Что такое sql и как он работает
Содержание:
- PostgreSQL
- База данных: назначение, понятие, классификация
- Мультимодельность
- Что такое нормализация
- Объектные СУБД (Object-oriented)
- Колоночные СУБД
- Вернёмся к SQL
- Классификации СУБД
- SQLite
- В чём преимущества
- Виды СУБД
- Данные
- Формы
- Проектирование баз данных
- Виды нереляционных баз данных
- Теперь про базы
- Где их используют
- MySQL
- Колоночные СУБД
PostgreSQL

PostgreSQL является еще одним выдающимся решением с открытым исходным кодом, работающим во всех основных операционных системах, включая Linux, UNIX (AIX, BSD, HP-UX, SGI IRIX, Mac OS X, Solaris, Tru64) и Windows. PostgreSQL полностью отвечает принципам ACID (атомарность, согласованность, изолированность, устойчивость).
Достоинства
- Возможность создания пользовательских типов данных и методов запросов;
- Среда разработки баз данных выполняет хранимые процедуры более чем на десятке языков программирования: Java, Perl, Python, Ruby, Tcl, C/C ++ и собственный PL/pgSQL;
- GiST (система обобщенного поиска): объединяет различные алгоритмы сортировки и поиска: B-дерево, B+-дерево, R-дерево, деревья частичных сумм и ранжированные B+ -деревья;
- Возможность создания для большего параллелизма без изменения кода Postgres, например, CitusDB.
Недостатки
- Система MVCC требует регулярной «чистки»: проблемы в средах с высокой скоростью транзакций;
- Разработка осуществляется обширным сообществом: слишком много усилий для улучшений.
База данных: назначение, понятие, классификация
В нашей статье мы не будем углубляться в математические теории и законы, описывающие базы данных, т. к. подробности всегда можно узнать из специализированной литературы. Но принципы работы БД, особенности управления, терминологию, устройство, назначение, а также такое понятие, как классификация баз данных, сегодня должен знать каждый, кто так или иначе сталкивается с ИТ-сферой, а уж тем более в ней работает.
Итак, самое простое определение баз данных звучит следующим образом: база данных — это упорядоченное хранение информации в систематизированном виде. При этом виды упорядочивания, хранения, систематизации и управления могут быть разные. И каждый из них отвечает определённым требованиям либо предназначен для выполнения определённых действий.
Мультимодельность
Термин «многовариантное хранение» вошел в обиход в 2011 году. Осознание проблем подхода и поиск решения заняли несколько лет, и к 2015 году устами аналитиков Gartner ответ был сформулирован:
- Из «Market Guide for NoSQL DBMSs — 2015»:
- Из «Magic Quadrant for ODBMS — 2016»:
Похоже, что в этот раз аналитики Gartner с прогнозом не ошиблись. Если зайти на страницу с основным рейтингом СУБД на DB-Engines, можно увидеть, что большая часть его лидеров позиционирует себя именно как мультимодельные СУБД. То же можно увидеть и на странице с любым частным рейтингом.
В таблице ниже приведены СУБД — лидеры в каждом из частных рейтингов, заявляющие о своей мультимодельности. Для каждой СУБД указаны первоначальная поддерживаемая модель (когда-то бывшая единственной) и наряду с ней модели, поддерживаемые сейчас. Также приведены СУБД, позиционирующие себя как «изначально мультимодельные», не имеющие по заявлениям создателей какой-либо первоначальной унаследованной модели.
| СУБД | Изначальная модель | Дополнительные модели |
|---|---|---|
| Oracle | Реляционная | Графовая, документная |
| MS SQL | Реляционная | Графовая, документная |
| PostgreSQL | Реляционная | Графовая*, документная |
| MarkLogic | Документная | Графовая, реляционная |
| MongoDB | Документная | Ключ-значение, графовая* |
| DataStax | Wide-column | Документная, графовая |
| Redis | Ключ-значение | Документная, графовая* |
| ArangoDB | — | Графовая, документная |
| OrientDB | — | Графовая, документная |
| Azure CosmosDB | — | Графовая, документная, реляционная |
Далее для каждого из классов мы покажем, как реализуется поддержка нескольких моделей в СУБД из этого класса. Наиболее важными будем считать реляционную, документную и графовую модели и на примерах конкретных СУБД показывать, как реализуются «недостающие».
Что такое нормализация
Чтобы уменьшить размер реляционной базы (не хранить избыточные данные) и избежать противоречивости (аномалий) при работе с ними, отношения в базе нормализуют. Проще говоря — разбивают их на взаимосвязанные таблицы. Это называется декомпозицией.
Избыточность данных — это когда одни и те же данные хранятся в базе сразу в нескольких местах.
Проверим наш пример на избыточность
Каждая строка таблицы Messages содержит имя клиента и никнейм оператора, а также их телефоны. Причём в 1-й и 3-й строках мы видим звонки от одного и того же клиента, а в 1-й и во 2-й — ответы одного и того же менеджера. То есть в 1-й и 3-й строках дублируются имя и телефон клиента — Васи, а в 1-й и 2-й — никнейм менеджера «Оператор1».
Чтобы избавиться от дублирования информации, выделим сущности Клиент и Оператор. И вынесем специфичные для каждой атрибуты в отдельные таблицы.
В первой (Clients) будут храниться имена и телефоны клиентов, а во второй (Operators) — операторов. Кроме того, каждой записи в этих таблицах мы присвоим атрибут id — так называемый первичный ключ (его значение уникально, то есть не может повторяться в пределах таблицы). С его помощью мы установим связь с записями таблицы Messages.
Для этого к каждой записи в Messages (напомним, она всё ещё представляет сущность «звонок») добавим два новых атрибута (внешних ключа): id_client и id_oper. Они будут ссылаться на первичные ключи из таблиц Clients и Operators соответственно. Столбцы с именами и телефонами из таблицы Messages уберём.
И вот что получим:
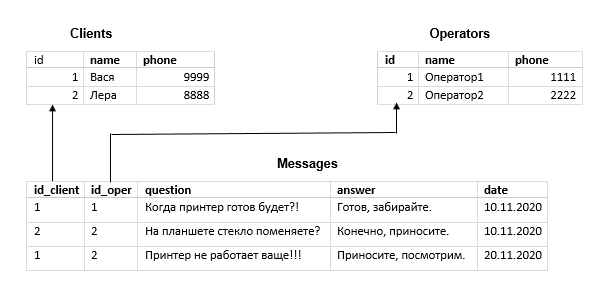
В такой базе, чтобы поменять телефон клиента сразу для всех записей, достаточно изменить всего одно поле в таблице Clients.
Всего существует шесть форм нормализации реляционных баз данных — в порядке уменьшения избыточности отношений. Все они описаны формальными правилами. Наше отношение мы привели ко второй нормальной форме.
Объектные СУБД (Object-oriented)
Как следует из названия, такие СУБД оптимизированы под хранение и работу с объектами. Как и полагается в ООП, у таких объектов в СУБД также имеются свойства и методы. Так же в них реализованы инкапсуляция и полиморфизм. Основная цель использования объектных СУБД — избавить разработчиков, применяющих объектную модель программирования, от необходимости трансформировать объекты в таблицы, строки и их связи, и обратно.
Яркие представители этого типа СУБД: MongoDB Realm, InterSystems Caché, ObjectStore, Actian NoSQL DB, Objectivity/DB.
Когда выбирать объектные СУБД
Честно говоря, я видел не так много успешных реализаций с использованием объектных СУБД. Тем не менее, объектные базы данных обычно рекомендованы для тех случаев, когда требуется высокопроизводительная обработка данных, имеющих сложную структуру, при этом разработка ведется с использованием языков объектно-ориентированного программирования.
Когда не выбирать объектные СУБД
Не выбирайте объектную СУБД, если вы планируете использовать классический язык SQL, если вы не используете ООП или если вы планируете в дальнейшем мигрировать с данной СУБД на другие. Если нет хорошего понимания ООП, в большинстве случаев лучше выбрать документо-ориентированные СУБД.
Колоночные СУБД
Колоночные СУБД очень похожи на реляционные. Они так же состоят из строк, которые имеют атрибуты, а строки группируются в таблицах. Различия в логических моделях несущественные, а вот на уровне физического хранения данных различия значительные.
В реляционных СУБД данные хранятся «построчно», это означает что для считывания значения определенной колонки, придется прочитать практически всю строку, как минимум от первой до нужной колонки. В колоночной СУБД данные хранятся «поколоночно», т.е. колонка — это как отдельная таблица. Соответственно чтение будет происходить из конкретного столбца сразу. На практике это реально работает очень быстро (проверено мной на нескольких реализованных хранилищах данных).
Основные преимущества колоночных СУБД – эффективное выполнения сложных аналитических запросов на больших объемах, и легкое, практически мгновенное, изменение структуры таблиц с данными, плюс существенная компрессия и сжатие, которое позволяет значительно экономить место.
Яркие представители колоночных СУБД — Sybase IQ (ныне SAP IQ), Vertica, ClickHouse, Google BigTable, InfoBright, Cassandra.
Когда выбирать колоночные СУБД
Один из весомых аргументов за использование именно колоночной СУБД — это если вы хотите построить хранилище данных, и планируете делать выборки со сложными аналитическими вычислениями. Косвенный признак, который так же может сигнализировать о том, что имеет смысл, хотя бы посмотреть в сторону колоночных СУБД — это если количество строк, из которых делаются выборки, превышает сотни миллионов.
Когда не выбирать колоночные СУБД
Учитывая специфику колоночных СУБД, будет не эффективно ее использовать, если выборки достаточно простые, параметры выборки статичны, и если преобладают выборки по ключевым значениям. Так же, если количество строк в таблице, из которой делается выборка, меньше сотен миллионов строк, то скорее всего не будет большого преимущества, по сравнению с реляционной СУБД.
Нужно так же иметь ввиду, что в колоночных СУБД могут быть и другие ограничения. Например, может отсутствовать поддержка транзакций, а язык запросов может отличаться от классического SQL, и прочее.
Вернёмся к SQL
Если читателю показалось, что мы ушли в сторону от SQL, так оно и есть. Но очень трудно понять, что такое SQL, не зная, с чем он работает.
Выходит, что SQL — это язык программирования, необходимый для написания команд к БД, после выполнения которых она вернёт результат. Результат будет зависеть от команды, написанной на SQL. Как в любом другом языке программирования, в SQL есть операторы для работы с данными, из которых складываются команды. Операторы распределены по четырём языкам:
- DDL — Data Definition Language;
- DML — Data Manipulation Language;
- DCL — Data Control Language;
- TCL — Transaction Control Language.
Классификации СУБД
Существует несколько признаков, по которым можно классифицировать СУБД.
СУБД по модели данных бывают:
- Иерархические СУБД
- Сетевые СУБД
- Реляционные СУБД
- Объектно-ориентированные СУБД
- Объектно-реляционные СУБД
В настоящее время в серьезных проекта используются 2 последних типа.
СУБД по степени распределённости
- Локальные (СУБД размещается только на одном компьютере)
- Распределённые (части СУБД могут размещаться на 2-х и более компьютерах).
По способу доступа к БД
Файл-серверные СУБД
В них файлы с данными расположены централизованно на специальном файл-сервере. СУБД же должны быть расположены на каждом клиенте (рабочей станции). Доступ СУБД к данным производится посредством локальной сети. Поддержка синхронизации чтений и обновлений осуществляется за счет временных блокировок затребованных файлов.
Плюсом этой архитектуры можно назвать низкую нагрузку на файловый сервер.
К минусам же: высокая загрузка трафиком локальной сети; сложность или невозможность централизованного управления; нельзя обеспечить такие важные характеристики как надёжность, доступность и безопасность. Файл-серверные СУБД используют в локальных приложениях; в системах с малой интенсивностью обработки данных и небольшими пиковыми нагрузками на базу данных.
Сейчас её при создании крупной информационной системы не используют.
Примеры файл-серверных СУБД:
- dBase,
- FoxPro,
- Microsoft Access,
- Paradox,
- Visual FoxPro.
Клиент-серверные СУБД
Клиент-серверная СУБД расположена на сервере вместе с базой данных и осуществляет доступ к БД исключительно в монопольном режиме. Все запросы на обработку данных клиентских приложений и станций обрабатываются централизованно.
Недостатком такого типа СУБД можно назвать повышенные требования к серверу.
Достоинствами: более низкую загрузку локальной сети; преимущества централизованного управления; поддержку высокой надёжности, доступности и безопасности.
Примеры клиент-серверных СУБД:
- Caché,
- Firebird,
- IBM DB2,
- Informix,
- Interbase,
- MS SQL Server,
- MySQL, Oracle,
- PostgreSQL,
- Sybase Adaptive Server Enterprise,
- ЛИНТЕР.
Встраиваемые СУБД
Это вид СУБД, который может выступать лишь в качестве составной части определенного программного комплекса, без необходимости процедуры отдельной установки. Такой вид СУБД может быть использован для локального хранения данных своего приложения и не рассчитан на коллективное использование в компьютерной сети. Физически же это зачастую реализуется в виде подключаемой библиотеки. Со стороны приложения доступ к данным происходит посредством SQL-запросов либо через специальный программный интерфейс.
Примеры встраиваемых СУБД:
- Firebird Embedded,
- BerkeleyDB,
- Microsoft SQL Server Compact,
- OpenEdge,
- SQLite,
- ЛИНТЕР.
Для рассмотрения лишь части основных возможностей и внутреннего устройства любой СУБД требуется один или несколько отдельных учебных курсов.
SQLite

Провозгласившая себя самой распространенной СУБД в мире, SQLite зародилась в 2000 году и используется Apple, , Microsoft и . Каждый релиз тщательно тестируется. Разработчики SQLite предоставляют пользователям списки ошибок, а также хронологию изменений кода каждой версии.
Достоинства
- Нет отдельного серверного процесса;
- Формат файла – кросс-платформенный;
- Транзакции соответствуют требованиям ACID;
- Доступна профессиональная поддержка.
Недостатки
Не рекомендуется для:
- клиент-серверных приложений;
- крупномасштабных сайтов;
- больших наборов данных;
- программ с высокой степенью многопоточности.
В чём преимущества
Базы данных и их системы управления заточены на работу с большим объёмом данных и от лица большого числа пользователей. Сейчас вы поймёте.
Представьте, что у вас есть экселька со списком клиентов. Это не база данных, это просто таблица. Чтобы прочитать или записать что-то в эту эксельку, вам нужно её открыть, сделать дело, сохранить.
Допустим, экселька с клиентами лежит на сетевом диске. Вы открыли её и ковыряетесь в данных, вносите изменения. Пока вы это делаете, ваш коллега тоже её открыл и тоже вносит изменения. Потом вы сохранились и закрыли эксельку. Экселька перезаписалась вашими данными. Но у вашего коллеги эти данные не отобразились, он-то открыл её раньше. Теперь, когда он сохранит свою эксельку, его данные перезапишутся поверх ваших, а ваши данные пропадут. Это полный ахтунг: вся ваша работа потеряна.
Или у вас в компании правило: экселька всегда на одной флешке, работаем только с неё. Сейчас флешка в вашем компьютере, вы с ней работаете. А вашему коллеге нужно с ней тоже поработать. Он говорит: «Дай». Вы ему «Отстань». Ну и слово за слово…
Но можно организовать своего рода СУБД. Один ответственный сотрудник назначается главным по эксельке. Она открыта на его компьютере, а вы ему говорите: «Петруха, добавь в клиента такого-то вот такие данные». «Петруха, а шо, когда дедлайн по поставке для этих ребят из Воронежа?», «Петруха, питерские отказались, поставь там отказ».
Петруха — ваша система управления базой данных. А экселька — это его база данных.
Понятно, что Петруха медленный и не всегда многозадачный, но хотя бы он избавляет от проблемы рассинхрона версий и потери данных.
Скорость — ещё одно преимущество базы данных. База данных устроена так, что она легко и быстро находит, записывает, переписывает и снова находит данные. Всё потому, что СУБД всегда знает, что где лежит и по какому критерию искать. Там не будет случайных данных в случайном месте.
Скорость важна ещё и потому, что СУБД обычно обслуживает сразу много потоков: одновременно ей могут пользоваться десятки и сотни тысяч человек, поэтому ей некогда копаться. В хорошо сделанных БД всё молниеносно.
Сложность. Базы данных нужны в числе прочего для хранения сложно структурированных данных. Мы привыкли думать, что база данных — это такая таблица, где есть строки и столбцы. Но база данных при правильной организации может намного больше:
- Связывать одну единицу данных с множеством других. Например, если один человек совершил много заказов со множеством товаров внутри каждого, база данных способна хранить и обрабатывать такие связи.
- База может хранить дерево данных — вроде того, о котором мы писали недавно. Попробуй в реальной жизни похранить дерево!
- В базах могут жить ссылки на другие фрагменты и отделы базы.
Базу можно представить как таблицу, но лишь в самом упрощённом виде. Для более сложных задач базу можно представить как очень сложное дерево, или огромный склад упорядоченных коробок, или даже как огромный завод по фасовке данных.
Виды СУБД
Сами по себе таблицы или база данных не способны выполнять операции, а в СУБД можно создавать новые таблицы, удалять ненужные данные, настраивать ключи и обрабатывать запросы. Основные задачи СУБД:
- поддержка языков баз данных;
- непосредственное управление данными;
- управление буферами оперативной памяти;
- управление транзакциями;
- резервное копирование и восстановление после сбоев.
Существуют разные виды таких систем, которые разрабатывает и техногиганты, вроде Google, Microsoft и Amazon, и более нишевые студии. Разработчики стремятся сделать свой продукт лучше, чтобы их система быстрее и качественнее других обрабатывала данные. Из-за этого появились разные виды языка SQL — так называемые SQL-диалекты. У каждой СУБД диалект имеет что-то общее со всеми, а также свои особенности, которые не будут работать в другой системе.
СУБД могут быть коммерческими или иметь открытый код. Системы управления с открытым кодом можно бесплатно использовать в проектах, а также дополнять их документацию и совершенствовать процесс работы с системой. Коммерческие СУБД имеют платный доступ к полным версиям — как правило, такие используют крупные корпорации.
PostgreSQL — это объектно-ориентированная система, то есть она обрабатывает данные как абстрактные объекты. Каждый объект, в отличие от простых табличных значений, может иметь собственные характеристики и уникальные методы взаимодействия с другими объектами. Это позволяет PostgreSQL обрабатывать более сложные структуры данных и выполнять более сложные процедуры. Например, Яндекс.Почта в свое время перешла на эту систему, чтобы поддерживать стабильное соединение десятков тысяч пользователей к одной базе.
MySQL — простая в изучении и функциональная система, которая работает с сайтами и веб-приложениями. Чаще всего используется в системах управления контентом сайтов (CMS), на сайтах с возможностью регистрации пользователей, в корпоративных системах CRM, в планировщиках, чатах и форумах. MySQL считается одним из самых безопасных и высокоскоростных решений, которое существует на рынке.
SQLite — это облегченная встраиваемая версия СУБД. В ней нет возможности поделиться правами доступа, как во многих других системах, но благодаря своему устройству эта система быстрая и мощная. SQLite подходит для обработки запросов на сайтах с низким и средним трафиком, а также в однопользовательских мобильных приложениях и играх. Преимущество такой системы — файловая структура, то есть база в SQLite состоит из одного файла, поэтому ее очень легко переносить.
Oracle — одна из первых СУБД, которая появилась еще в 1977 году и развивается до сих пор. Это кроссплатформенная система, которая может работать на Windows, Linux, MacOS, мобильных и других ОС. Система используется в крупных коммерческих проектах. Например, в России с Oracle сотрудничают операторы МТС и Теле2, банк «Открытие» и ВТБ.
Google Cloud Spanner — это облачная система управления данными, которую Google разработал для управления собственными сервисами, например AdWords и Google Play. В 2017 году систему сделали общедоступной. Cloud Spanner относят к категории NewSQL — это системы, которые совмещают в себе преимущества реляционных и нереляционных СУБД.
Данные
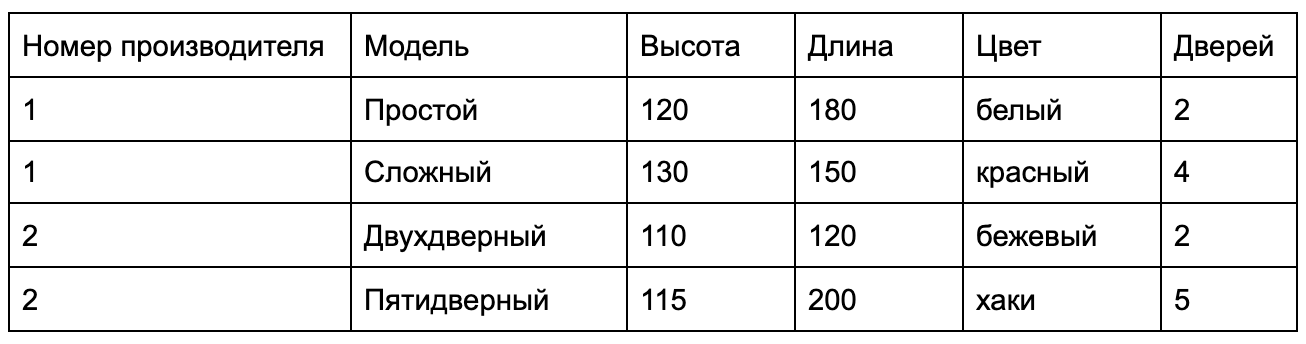
В контексте баз данных под данными понимают набор значений, который собирается в строки и столбцы, тем самым представляя таблицу. Представим, что у нас есть каталог мебельного магазина. Нам нужно сохранить все данные из раздела «Шкафы» этого каталога в таблицу. Мы решили, что все шкафы отличаются друг от друга характеристиками:
- название производителя;
- название модели;
- высота;
- длина;
- цвет;
- количество дверей.
Составим таблицу и вобьём в неё выдуманные данные.

У нас есть таблица с данными. Столбцами мы показываем, как они будут храниться. В примере я указал, что мы будем хранить информацию в структуре: производитель, модель, высота, длина, цвет, количество дверей. Иными словами, я создал структуру таблицы.
Добавляя в таблицу строки, я вводил в неё данные, ориентируясь на структуру, заданную в столбцах. Чем больше строк, тем больше данных. Чем больше столбцов, тем подробнее будут эти данные.
Ещё есть такое понятие, как «значение» — это пересечение столбца и строки. Например, у последней строки в столбце «Цвет» написано «хаки». Здесь «хаки» — значение. Если мы начнём группировать таблицы и добавим возможность манипулирования ими, то получим базу данных.
Формы
Для каждой системы управления базами данных формы являются одним из главных вариантов интерфейса. Они используются для работы с информацией и содержат команды для выполнения конкретных действий. Каждой кнопке может быть присвоена какая-то функция программным путем. Примером такой формы может послужить ссылка на информацию о конкретном клиенте. Эту функцию можно продолжать дальше. В ячейке покупателя может быть создана форма для составления заказа.
Такие функции дают возможность обуславливать работу других пользователей с данными, хранящимися в базе. Например, легко ограничить количество видимых полей и доступных операций. Формы дают возможность защищать данные и обеспечивать правильность ввода.
Проектирование баз данных
Проектирование — самая трудная задача при работе с данными. Оно заключается не только в том, чтобы создать таблицу, указав наименование столбцов и тип данных. Это гораздо более сложный процесс, требующий специализированных знаний и умений. Говоря о типах баз данных в столбцах, подразумевается, например, способ их записи, который бывает символьный (строковый), числовой, календарный, NULL.
Основная сложность заключается в том, что мощность наших компьютеров ограничена. И пока данных мало, таблиц и строк тоже немного, поэтому машина обрабатывает информацию достаточно быстро. Но с течением времени информации становится всё больше, что может стать причиной снижения быстродействия. Работа машины будет замедляться, времени на обработку запросов потребуется всё больше. Добавить новую запись в таблицу не станет проблемой для реляционной СУБД, а вот выборка данных может превратиться в весьма ресурсоёмкую операцию. Хотя, многое будет зависеть и от настроек СУБД.
Виды нереляционных баз данных
Базы NoSQL делятся на четыре основные категории (в зависимости от решаемых с их помощью задач).
Ключ-значение
Такую базу можно представить как огромную таблицу. В каждой её ячейке хранятся данные произвольного типа, а каждому значению присвоен уникальный ключ, по которому это значение можно найти.
Такая СУБД не поддерживает связи между объектами, выполняет лишь операции поиска значений по ключу, добавления и удаления записи.
Например:
| key | value |
|---|---|
| user1 | {Кузнецов В., отдел маркетинга} |
| user2 | {name:Лена, position:секретарь} |
| user3 | {ООО «Вектор»} |
| user4 | {Трофимова Таня, отд.2, дизайнер} |
| user5 | {Галина Николаевна, гл. бух.} |
| user6 | {65,84,236} |
Базы «ключ-значение» часто используют для кэширования данных и организации очередей.
Их достоинства — быстрый поиск и простое масштабирование.
Их недостаток — нельзя производить операции со значениями. Например — сортировать их или анализировать.
Одна из самых популярных — Redis. Её используют Uber, Slack, Stack Overflow, сайты гостиниц и туристические, социальная сеть Twitter.
Документоориентированные СУБД
В таких данные хранятся в виде иерархических структур (документов) с произвольным набором полей и их значений. Документы объединяются в коллекции.
Если провести аналогию с реляционными СУБД, то коллекциям соответствуют таблицы, а документам — строки в них.
Например, фрагмент документа с информацией о фильмах:
Документоориентированные базы используют в системах управления содержимым (CMS) — для хранения каталогов и пользовательских профилей.
Одна из самых популярных — MongoDB (там можно создавать процедуры на JavaScript).
Колоночные
Эти базы отличаются от реляционных лишь способом хранения данных на накопителе.
Если реляционная база создаёт для каждой таблицы по файлу, то в колоночной отдельный файл создаётся для каждого столбца таблицы.
Например, если реляционная таблица выглядит так:
| name | color | property |
|---|---|---|
| волк | серый | зубастый |
| коза | белая | рогатая |
| капуста | зелёная |
То те же записи колоночной базы будут выглядеть примерно так:
| name | волк | коза | капуста |
| color | серый | белая | зелёная |
| property | зубастый | рогатая |
Что это даёт? Представьте, что вам нужны только названия объектов, а их свойства вас не интересуют.
При выполнении запроса в реляционной таблице просматривается каждая запись и из неё выбираются нужные данные. В колоночной базе с диска будет считана только одна колонка с названиями. Это сокращает время выполнения запроса, причём намного.
Колоночные базы применяются в различных каталогах и архивах данных, работа с которыми основана на подобных выборках.
Одна из самых популярных СУБД такого типа — Apache Cassandra.
Графовые
В некоторых предметных областях данные удобно представлять в виде графов. Для их хранения лучше всего подходят графовые базы.
Вершины (или узлы графа) — это объекты (сущности), а рёбра графа — взаимосвязи между ними.
Теперь про базы
Получается, что БД — это совокупность данных, представленных определённым образом (в нашем случае — таблицей), и набор инструментов для манипулирования ими.
Данные могут быть сгруппированы не только в таблицы, но и в коллекции. У каждой базы есть свой инструмент для создания таблиц/коллекций, добавления, удаления или изменения данных, а также для составления выборки. В статье мы рассмотрим базы, которые состоят из таблиц, а инструментом манипулирования данными будет язык SQL.
Таблицы между собой могут объединяться в схемы — в одной базе данных их может быть несколько, а может и не быть деления на схемы вообще. Это зависит от БД.
Вернёмся к определению из Википедии и вспомним про слово «реляционные». Реляционные (от англ. relation — отношения) — это базы данных, таблицы которых могут выстраиваться в различных отношениях. Возьмём предыдущий пример и добавим в него тех самых «отношений». Создадим таблицу «Производитель», а ту, что в примере, обозначим как «Каталог».
Таблица «Производитель»:

Теперь таблицу «Каталог» можно оформить в другом виде:
Получилось так, что у таблиц «Каталог» и «Прозводитель» появились отношения. Значения из столбца «Каталог» ссылаются на строки из таблицы «Производитель». Добавлением отношения мы решили нескольких проблем:
- Избавились от избыточных данных. Каталог стал занимать меньше места. Вместо хранения целой строки мы используем только номер строки из таблицы «Производитель».
- Снизили вероятность ошибиться. При смене названия производителя нам достаточно отредактировать строку в таблице «Производитель», «Каталог» останется без изменений.
Это не все проблемы, которые мы решили добавлением отношений. Для понимания других проблем необходимо углубиться в тему баз данных. Разделение данных на таблицы с отношениями — это процесс нормализации. Так можно достигать различных нормализованных форм данных. При достижении каждой из нормализованных форм мы избавляем данные от дополнительных проблем.
Где их используют
Базы данных сейчас используются почти везде:
- На сайтах, чтобы хранить контент для страниц. Все статьи в «Коде» на самом деле хранятся в базе данных и извлекаются оттуда по вашему запросу.
- В смартфонах, чтобы хранить все ваши данные — фото, сообщения, заметки, контакты и музыку. Так как всего этого много, а доступ к этому должен быть молниеносный, используют разные виды СУБД.
- В почтовых сервисах, чтобы можно было найти нужное письмо. Там строятся сложные индексные массивы, по которым ваш почтовый клиент ищет данные.
- Везде, где есть личные кабинеты и регистрация, — чтобы запоминать пользователей и отличать их друг от друга.
- В соцсетях и блогах почти всё хранится в базах данных.
Если у вас в работе появляется много одинаковых или похожих данных, то самый надёжный способ не потерять ничего из них — поместить их в базу данных.
MySQL
MySQL – самая популярная СУБД. Это многофункциональное открытое приложение, поддерживающее работу огромного количества сайтов. Система MySQL довольно проста в работе и может хранить большие массивы данных.
Примечание: Учитывая популярность MySQL, для этой системы было разработано большое количество сторонних приложений, инструментов и библиотек.
MySQL не реализует полный стандарт SQL. Несмотря на это, MySQL предлагает множество функциональных возможностей для пользователей: автономный сервер баз данных, взаимодействие с приложениями и сайтами и т.п.
Типы данных MySQL
- TINYINT: целое число в диапазоне от -128 до 127 (1 байт).
- SMALLINT: целое число от -32768 до 32767 (2 байта).
- MEDIUMINT: число от -8388608 до 8388608 (3 байта).
- INT или INTEGER: число в диапазоне от -2147683648 до 2147683648 (4 байта).
- BIGINT: число от -263 до 263-1 (8 байт).
- FLOAT: число с плавающей точкой (4 байта).
- DOUBLE, DOUBLE PRECISION, REAL: число с двойной точностью и плавающей точкой.
- DECIMAL, NUMERIC: величины повышенной точности.
- DATE: дата.
- DATETIME: дата и время.
- TIMESTAMP: временная метка.
- TIME: время в формате hh:mm:ss.
- YEAR: год (по умолчанию хранится в виде 4 цифр, но можно настроить и 2).
- CHAR: строка фиксированной длины.
- VARCHAR: строки переменных.
- TINYBLOB, TINYTEXT: Тип TEXT позволяет хранить текст, а BLOB – изображения, звук, электронные документы и т.п. Максимальная длина – 225 символов.
- BLOB, TEXT: большие объемы текста, максимум 65535 символов.
- MEDIUMBLOB, MEDIUMTEXT: аналогично предыдущему, но максимум до 16777215 символов.
- LONGBLOB, LONGTEXT: аналогично предыдущему, но максимум до 4294967295 символов.
- ENUM: принимает только одно из значений заданного множества.
- SET: принимает любой или все элементы из значений заданного множества.
Преимущества MySQL
- Простота в работе: MySQL очень просто установить и настроить. Сторонние инструменты, в том числе визуализаторы (интерфейсы) значительно упрощают работу с данными.
- Функциональность: MySQL поддерживает огромное количество функций SQL.
- Безопасность: MySQL предоставляет много встроенных продвинутых функций для защиты данных.
- Масштабируемость и производительность: MySQL может работать с большими объёмами данных.
Недостатки MySQL
- Ограничения: структура MySQL накладывает некоторые ограничения, из-за которых не смогут работать продвинутые приложения.
- Уязвимости: метод обработки данных, применяемый в MySQL, делает эту СУБД немного менее надёжной по сравнению с другими СУБД.
- Медленное развитие: хотя MySQL является продуктом с открытым исходным кодом, он очень медленно развивается. Однако тут следует заметить, что на MySQL основано несколько полноценных баз данных (например, MariaDB).
Когда использовать MySQL
- Распределенные операции: автономный сервер баз данных MySQL поддерживает множество операций и предоставляет несколько дополнительных функций.
- Высокая безопасность данных: MySQL предлагает высокую защиту данных.
- Веб-сайты и веб-приложения: несмотря на ограничения MySQL может поддерживать работу почти любого сайта и веб-приложения. Этот гибкий и масштабируемый инструмент прост в использовании.
- Пользовательские решения: MySQL можно подогнать под строгие требования сайта или приложения.
Когда лучше не использовать MySQL
- Конфликты с SQL: поскольку MySQL всё же полностью не реализует стандартов SQL, он не полностью совместим с SQL. Потому MySQL не всегда можно интегрировать с другой СУБД.
- Слабая поддержка параллелизма: несмотря на то, что MySQL хорошо выполняет операции чтения, одновременные операции чтения и записи могут вызвать проблемы.
- Отсутствие некоторых функций (например, полнотекстового поиска).
Колоночные СУБД
Колоночные СУБД очень похожи на реляционные. Они так же состоят из строк, которые имеют атрибуты, а строки группируются в таблицах. Различия в логических моделях несущественные, а вот на уровне физического хранения данных различия значительные.
В реляционных СУБД данные хранятся «построчно», это означает что для считывания значения определенной колонки, придется прочитать практически всю строку, как минимум от первой до нужной колонки. В колоночной СУБД данные хранятся «поколоночно», т.е. колонка — это как отдельная таблица. Соответственно чтение будет происходить из конкретного столбца сразу. На практике это реально работает очень быстро (проверено мной на нескольких реализованных хранилищах данных).
Основные преимущества колоночных СУБД – эффективное выполнения сложных аналитических запросов на больших объемах, и легкое, практически мгновенное, изменение структуры таблиц с данными, плюс существенная компрессия и сжатие, которое позволяет значительно экономить место.
Яркие представители колоночных СУБД — Sybase IQ (ныне SAP IQ), Vertica, ClickHouse, Google BigTable, InfoBright, Cassandra.
Когда выбирать колоночные СУБД
Один из весомых аргументов за использование именно колоночной СУБД — это если вы хотите построить хранилище данных, и планируете делать выборки со сложными аналитическими вычислениями. Косвенный признак, который так же может сигнализировать о том, что имеет смысл, хотя бы посмотреть в сторону колоночных СУБД — это если количество строк, из которых делаются выборки, превышает сотни миллионов.
Когда не выбирать колоночные СУБД
Учитывая специфику колоночных СУБД, будет не эффективно ее использовать, если выборки достаточно простые, параметры выборки статичны, и если преобладают выборки по ключевым значениям. Так же, если количество строк в таблице, из которой делается выборка, меньше сотен миллионов строк, то скорее всего не будет большого преимущества, по сравнению с реляционной СУБД.
Нужно так же иметь ввиду, что в колоночных СУБД могут быть и другие ограничения. Например, может отсутствовать поддержка транзакций, а язык запросов может отличаться от классического SQL, и прочее.




