Мета теги страниц сайта: title, description, keywords, robots и другие
Содержание:
- Группа значений атрибута HTTP-EQUIV
- Структурированные данные (JSON-LD)
- Где указать кодировку сайта
- Compliance status
- Атрибуты¶
- Different types of charset
- Кодировки стандарта UNICODE
- Понимание Схем Кодирования
- Принципы работы
- Что это такое?
- Что такое кодировка
- Подытожим: все еще есть над чем работать
- Что такое кодировка текста и с чем ее едят?
- Указание кодировки документа
- keywords (ключевые слова)
- description (краткое описание)
- How does it work?
- Is it a ranking factor for SEO?
- About
Группа значений атрибута HTTP-EQUIV
«Content-Type»
Content-Type определяет тип документа и его кодировку.
HTML-код с «Content-Type»:
В HTML5 указание кодировки упрощено:
«refresh»
Refresh — задержка времени (в секундах) перед тем, как браузер обновит страницу. Кроме того, может использоваться автоматическая загрузка другой html-страницы с заданным адресом (url).
HTML-код с «refresh»:
Браузер поймет эту запись, как через 5 секунд загрузить новую страницу, указанную в параметре URL, в данном случае это переход на сайт wm-school.ru.
Значение «refresh» позволяет создавать перенаправление (редирект) на другой сайт. Если URL не указан, произойдет автоматическое обновление текущей страницы через количество секунд, заданных в атрибуте content.
Обратите внимание, что кавычки в указании URL-адреса перед http не ставятся.
Структурированные данные (JSON-LD)
Структурированные данные — это стандартизированный формат для предоставления информации о странице и классификации ее содержимого.
Разметка данных (вне зависимости от их типа) с помощью JSON-LD есть на 34,1% сайтов. Чаще всего JSON-LD используют для разметки поиска по сайту. Благодаря этому в результатах Google-поиска может показываться дополнительная строка поиска по сайту в сниппете. Также популярна разметка социальных профилей, логотипа, данных локального бизнеса.
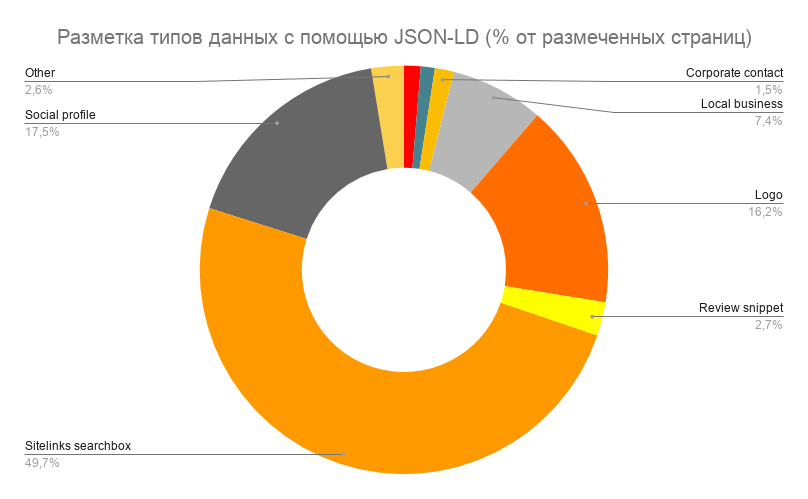
Больше о том, что такое JSON-LD, читайте здесь. О быстрой настройке микроразметки разными способами мы тоже писали.
Где указать кодировку сайта
Если проблема возникла на вашем сайте, способ исправления зависит от вида сайта. Для одностраничника достаточно указать кодировку в мета-теге страницы, а для большого сайта есть разные варианты:
- кодировка в мета-теге;
- кодировка в .htaccess;
- кодировка документа;
- кодировка в базе данных MySQL.
Кодировка в мета-теге
Добавьте указание кодировки в head файла шаблона сайта.
При создании документа HTML укажите тег meta в начале в блоке head. Некоторые браузеры могут не распознать указание кодировки, если оно будет ниже.
Мета-тег может выглядеть так:
или так:
В HTML5 они эквивалентны.
 Тег кодировки в HTML
Тег кодировки в HTML
В темах WordPress обычно тег «charset» с кодировкой указан по умолчанию, но лучше проверить.
Кодировка в файле httpd.conf
Инструкции для сервера находятся в файле httpd.conf, обычно его можно найти на пути «/usr/local/apache/conf/».
Если вам нужно сменить кодировку Windows-1251 на UTF-8, замените строчку «AddDefaultCharset windows-1251» на «AddDefaultCharset utf-8».
Убедитесь, что сервер не передает HTTP-заголовки с конфликтующими кодировками.
Кодировка в .htaccess
Добавьте кодировку в файл .htaccess:
- Откройте панель управления хостингом.
- Перейдите в корневую папку сайта.
- В файле .htaccess добавьте в самое начало код:
- для указания кодировки UTF-8 — AddDefaultCharset UTF-8;
- для указания кодировки Windows-1251 — AddDefaultCharset WINDOWS-1251.
- Перейдите на сайт и очистите кэш браузера.
Кодировка документа
Готовые файлы HTML важно сохранять в нужной кодировке сайта. Узнать текущую кодировку файла можно через Notepad++: откройте файл и зайдите в «Encoding»
Меняется она там же: чтобы сменить кодировку на UTF-8, выберите «Convert to UTF-8 without BOOM». Нужно выбрать «без BOOM», чтобы не было пустых символов.
Кодировка Базы данных
Выбирайте нужную кодировку сразу при создании базы данных. Распространенный вариант — «UTF-8 general ci».
Где менять кодировку у БД:
- Кликните по названию нужной базы в утилите управления БД phpMyAdmin и откройте ее.
- Кликните на раздел «Операции»:
- Введите нужную кодировку для базы данных MySQL:
- Перейдите на сайт и очистите кэш.
С новой БД проще, но если вы меняете кодировку у существующей базы, то у созданных таблиц и колонок заданы свои кодировки, которые тоже нужно поменять.
Для всех таблиц, колонок, файлов, сервера и вообще всего, что связано с сайтом, должна быть одна кодировка.
Проблема может не решиться, если все дело в кодировке подключения к базе данных. Что делать:
- Подключитесь к серверу с правами mysql root пользователя:mysql -u root -p
- Выберите нужную базу:USE имя_базы;
- Выполните запрос:SET NAMES ‘utf8’;
Если вы хотите указать Windows-1251, то пишите не «utf-8», а «cp1251» — обозначение для кодировки Windows-1251 у MySQL.
Чтобы установить UTF-8 по умолчанию, откройте на сервере my.cnf и добавьте следующее:
Вы когда-нибудь сталкивались с проблемами кодировки на сайте?
Compliance status
We firmly believe that the internet should be available and accessible to anyone, and are committed to providing a website that is accessible to the widest possible audience,
regardless of circumstance and ability.
To fulfill this, we aim to adhere as strictly as possible to the World Wide Web Consortium’s (W3C) Web Content Accessibility Guidelines 2.1 (WCAG 2.1) at the AA level.
These guidelines explain how to make web content accessible to people with a wide array of disabilities. Complying with those guidelines helps us ensure that the website is accessible
to all people: blind people, people with motor impairments, visual impairment, cognitive disabilities, and more.
This website utilizes various technologies that are meant to make it as accessible as possible at all times. We utilize an accessibility interface that allows persons with specific
disabilities to adjust the website’s UI (user interface) and design it to their personal needs.
Additionally, the website utilizes an AI-based application that runs in the background and optimizes its accessibility level constantly. This application remediates the website’s HTML,
adapts Its functionality and behavior for screen-readers used by the blind users, and for keyboard functions used by individuals with motor impairments.
Атрибуты¶
- Задаёт кодировку документа.
- Устанавливает значение атрибута, заданного с помощью или .
- Предназначен для конвертирования метатега в заголовок HTTP.
- Имя метатега, также косвенно устанавливает его предназначение.
charset
Указывает кодировку документа. Атрибут введён в HTML5 и предназначен для сокращения формы , которая задавала кодировку в предыдущих версиях HTML и XHTML.
Синтаксис
Значения
Название кодировки, например UTF-8.
Значение по умолчанию
Нет.
content
устанавливает значение атрибута, заданного с помощью или . Атрибут может содержать более одного значения, в этом случае они разделяются запятыми или точкой с запятой.
Некоторые значения атрибута для , предназначенных для поисковых роботов, приведены в табл. 1.
| Значение | Описание |
|---|---|
| Разрешает роботу индексировать данную страницу. | |
| Запрещает роботу индексировать текущую страницу. Она не попадает в базу поисковика и её невозможно будет найти через поисковую систему. | |
| Разрешает роботу переходить по ссылкам на данной странице. | |
| Запрещает роботу переходить по ссылкам на данной странице. При этом всем ссылкам не передаётся ТИЦ (тематический индекс цитирования) и PagePank. | |
| Запрещает роботу кэшировать данную страницу. |
Допустимые значения атрибута для , которые предназначены для управления просмотром сайта на мобильных устройствах, приведены в табл. 2.
| Значение | Допустимые значения | Описание |
|---|---|---|
| device-width или целое положительное число | Устанавливает ширину области просмотра в пикселях. | |
| device-height или целое положительное число | Устанавливает высоту области просмотра в пикселях. | |
| Число от 0.0 до 10.0 | Устанавливает соотношение между шириной устройства (device-width в портретном режиме или device-height в ландшафтном режиме) и размером области просмотра. | |
| Число от 0.0 до 10.0 | Задаёт максимальное значение масштаба. Должно быть больше или равно minimum-scale, в противном случае игнорируется. | |
| Число от 0.0 до 10.0 | Задаёт минимальное значение масштаба. Должно быть меньше или равно maximum-scale, в противном случае игнорируется. | |
| yes или no | Если указано no, то пользователь не сможет масштабировать веб-страницу. По умолчанию используется yes. |
Синтаксис
Значения
Строка символов, которую надо взять в одинарные или двойные кавычки.
Значение по умолчанию
Нет.
http-equiv
Браузеры преобразовывают значение атрибута , заданное с помощью , в формат заголовка ответа HTTP и обрабатывают их, как будто они прибыли непосредственно от сервера.
Синтаксис
Значения
Любой подходящий идентификатор. Ниже приведены некоторые допустимые значения атрибута .
- Тип кодировки документа.
Устанавливает дату и время, после которой информация в документе будет считаться устаревшей.
Способ кэширования документа.
- Загружает другой документ в текущее окно браузера.
Значение по умолчанию
Нет.
name
Устанавливает идентификатор метатега для пары «». Одновременно использовать атрибуты и не допускается.
Синтаксис
Значения
Любой подходящий идентификатор. Ниже приведены некоторые допустимые значения атрибута .
- Имя автора документа.
- Описание текущего документа.
- Список ключевых слов, встречающихся на странице.
- Управляет просмотром сайта на мобильных устройствах.
Значение по умолчанию
Нет.
Different types of charset
Most charsets came about from individual manufacturers catering to the needs of their clients. Most charsets are incompatible with each other (with a few exceptions). The three most common charsets are, ASCII (1968), ISO 8859-1 (1987) and UTF-8 (1996).
ASCII
Charset for the English language. Contains 7-bits that are mapped to 128 characters. Each letter is assigned a number from 0 to 127. This code set is quite restricted, but being one of the pioneers sparked the creation of a character set for each of the other languages. Most computers use ASCII codes to represent text.

Unicode
Unicode was created to unify 135 modern and historic languages under one standard. Unicode is a standard and not a charset itself. As of May 2019, version 12.1, Unicode contains 137,994 characters including symbols and emojis. The Unicode standard defines UTF-8, UTF-16, and UTF-32
UTF-8
Now the dominant code of the internet. UTF-8 is used in 94% of websites. It encodes the most common characters, basic numbers, and English with 8-bits. UTF-8 uses a minimum of 1 byte. UTF-8 is also identical to ASCII for English. This means that any ASCII text is also a UTF-8 text.

UTF-16
Unicode with 16 bits. While used originally with systems such as Windows and Java, it never really took off with Linux and macOS. Today UTF-16 is used with 0.01% of webpages. UTF-16 uses a minimum of 2 bytes.

Image Source
UTF-32
Unicode with 32 bits. The advantage of UTF-32 is that the Unicode points are directly indexed. The disadvantage is that it is not efficient with its use of space as it always uses 4 bytes. This means up to twice the size of UTF-16 and four times to that of UTF-8.
Кодировки стандарта UNICODE
Юникод (англ. Unicode) — стандарт кодирования символов, позволяющий представить знаки почти всех письменностей мира, и специальных символов. Представляемые в юникоде символы кодируются целыми числами без знака. Юникод имеет несколько форм представления символов в компьютере: UTF-8, UTF-16 (UTF-16BE, UTF-16LE) и UTF-32 (UTF-32BE, UTF-32LE). (Англ. Unicode transformation format — UTF).UTF-8 — это в настоящее время распространённая кодировка, которая нашла широкое применение в операционных системах и веб-пространстве. Текст, состоящий из символов Unicode с номерами меньше 128 (область с кодами от U+0000 до U+007F), содержит символы набора ASCII с соответствующими кодами. Далее расположены области знаков различных письменностей, знаки пунктуации и технические символы. Под символы кириллицы выделены области знаков с кодами от U+0400 до U+052F, от U+2DE0 до U+2DFF, от U+A640 до U+A69F.
Кодировка UTF-8 является универсальной и имеет внушительный резерв на будущее. Это делает ее наиболее удобной кодировкой для использования в интернете.
HTML Символы
Кодирование URL
Понимание Схем Кодирования
Кодировка символов может принимать различные формы в зависимости от количества символов, которые она кодирует.
Количество закодированных символов имеет прямое отношение к длине каждого представления, которое обычно измеряется как количество байтов. Наличие большего количества символов для кодирования по существу означает необходимость более длинных двоичных представлений.
Давайте рассмотрим некоторые из популярных схем кодирования на практике сегодня.
4.1. Однобайтовое кодирование
Одна из самых ранних схем кодирования, называемая ASCII (Американский стандартный код для обмена информацией), использует однобайтовую схему кодирования. По сути, это означает, что каждый символ в ASCII представлен семибитными двоичными числами. Это все еще оставляет один бит свободным в каждом байте!
Ascii 128-символьный набор охватывает английские алфавиты в нижнем и верхнем регистрах, цифры и некоторые специальные и контрольные символы.
Давайте определим простой метод в Java для отображения двоичного представления символа в определенной схеме кодирования:
String convertToBinary(String input, String encoding)
throws UnsupportedEncodingException {
byte[] encoded_input = Charset.forName(encoding)
.encode(input)
.array();
return IntStream.range(0, encoded_input.length)
.map(i -> encoded_input)
.mapToObj(e -> Integer.toBinaryString(e ^ 255))
.map(e -> String.format("%1$" + Byte.SIZE + "s", e).replace(" ", "0"))
.collect(Collectors.joining(" "));
}
Теперь символ ” T ” имеет кодовую точку 84 в US-ASCII (ASCII в Java называется US-ASCII).
И если мы используем наш метод утилиты, мы можем увидеть его двоичное представление:
assertEquals(convertToBinary("T", "US-ASCII"), "01010100");
Это, как мы и ожидали, семиразрядное двоичное представление символа “T”.
Исходный ASCII оставил самый значимый бит каждого байта неиспользованным. В то же время ASCII оставил довольно много непредставленных символов,
Исходный ASCII оставил самый значимый бит каждого байта неиспользованным. || В то же время ASCII оставил довольно много непредставленных символов,
Было предложено и принято несколько вариантов схемы кодирования ASCII.
Многие расширения ASCII имели разные уровни успеха, но, очевидно, это
Одним из наиболее популярных расширений ASCII был ISO-8859-1 , также называемый “ISO Latin 1”.
4.2. Многобайтовое кодирование
Поскольку потребность в размещении все большего количества символов росла, однобайтовые схемы кодирования, такие как ASCII, не были устойчивыми.
Это привело к появлению многобайтовых схем кодирования, которые имеют гораздо большую емкость, хотя и за счет увеличения требований к пространству.
BIG 5 и SHIFT-JIS являются примерами многобайтовых схем кодирования символов, которые начали использовать как один, так и два байта для представления более широких наборов символов . Большинство из них были созданы для того, чтобы представлять китайские и аналогичные сценарии, которые имеют значительно большее количество символов.
Давайте теперь вызовем метод convertToBinary с вводом как “語”, китайский символ, и кодирование как “Big5”:
assertEquals(convertToBinary("語", "Big5"), "10111011 01111001");
Вывод выше показывает, что кодировка Big5 использует два байта для представления символа “語”.
полный список кодировок символов, наряду с их псевдонимами, ведется Международным органом по номерам.
Принципы работы
UTF-8 является лишь представлением Unicode в 8-битном виде. Символы с кодами меньше 128 представляются одним байтом (Латинский алфавит, простейшие знаки препинания и арабские цифры), а так как в Unicode они повторяют ASCII, то текст написанный только этими символами будет являться текстом в ASCII.
Символы с кодами от:
- 128 — 2-мя байтами.(Кириллица, расширенная латиница, арабский, армянский, греческий, еврейский и коптский алфавит, сирийское письмо, некоторые знаки препинания).
- 2048 — 3-мя байтами (Все другие современные формы письменности, сложные знаки препинания; математические и другие специальные символы).
- 65536 — 4-мя байтами (Музыкальные символы, смайлы, редкие китайские иероглифы, вымершие формы письменности).
5 и 6 байтов не используется в Unicode.
Что это такое?
ASCII представляет собой кодировочную таблицу печатных символов (см. скриншот №1), набираемых на компьютерной клавиатуре, для передачи информации и некоторых кодов. Иными словами происходит кодирование алфавита и десятичных цифр в соответствующие символы, представляющие и несущие в себе необходимую информацию.

Кодировка ASCII была разработана в Америке, поэтому стандартная кодировочная таблица обычно включает в себя английский алфавит с цифрами, что в общей сложности составляет около 128 символов. Но тогда возникает справедливый вопрос: что делать, если необходима кодировка национального алфавита?
Для решения подобных вопросов были разработаны другие версии таблицы ASCII. Например, для языков с иноязычной структурой были или убраны буквы английского алфавита, или к ним добавлялись дополнительные символы в виде национального алфавита. Так, в кодировке ASCII могут присутствовать русские буквы для национального использования (см. скриншот №2).

Где применяется система кодировки ASCII?
Данная кодировочная система необходима не только для набора текстовой информации на клавиатуре. Она также используется в графике. Например, в программе ASCII Art Maker графические изображения различных расширений состоят из спектра символов кодировки ASCII (см. скриншот №3).

Как правило, подобные программы можно разделить на те, что выполняют функцию графических редакторов, инвертируя изображение в текст, и на те, что конвертируют изображение в ASCII-графику. Всем известный смайлик (или как его еще называют «улыбающееся человеческое лицо») тоже является примером кодировочного символа.
Данный метод кодировки также может быть востребован во время написания или создания документа HTML. Например, вы вводите определённый и необходимый вам набор знаков, а при просмотре самой страницы на экран будет выведен символ, соответствующий данному коду.
Кроме всего прочего данный вид кодировки необходим при создании многоязычного сайта, потому что знаки, которые не входят в ту или иную национальную таблицу, нужно будет заменить ASCII кодами. Если читатель непосредственно связан с информационно-коммуникативными технологиями (ИКТ), то ему будет полезно ознакомиться и с такими системами как:
- Переносимый набор символов;
- Управляющие символы;
- EBCDIC;
- VISCII;
- YUSCII;
- Юникод;
- ASCII art;
- КОИ-8.
Свойства таблицы ASCII
Как и любая систематизированная программа, ASCII обладает своими характерными свойствами. Так, например, десятеричная система исчисления (цифры от 0 до 9) преобразуется в двоичную систему исчисления (т.е. каждая десятеричная цифра преобразуется в двоичную 288=1001000 соответственно).
Буквы, располагающиеся в верхних и нижних колонках, отличаются друг от друга лишь битом, что существенно снижает уровень сложности проверки и редактирование регистра.
При всех этих свойствах кодировка ASCII работает как восьми битная, хотя изначально предусматривалась как семи битная.
Применение ASCII в программах Microsoft Office:
В случае необходимости данный вариант кодирования информации может быть использован в Microsoft Notepad и Microsoft Office Word. В рамках этих приложений документ может быть сохранен в формате ASCII, но в этом случае при наборе текста невозможно будет использование некоторых функций.
В частности, будет недоступно выделение жирным и полужирным шрифтом, потому что кодирование сохраняет лишь смысл набранной информации, а не общий вид и форму. Добавить такие коды в документ вы можете с помощью следующих программных приложений:
- Microsoft Excel;
- Microsoft FrontPage;
- Microsoft InfoPath;
- Microsoft OneNote;
- Microsoft Outlook;
- Microsoft PowerPoint;
- Microsoft Project.
При этом стоит учитывать, что набирая код ASCII в этих приложениях необходимо удерживать нажатой клавиатурную клавишу ALT.
Конечно, все необходимые коды требует более длительного и обстоятельного изучения, но это выходит за пределы нашей сегодняшней статьи. Надеюсь, что она оказалась для Вас действительно полезной.
До новых встреч!
Виталий Черкасовавтор
Что такое кодировка
Кодировка – специальный метод, позволяющий отображать текст на экране таким образом, чтобы он был понятен каждому пользователю. Все символы, которые мы видим в интернете, – это буквы и цифры только для нас, компьютер их не понимает. Он воспринимает информацию в байтах, весь текст на экране монитора – это совокупность байтов. У каждого символа есть свое кодовое значение, которое компьютер использует при выводе слов и чисел на экран.
Вот наглядный пример того, как воспринимается компьютером латинский алфавит и прочие символы:
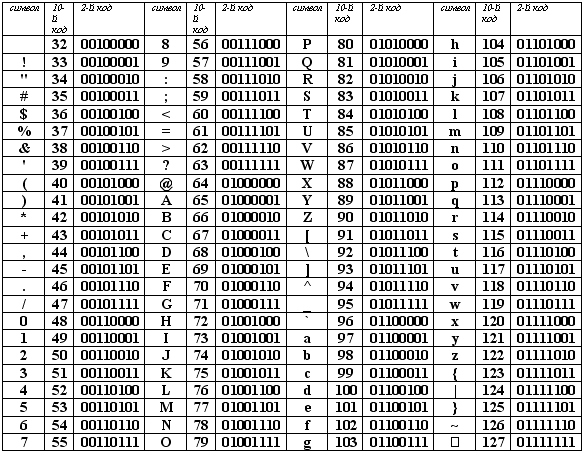
Если никакая кодировка не установлена, вместо символов мы увидим такие значения. Чтобы понять компьютер, необходимо установить нужную кодировку для расшифровки символов из этой таблицы.
Подытожим: все еще есть над чем работать
Понимание того, как выглядит средняя веб-страница, дает представление о текущих тенденциях. И тут же возникают вопросы.
Почему вебмастера редко прописывают alt для изображений? Почему заголовки h1 есть только на 60% страниц? Почему title и description заполняют далеко не все? Почему не спешат внедрять микроразметку JSON-LD? А ведь это базовое SEO…
Хочется сказать, что все это неважно — все-таки анализировались страницы из ТОП-20 Google. То есть Google считает их в общей массе авторитетными — даже без «альтов»
Но не забываем, что SEO — это комплекс факторов. Мы рассмотрели лишь малый технический аспект. Даже если взять только оптимизацию сайта, то там более 60 разных работ. А еще ссылки, упоминания, локализация, поведенческие факторы…
Так что от «подкрутки» базового технического SEO ваш сайт точно не пострадает. А если учесть, что на других площадках не все так хорошо, то рост более чем реален.
Что такое кодировка текста и с чем ее едят?
Начать хотелось бы с того, что этой статьи могло бы и не быть, т.к. компьютерно-юзательная жизнь автора этих строк протекала вполне себе спокойно и достойно. Но вот в один прекрасный день, шляясь по просторам сети Интернет не со своего ПК, я столкнулся с непонятными явлениями на некоторых сайтах. Заходя на интернет-ресурсы, я видел не привычный нам русский алфавит и красивый понятный текст, а какую-то ересь в виде непонятной последовательности символов. Выглядела она примерно вот так (см. изображение).
Сначала я подумал, что моя любимая Мозилка (браузер Firefox) перегрелась и ей пора вызывать неотложку, но потом начал понимать, что проблема, скорее всего, на стороне ресурса сети и кроется она в неправильно настроенной кодировке. Это действительно оказалось так, и пошаманив немного с бубном, проблемка была оперативно решена. Результатом же всех моих любовных похождений и стал сегодняшний материал. Собственно, поехали разбираться в деталях.
Всю информацию, представленную в цифровом виде и находящуюся в глобальной паутине, нужно рассматривать с двух сторон: первая — со стороны пользователя (красивый и ухоженный текст на экране монитора) и вторая – со стороны поисковой машины (некий программный код, состоящий из различных тегов/метатегов, таблицы символов и прочее).
Если Вы хоть немного знакомы с языком разметки гипертекста (HTML), то должны быть в курсе, что сайт глазами поисковых машин (Google, Яндекс) видится не как обычный текст, а как структурированный документ, состоящий из последовательностей различного рода тегов. Чтобы было понятней, о чем я говорю, давайте взглянем на всеми нами любимый сайт Заметки Сис.Админа” проекта , но не глазами обычного пользователя, а «глазами» поисковика. Для этого нажимаем сочетание клавиш Сtrl+U (для браузеров Firefox и Chrome) и видим следующую картину (см. изображение):
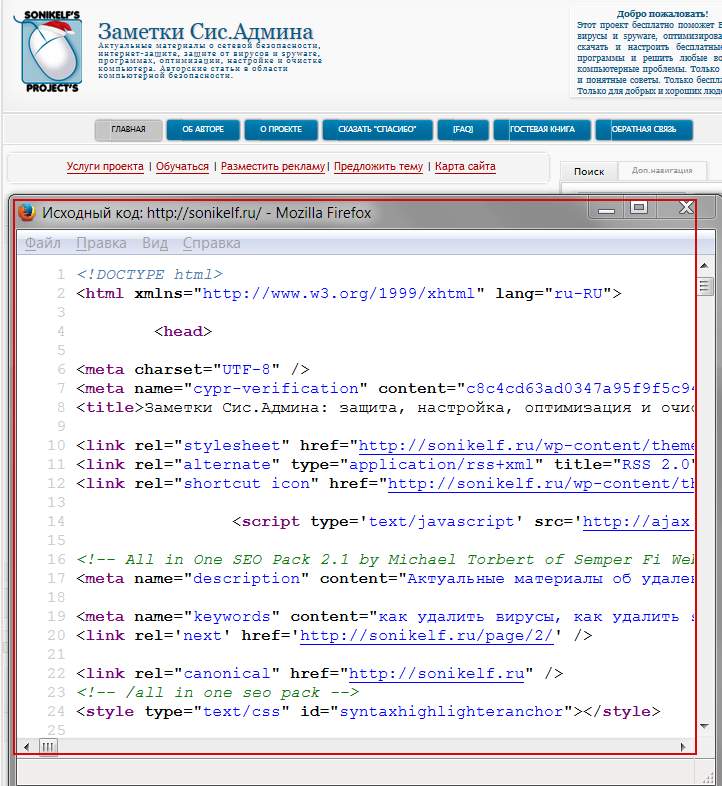
Перед нами машинный вариант sonikelf.ru, вот в таком вот непрезентабельном виде он подается поисковым системам и именно в таком виде они его и кушают. Если бы мы просто взяли и “засандалили” варианты статей из блокнота или Word обычным текстом, машины бы им не то что подавились, они бы даже и есть его не стали. Итак, перед нами главная страница проекта в HTML-виде
Обратите внимание на строку с надписью UTF-8, это не что иное, как пресловутая кодировка текста страницы, именно она и отвечает за формат вывода информации в презентабельном виде, в результате чего через браузер мы видим нормальный текст
Теперь давайте разберемся, почему же происходит так, что порой на экране монитора мы видим кракозябры. Все очень просто, проблема кроется в открытии файла в неверной кодировке. Если перевести на бытовой язык, то допустим Вас послали в магазин за молоком, а Вы притарабанили хлеб, вроде бы тоже съестное, но совсем другой формат продукта.
Итак, теперь давайте разбираться с теорией и для этого введем некоторые определения.
- Кодировка (или “Charset”) – соответствие набора символов набору числовых значений. Нужна для “сливания” информации в интернет, т.е. текстовая информация преобразуется в биты данных;
- Кодовая страница (“Codepage”) – 1 байтовая (8 бит) кодировка;
- Количество значений, принимаемое 1 байтом – 256 (два в восьмой).
Соответствие “символ-изображение” задается с помощью специальных кодовых таблиц, где каждому символу уже присвоен свой конкретный числовой код. Таких таблиц существует достаточно много, и в разных таблицах один и тот же символ может идентифицироваться по-разному (ему могут соответствовать разные числовые коды).
Все кодировки различаются количеством байт и набором специальных знаков, в которые преобразуется каждый символ исходного текста.
Примечание:Декодирование – операция, в результате которой происходит преобразование кода символа в изображение. В результате этой операции информация выводится на экран монитора пользователя.
В общем.. С определениями разобрались, а теперь давайте узнаем, какие же (кодировки) бывают.
Указание кодировки документа
Тег <meta> позволяет сообщить браузеру посетителя, какой набор символов и какую кодировку необходимо установить на веб-странице. Атрибут charset (HTML тега <meta>) задает кодировку символов для HTML документа.
<!DOCTYPE html> <html> <head> <meta charset = "utf-8" > <!-- задаем кодировку документа UTF-8 --> <title>Пример использования тега <meta></title> </head> <body> <h2>Это заголовок.</h2> <p>Это параграф.</p> </body> </html>
В данном примере мы задали кодировку документа UTF-8 с использованием элемента <meta> и атрибута charset. Кодировка UTF-8 одна из общепринятых и стандартизированных кодировок текста, которая позволяет хранить символы Юникода.
Стандарт HTML 5 не запрашивает конкретную кодировку, но дает рекомендацию использовать кодировку UTF-8.
Не рекомендуется использовать кодировки ASCII, CESU-8, UTF-7, BOCU-1, SCSU и UTF-32 по различным причинам.
Считается хорошей практикой, и настоятельно рекомендуется определять набор символов (кодировку), используя атрибут charset. Атрибут charset является лишь частью алгоритма определения кодировки страницы браузером. Рекомендуется указывать кодировку символов первым элементом (если используется несколько)
Обратите внимание, что для одного документа указывается только одна кодировка
В теории, любая кодировка может быть использована, но ни один браузер не понимает их все. Используя более распространенную кодировку символов, увеличивает шанс того, что браузер будет её понимать.
Полный перечень кодировок доступен на сайте iana.org.
keywords (ключевые слова)
У любого сайта есть набор ключевых слов и словосочетаний, по которым поисковые системы ищут нужные ресурсы в сети. Именно эти слова и должны составлять содержимое keywords.
Самый простой способ подобрать нужные ключевые слова для текущей страницы — это определить по каким словам вы сами стали бы искать материал, представленный на ней? Вот это и будут нужные ключевые слова. Пример:
<meta name="keywords" content="мета тег, meta, метаданные, keywords, description">
Ключевые слова указываются через запятую или пробел и могут быть написаны в любом регистре. Рекомендуется указывать не более 10-15 ключевых слов или словосочетаний.
В настоящее время поисковые системы стали более продвинутые и определяют категорию, к которой относится информация, по содержимому веб-страницы, а ключевые слова отошли на второй план или полностью игнорируются.
description (краткое описание)
Значение description используется для краткого описания содержимого, расположенного на текущей странице. Рекомендуемая максимальная длина такого описания не должна превышать 180 символов:
<meta name="description" content="Описание содержимого на данной странице">
Краткое описание страницы может быть использовано поисковыми система на странице с результатами поиска под названием страницы и URL-адреса:
Также краткое описание используется на сайтах некоторых соцсетей, при добавлении ссылки:
При составлении краткого описания следует учитывать следующие моменты:
- в описании нужно указывать именно ту информацию, которая отражает содержимое, опубликованное на данной странице;
- описание должно быть уникальным и не должно повторяться для разных страниц;
- старайтесь в описание страницы также включать необходимые ключевые слова, которые будут учитываться в поисковых запросах.
Примечание: краткое описание, расположенное под ссылкой на странице с результатами поиска, называется сниппетом.
How does it work?
Meta Charset is what determines how text is transmitted and stored. This text data is usually converted to binary first and then there needs to be a kind of cipher that connects characters with their correct binary equivalents.
When this data is eventually decoded, the character encoding must be known beforehand or there could be complications. An example of these can be seen in browsers when you’re looking at a webpage. Information about the kind of character set used comes from the server or is written directly by the developer. Unfortunately, there is a myriad of character sets and this means diverse ways of matching binary codes to characters and bytes.
For content developers and authors, choosing the UTF-8 character set for your content means that you can use a single character set to multiple characters needs thereby simplifying things greatly without the need to track and convert multiple times. This means it would be easier to surf through your content without getting confusing characters and garbage
Is it a ranking factor for SEO?
The character set is not a ranking factor for search engine optimization. Most search engines focus on the important goal of delivering relevant, useful content to those who seek it and as such does not consider other outside factors that do not contribute to that goal.
So your character set matters because of how you transmit information but search engines are not interested in it. Using other charsets apart from Utf-8 will not decrease your SEO ranking because to a large extent it doesn’t matter what character encoding you use as long as the search engine is able to get information to the end users.
About
- Character set: Our website uses the UTF-8 character set, so your input data is transmitted in that format. Change this option if you want to convert the data to another character set before encoding. Note that in case of text data, the encoding scheme does not contain the character set, so you may have to specify the appropriate set during the decoding process. As for files, the binary option is the default, which will omit any conversion; this option is required for everything except plain text documents.
- Newline separator: Unix and Windows systems use different line break characters, so prior to encoding either variant will be replaced within your data by the selected option. For the files section, this is partially irrelevant since files already contain the corresponding separators, but you can define which one to use for the «encode each line separately» and «split lines into chunks» functions.
- Encode each line separately: Even newline characters are converted to their Base64 encoded forms. Use this option if you want to encode multiple independent data entries separated with line breaks. (*)
- Split lines into chunks: The encoded data will become a continuous text without any whitespaces, so check this option if you want to break it up into multiple lines. The applied character limit is defined in the MIME (RFC 2045) specification, which states that the encoded lines must be no more than 76 characters long. (*)
- Perform URL-safe encoding: Using standard Base64 in URLs requires encoding of «+», «/» and «=» characters into their percent-encoded form, which makes the string unnecessarily longer. Enable this option to encode into an URL- and filename- friendly Base64 variant (RFC 4648 / Base64URL) where the «+» and «/» characters are respectively replaced by «-» and «_», as well as the padding «=» signs are omitted.
- Live mode: When you turn on this option the entered data is encoded immediately with your browser’s built-in JavaScript functions, without sending any information to our servers. Currently this mode supports only the UTF-8 character set.
(*) These options cannot be enabled simultaneously since the resulting output would not be valid for the majority of applications.Safe and secureCompletely freeDetails of the Base64 encodingDesignExampleMan is distinguished, not only by his reason, but …ManTWFu
| Text content | M | a | n | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| ASCII | 77 | 97 | 110 | |||||||||
| Bit pattern | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 |
| Index | 19 | 22 | 5 | 46 | ||||||||
| Base64-encoded | T | W | F | u |




