that you don’t want to make publicly searchable, choose a more secure approach, such as password protection, to keep visitors from viewing confidential pages.
-
You do not need to use both meta robots and the x-robots-tag on the same page – doing so would be redundant.
Мета-тег
Начнем с базовых пониманий. Мета-тег — это служебная информация для страницы, которая указывается в документе в верхнем блоке <head></head> с HTML разметкой.
Что такое мета-тег robots?
В нашем случае, мета-тег с атрибутом name=“robots” дает указание роботам всех поисковых систем, без исключения. Так же, есть name=“googlebot”, виден только Google, и name=“yandex”, соответственно только для Yandex поисковика.
В коде это выглядит так:
<!DOCTYPE html> <html><head> <meta name="robots" content="noindex" /> (…) </head> <body>(…)</body> </html>
Атрибут content может принимать такие параметры как:
- “noindex” — ставит запрет на индексацию контента, но ссылки в документе все еще видны для поисковых роботов и открыты для просмотров и переходов на них
- “nofollow” — закрывает все ссылки на данной странице от индексации. Это касается как внешних, так и внутренних.
Варианты использования meta тега robots с noindex и nofollow
Возможны такие варианты использования:
<meta name="robots" content="index, follow"/> <!-- — включена индексация страницы и ссылок. Стоит по умолчанию для каждого сайта. --> <meta name="robots" content="noindex, follow"/> <!-- — запрет на индексацию контента страницы, но разрешен переход и просмотр ссылок. --> <meta name="robots" content="index, nofollow"/> <!-- — включена индексация, но запрещен переход и просмотр ссылок. --> <meta name="robots" content="noindex, nofollow"/> <!-- — запрет на индексацию и переход по ссылкам страницы. -->
Перечисленные варианты также можно использовать для скрытия от определенных поисковых систем, таких как Yandex и Google. Возможные варианты атрибута name видно выше, а в коде это может выглядеть так:
<meta name="googlebot" content="noindex, follow" />.
Стоит подбирать комбинацию атрибутов четко под свои цели и задачи. Давайте рассмотрим некоторые из них.
Когда нам нужен мета-тег “robots” со значением “noindex” или “nofollow”?
Мета-тег следует использовать на следующих страницах:
- со служебной информацией(админ. панель, логи сервера);
- дублирующийся контент(пагинация, архивы, теги).
А также в случаях:
- когда следует закрыть страницу от индексирования, но оставить возможность просматривать ссылки;
- когда хотите удалить документ из index и не допустить просмотра ссылок поисковыми роботами;
- когда нужно закрыть переход по ссылкам уже индексированного документа.
Рекомендуем
Операторы поиска Google
Подробнее
data-nosnippet HTML özelliğini kullanma
Bir HTML sayfasının snippet’i olarak kullanılmayacak metin bölümlerini tanımlayabilirsiniz. Bu işlem , , öğelerinde HTML özelliği ile HTML öğesi düzeyinde yapılabilir. , bir olarak kabul edilir.
Tüm boole özelliklerinde olduğu gibi, belirtilen herhangi bir değer yok sayılır. Makine okunabilirliğini sağlamak için HTML bölümü geçerli HTML olmalı ve ilgili tüm etiketler uygun bir şekilde kapatılmalıdır.
Örnekler:
<p>This text can be shown in a snippet <span data-nosnippet>and this part would not be shown</span>.</p> <div data-nosnippet>not in snippet</div> <div data-nosnippet="true">also not in snippet</div> <div data-nosnippet="false">also not in snippet</div> <!-- all values are ignored --> <div data-nosnippet>some text</html> <!-- unclosed "div" will include all content afterwards --> <mytag data-nosnippet>some text</mytag> <!-- NOT VALID: not a span, div, or section -->
Google genellikle sayfaları dizine eklemek amacıyla oluşturur, ancak oluşturma garanti edilmez.
Bu nedenle, ayıklama işlemi oluşturma öncesinde ve sonrasında gerçekleşebilir. Oluşturmadan kaynaklanan belirsizlikleri önlemek için mevcut düğümlerin özelliğini JavaScript aracılığıyla eklemeyin veya kaldırmayın.
JavaScript aracılığıyla DOM öğeleri eklerken, öğeyi başlangıçta sayfanın DOM’sine eklerken gereken şekilde özelliğini ekleyin. Özel öğeler kullanılıyorsa ve kullanmanız gerekiyorsa bunları , veya öğeleriyle sarmalayın veya oluşturun.
Что такое мета тег Robots
Сначала уясним, что есть мета тег Robots, а есть файл Robots.txt, и путать их не будем. Метатег имеет отношение только к одной html странице (на которой он указан), в то время, как файл txt может содержать директивы не только к странице, но к целым каталогам.
Важный момент — для поисковика директивы метатега Роботс имеют преимущество перед директивами из robots.txt. То есть если в .txt у вас указано, что страницу можно индексировать, а в её метатеге указано, что нельзя, поисковик будет слушаться именно директиве из метатега.
При помощи мета тега Robots можно запрещать индексировать содержимое всей страницы. На страницах моего блога он выглядит так:
<meta name="robots" content="noodp"/>
Это означает, что метатег роботс не запрещает индексировать страницу. Noodp тут означает, что он запрещает Google брать в сниппеты описание для страниц из каталога DMOZ — это одна из стандартных настроек плагина Yoast SEO, которым я пользуюсь.
А вот как выглядит метатег Robots, который запрещает индексацию страницы:
<meta name =“robots” content=”noindex,nofollow”/>
Как прописать
Дедовский способ — вручную прописать для страницы. Способ подходит для сайтов на чистом HTML.
Для сайтов на CMS рекомендую использовать SEO-плагины. Я, например, для WordPress использую плагин Yoast SEO, и там под каждой записью в режиме редактирования есть такая опция:
То есть проставить нужное значение можно парой щелчков.
Нужно ли удалять публикации, отмеченные мета-тегом с канала
Итак, вы обнаружили мет-тег, но обращение в техподдержку не помогло.
Давайте рассуждать логически:
- Если статья не получает показы, то её никто не увидите в Дзене.
- Если статья не индексируется поисковыми системами, то на неё не будут переходить из поиска.
Т.е. фактически статья не существует. Удалять её или нет — это ваше личное решение.
Но если у вас есть свой сайт или блог на другой платформе, то я бы рекомендовал перенести статью туда. И удалить. Зачем ей бессмысленно болтаться там, где ей не рады.
Если какой-то трафик на статье есть (а, вдруг?!), то имеет смысла подождать пока ей не исполнится три месяца и тогда удалить.
Собственно, я стал активно публиковать статьи на prozen.ru после того, как мне пришлось перенести несколько статей, получивших «ноиндекс» в Дзене.
Как использовать noindex и nofollow в meta robots
Посмотрим на возможные значения атрибута content:
- noindex, nofollow – запрещена к индексации вся страница и переходы по ссылкам на ней; кстати, идентичной будет значение при записи: <meta name =”robots” content=”none”/>
- noindex, follow – страница не индексируется, но поисковик может переходить по ссылкам;
- index, nofollow – страница индексируется, но переход по ссылкам запрещен;
- index, follow – разрешены к индексированию как страница, так и ссылки на ней;
- noarchive – работает как в yandex, так и в google – не показывает страницу на сохраненную копию;
- noyaca – работает только в Яндексе, если сайт зарегистрирован в каталоге YACA – запрещает использовать описание в результатах поиска, которое берется из Яндекс.Каталога; выглядит так: <meta name =”robots” content=”noyaca”/>
- noodp – работает и в Яндексе, и в Google – запрещает использовать в результатах описания, которые взяты из Каталога ДМОЗ (разумеется, если сайт там зарегистрирован).
Поговорим чуть больше о noodp
Иногда Гугл может добавлять в сниппет описание из DMOZ. Именно для этого и используется атрибут noodp. Кстати, его можно использовать вместе с тегом nofollow. Выглядит это так:
<meta name=“robots” content=”noodp, nofollow”/>
Чего нужно опасаться при использовании
Из-за невнимательности (особенно у новичков) могут случаться конфликты между тегами: в таком случае главным будет положительное значение (разрешающее индексацию). Например тут:
<meta name =”robots” content=”all”/> <meta name =”robots” content=”noindex, nofollow”/>
Тут выбрано будет первое значение, так как там оно положительно.
Что писать в теге meta description?
О том, как правильно составить description, на что заострить внимание, подробно разъясняют поисковые системы Яндекс и Google. Мы постарались обобщить доступную официальную информацию в следующий свод рекомендаций, которые помогут составить оптимальное мета-описание для вашего сайта
Как правильно заполнить meta description:
Уникальность. Для каждой страницы вашего сайта должен быть прописан уникальный по своему содержанию description. В противном случае поисковые системы при достаточной степени схожести контента на страницах, могут посчитать их за дубликаты. И оставить в поисковой выдаче только одну страницу;
Точность. Мета-описание должно точно характеризовать конкретный контент, расположенный на одной странице. Не нужно добавлять описание всего проекта целиком в каждом мета-теге;
Релевантность. Meta description должен соответствовать той информации, которая находится на странице
Не стоит стараться привлечь внимание пользователей, использую в своих мета-описаниях заголовки из желтой прессы;
Размер. Description не должен быть сильно коротким, он не должен состоять из нескольких слов или словосочетаний
Делайте мета-описания размером не менее 100 символов;
Читабельность. Помните, что ваш сниппет будут читать люди, поэтому описание в нем должно быть емким, но в то же время простым и понятным. Не нужно стараться добавить в meta description как можно больше ключевых слов, поисковые системы с большой вероятностью проигнорируют такое описание. Используйте тематически схожие слова и слова-синонимы, чтобы избежать тавтологий;
Ключевые фразы. Ключевые слова не просто могут, они должны присутствовать в мета-описании каждой страницы. 1-3 ключевых слова в description — хорошая практика. Основное ключевое слово старайтесь разместить в первом предложении.
Обобщение. Мета-описание должно обобщать всю самую ценную информацию на странице. Систематизируйте информацию, разбросанную по странице. Например, для карточки товара это может быть краткое описание товара, цена, производитель, состав, доступные характеристики. Для информационной статьи: основная тема, автор, дата публикации;
Формат. Description должен быть написан на том же языке, что и web-страница. Не стоит злоупотреблять заглавными буквами, спецсимволами, вызывающими лозунгами, знаками препинания.
Актуальность. Мета-описание должно соответствовать актуальной информации на странице. Если вы редактируете содержание странице, поддерживайте в актуальном состоянии и description.
Description — это ваша визитная карточка. При его составлении постарайтесь понять, почему пользователя должен заинтересовать именно ваш контент. Ответив себе, дайте ответ и пользователям.
Есть ли различия в составлении meta description для разных поисковых систем: Яндекс и Google? Давайте попробуем найти отличия в сниппетах и рекомендациях по составлению мета-описаний.
Мета-тег
Этот мета-тег устанавливается в секцию <head> на той странице, которая не должна индексироваться и выглядит это следующим образом:
Мета-тег
<head>
…
<meta name=»robots» content=»noindex, nofollow» />
…
</head>
|
1 |
<head> … <meta name=»robots»content=»noindex, nofollow»> … <head> |
Суть значений noindex и nofollow в мета-теге остается та же:
Noindex – запрещает индексацию на уровне страницы (весь контент, который на ней есть), но не запрещает поисковым роботам посещать ее и переходить по ссылкам, которые используются в контенте.
Nofollow – запрещает поисковым роботам переходить по ссылкам на уровне страницы (и по внешним, и по внутренним).
Комбинации <meta name=»robots» content=»х, y» />
Есть несколько случаев, когда используют данный мета-тег на практике. Под эти случаи есть разные решения:
- <meta name=»robots» content=»noindex, follow» /> нужно использовать в случае, если вы не хотите, чтобы страница была проиндексирована поисковыми системами, но роботы смогли бы перейти по ссылкам с этой страницы на другие. Например, это может быть вторая страница пагинации на сайте типа site.com/category/?page=2, на которой есть ссылки на следующие товары и вы не хотите, чтобы эта страница была проиндексирована поисковой системой.
- <meta name=»robots» content=»noindex» /> выполняет то же самое. В данном случае вы запретите поисковой системе индексировать страницу, но просматривать ее и ходить по ссылкам роботы смогут.
- <meta name=»robots» content=»noindex, nofollow» /> – запрещает индексировать контент на соответствующей странице, а также запрещает роботам переходить по ссылкам.
- <meta name=»robots» content=»index, follow» /> – разрешает роботам индексировать страницу и ходить по ссылкам. Такой мета-тег не имеет смысла использовать, так как по умолчанию, и без него поисковикам разрешено выполнять те же действия. Но если на вашем сайте он установлен и вы не собираетесь ограничивать работу робота, специально удалять его нет смысла.
- <meta name=»robots» content=»index, nofollow» /> — разрешает индексировать страницу, но по ссылкам, которые в ней содержатся, робот переходить не будет.
- <meta name=»robots» content=»nofollow» /> — делает то же самое — разрешает индексировать страницу, но по ссылкам, которые в ней содержатся, робот переходить не будет.
Данный мета-тег можно использовать как для Google, так и для Яндекс отдельно
Если вам необходимо закрыть от индексации страницы только для Google, можно использовать <meta name=»googlebot» content=»noindex» />. Так говорит справка Google.
Если закрыть от индексации только для Яндекса – <meta name=»yandex» content=»noindex»/>. Об этом также очень подробно написано в справке Яндекс.
Why is the robots meta tag important for SEO?
The meta robots tag is commonly used to prevent pages showing up in search results, although it does have other uses (more on those later).
There are various types of content that you might want to prevent search engines from indexing:
- Thin pages with little or no value for the user;
- Pages in the staging environment;
- Admin and thank-you pages;
- Internal search results;
- PPC landing pages;
- Pages about upcoming promotions, contests or product launches;
- Duplicate content (use canonical tags to suggest the best version for indexing);
Generally, the bigger your website is, the more you’ll deal with managing crawlability and indexation. You also want Google and other search engines to crawl and index your pages as efficiently as possible. Correctly combining page-level directives with robots.txt and sitemaps is crucial for SEO.
Common Meta Robots Mistakes
It’s not uncommon for mistakes to be made when instructing search engines how to crawl and index a web page, with the most common being:
Meta Robots Directives on a Page Blocked By Robots.txt
If a page is disallowed in your robots.txt file, search engine bots will be unable to crawl the page and take note of any directives that are placed in meta robots tags or in an x-robots-tag.
Make sure that any pages that are instructing user-agents in this way can be crawled.
If a page has never been indexed, a robots.txt disallow rule should be sufficient to prevent this from showing in search results, but it is still recommended that a meta robots tag is added.
Adding Robots Directives to the Robots.txt File
While never officially supported by Google, it used to be possible to add a noindex directive to your site’s robots.txt file and for this to take effect.
This is no longer the case and was confirmed to no longer be effective by Google in .
Removing Pages With a Noindex Directive From Sitemaps
If you are trying to remove a page from the index using a noindex directive, leave the page in your site’s sitemap until this has happened.
Removing the page before it has been deindexed can cause delays in this happening.
Accidentally Blocking Search Engines From Crawling an Entire Site
Sadly, it’s not uncommon for robots directives that are used in a staging environment to accidentally be left in place when the site moves to a live server, and the results can be disastrous.
Before moving any site from a staging platform to a live environment, double-check that any robots directives that are in place are correct.
You can use the Semrush Site Audit Tool before migrating to a live platform to find any pages that are being blocked either with meta robots tags or the x-robots-tag.
By taking the time to understand the different directives and how to use them, you can prevent technical SEO mistakes. Having sufficient control over how your pages are crawled and indexed can help to keep unwanted pages out of the SERPs, prevent search engines from following unnecessary links, and give you control over how your site’s snippets are displayed, among other things. Get started setting up your robots meta tags and x-robots-tags to ensure that your site is running smoothly!
Run a Technical Site Audit
with the Semrush Site Audit Tool
Try for Free →
Try for Free →
What Are Robots Meta Tags?
A Robots meta tag, also known as robots tags, is a piece of HTML code that’s placed in the <head></head> section of a web page and is used to control how search engines crawl and index the URL.
This is what a robots meta tag looks like in the source code of a page:
These tags are page-specific and allow you to instruct search engines on how you want them to handle the page and whether or not to include it in the index.
What Are Robots Meta Tags Used For?
Robots meta tags are used to control how Google indexes your web page’s content. This includes:
- Whether or not to include a page in search results
- Whether or not to follow the links on a page (even if it is blocked from being indexed)
- Requests not to index the images on a page
- Requests not to show cached results of the web page on the SERPs
- Requests not to show a snippet (meta description) for the page on the SERPs
In order to understand how you can use the robots meta tag, we need to look at the different attributes and directives. We’ll also share code examples that you can take and drop into your page’s header to request the search engines to index your page in a certain way.
Run a Technical Site Audit
with the Semrush Site Audit Tool
Try for Free →
Try for Free →
Использование структурированных данных
Метатеги robots определяют, какое количество контента Google может автоматически извлекать с веб-страниц и показывать в результатах поиска. Однако многие издатели также применяют структурированные данные schema.org, чтобы показывать в результатах поиска нужную им информацию. Заданные в метатегах robots ограничения не распространяются на структурированные данные, кроме значений и , которые указываются для творческих работ. Чтобы задать максимальную длину текстового фрагмента в результатах поиска с учетом этих значений , используйте метатег robots с директивой . К примеру, если на странице есть структурированные данные для рецептов (), определенный ими контент может показываться в карусели рецептов независимо от ограничения длины текстового фрагмента. Длину текстового фрагмента можно ограничить при помощи , однако эта директива метатега robots не действует, когда информация предоставляется с применением структурированных данных для расширенных результатов.
Вы можете редактировать типы структурированных данных и их значения на веб-страницах. Добавляйте или удаляйте информацию, чтобы роботу Google были доступны только нужные сведения
Обратите внимание, что структурированные данные могут использоваться в Поиске, даже если они объявлены внутри элемента с атрибутом .
Выводы
Nofollow отвечает за переход поисковых систем по этим ссылкам, как на всей странице, так и для определенной ссылки. Ранее noindex тоже выполнял аналогичную функцию, но только по отношению к Яндексу, который со временем начал понимать nofollow, в результате чего значением noindex начали закрывать от индексации контент на странице.
Владелец сайта должен грамотно использовать атрибут nofollow и понимать, в каких именно случаях это делать:
- Когда ссылка ведет на веб-ресурсы с некачественным контентом.
- Когда вы размещаете на странице коммерческий контент.
По атрибуту nofollow ссылка может индексироваться и передавать свой вес, если она стоит на качественный ресурс.
Главная задача использования nofollow — помочь указать приоритетные для сканирования ссылки, разделить продающие статьи от информационных, а также защитить сайт от спама, который, если не контролировать, может привести к снижению ранжирования или куда хуже, вылету ресурса из индекса.
Для всех других ситуаций можете смело применять dofollow ссылки, открытые для поисковых роботов. Репутация сайта ничуть не ухудшится, а даже улучшится, если вы будете оставлять ссылки на полезные для вашей целевой аудитории страницы. И никакой вес ваши документы не потеряют, а наоборот даже могут приобрести за счет .




