Использование csv-файла для импорта данных в service manager
Содержание:
- Файлы CSV
- 3) С Google Диска через PyDrive
- Что такое файл CSV?
- Диалекты и параметры форматирования¶
- Указание разделителя¶
- Запись¶
- Разбор CSV-файлов с pandas библиотекой
- Способы преобразования
- Запись файлов CSV
- Способ 4: Viewer от Groupdocs
- Pandas dataframe to_csv () синтаксис
- Чем открыть CSV файл на компьютере
- daСклонение: склонение ФИО, должностей, чисел, прилагательных, существительных на языке 1С + ТестЦентр Промо
- Рассмотрим загрузку CSV файла через утилиту bcp
- Как структурированы csv файлы
- Чтение файлов CSV
- Чтение CSV файла в PHP
Файлы CSV
Последнее обновление: 29.04.2017
Одним из распространенных файловых форматов, которые хранят в удобном виде информацию, является формат csv.
Каждая строка в файле csv представляет отдельную запись или строку, которая состоит из отдельных столбцов, разделенных запятыми. Собственно поэтому
формат и называется Comma Separated Values. Но хотя формат csv — это формат текстовых файлов, Python для упрощения работы с ним
предоставляет специальный встроенный модуль csv.
Рассмотрим работу модуля на примере:
import csv
FILENAME = "users.csv"
users = ,
,
]
with open(FILENAME, "w", newline="") as file:
writer = csv.writer(file)
writer.writerows(users)
with open(FILENAME, "a", newline="") as file:
user =
writer = csv.writer(file)
writer.writerow(user)
В файл записывается двухмерный список — фактически таблица, где каждая строка представляет одного пользователя. А каждый пользователь
содержит два поля — имя и возраст. То есть фактически таблица из трех строк и двух столбцов.
При открытии файла на запись в качестве третьего параметра указывается значение — пустая строка позволяет корректно считывать
строки из файла вне зависимости от операционной системы.
Для записи нам надо получить объект writer, который возвращается функцией . В эту функцию передается открытый файл.
А собственно запись производится с помощью метода Этот метод принимает набор строк. В нашем случае это двухмерный список.
Если необходимо добавить одну запись, которая представляет собой одномерный список, например, , то в этом случае можно вызвать метод
writer.writerow(user)
В итоге после выполнения скрипта в той же папке окажется файл users.csv, который будет иметь следующее содержимое:
Tom,28 Alice,23 Bob,34 Sam,31
Для чтения из файла нам наоборот нужно создать объект reader:
import csv
FILENAME = "users.csv"
with open(FILENAME, "r", newline="") as file:
reader = csv.reader(file)
for row in reader:
print(row, " - ", row)
При получении объекта reader мы можем в цикле перебрать все его строки:
Tom - 28 Alice - 23 Bob - 34 Sam - 31
Работа со словарями
В примере выше каждая запись или строка представляла собой отдельный список, например, . Но кроме того, модуль csv имеет
специальные дополнительные возможности для работы со словарями. В частности, функция csv.DictWriter() возвращает объект writer,
который позволяет записывать в файл. А функция csv.DictReader() возвращает объект reader для чтения из файла. Например:
import csv
FILENAME = "users.csv"
users =
with open(FILENAME, "w", newline="") as file:
columns =
writer = csv.DictWriter(file, fieldnames=columns)
writer.writeheader()
# запись нескольких строк
writer.writerows(users)
user = {"name" : "Sam", "age": 41}
# запись одной строки
writer.writerow(user)
with open(FILENAME, "r", newline="") as file:
reader = csv.DictReader(file)
for row in reader:
print(row, "-", row)
Запись строк также производится с помощью методов и . Но теперь каждая строка представляет собой отдельный словарь,
и кроме того, производится запись и заголовков столбцов с помощью метода writeheader(), а в метод csv.DictWriter в качестве второго параметра
передается набор столбцов.
При чтении строк, используя названия столбцов, мы можем обратиться к отдельным значениям внутри строки: .
НазадВперед
3) С Google Диска через PyDrive
Это самый сложный из трех методов. Я покажу его тем, кто загрузил файлы CSV на свой диск Google для контроля рабочего процесса. Сначала введите следующий код:
# Code to read csv file into Colaboratory:!pip install -U -q PyDrivefrom pydrive.auth import GoogleAuthfrom pydrive.drive import GoogleDrivefrom google.colab import authfrom oauth2client.client import GoogleCredentials# Authenticate and create the PyDrive client.auth.authenticate_user()gauth = GoogleAuth()gauth.credentials = GoogleCredentials.get_application_default()drive = GoogleDrive(gauth)
При появлении запроса нажмите на ссылку, чтобы получить аутентификацию, чтобы Google мог получить доступ к вашему диску. Вы должны увидеть экран с «Google Cloud SDK хочет получить доступ к вашей учетной записи Google» на вершине. Получив разрешение, скопируйте указанный код подтверждения и вставьте его в поле в Colab.
После завершения проверки перейдите к CSV-файлу на Google Диске, щелкните его правой кнопкой мыши и выберите «Получите доступную ссылку». Ссылка будет скопирована в ваш буфер обмена. Вставьте эту ссылку в строковую переменную в Colab.
link = 'https://drive.google.com/open?id=1DPZZQ43w8brRhbEMolgLqOWKbZbE-IQu' # The shareable link
То, что вы хотите, это часть идентификаторапосле знака равенства, Чтобы получить эту часть, введите следующий код:
fluff, id = link.split('=')print (id) # Verify that you have everything after '='
Наконец, введите следующий код, чтобы получить этот файл в кадре данных
downloaded = drive.CreateFile({'id':id}) downloaded.GetContentFile('Filename.csv') df3 = pd.read_csv('Filename.csv')# Dataset is now stored in a Pandas Dataframe
Что такое файл CSV?
Файл CSV (файл значений, разделенных запятыми) – это тип простого текстового файла, в котором для упорядочения табличных данных используется определенное структурирование. Поскольку это простой текстовый файл, он может содержать только фактические текстовые данные – другими словами, печатные символы ASCII или Unicode .
Структура CSV-файла определяется его именем. Обычно файлы CSV используют запятую для разделения каждого конкретного значения данных. Вот как выглядит эта структура:
Обратите внимание, что каждый фрагмент данных разделен запятой. Обычно первая строка идентифицирует каждый фрагмент данных, другими словами, имя столбца данных. Каждая последующая строка после этого является фактическими данными и ограничена только ограничениями размера файла. В общем, символ разделителя называется разделителем, и запятая используется не только одна. Другие популярные разделители включают символы табуляции ( ), двоеточия ( ) и точки с запятой ( ). Правильный анализ файла CSV требует, чтобы мы знали, какой разделитель используется
В общем, символ разделителя называется разделителем, и запятая используется не только одна. Другие популярные разделители включают символы табуляции ( ), двоеточия ( ) и точки с запятой ( ). Правильный анализ файла CSV требует, чтобы мы знали, какой разделитель используется.
Откуда берутся файлы CSV?
Файлы CSV обычно создаются программами, которые обрабатывают большие объемы данных. Это удобный способ экспортировать данные из электронных таблиц и баз данных, а также импортировать или использовать их в других программах. Например, вы можете экспортировать результаты программы интеллектуального анализа данных в файл CSV, а затем импортировать их в электронную таблицу для анализа данных, создания графиков для презентации или подготовки отчета для публикации.
С файлами CSV очень легко работать программно. Любой язык, который поддерживает ввод текстовых файлов и манипуляции со строками (например, Python), может работать с файлами CSV напрямую.
Диалекты и параметры форматирования¶
Для упрощения задания формата входных и выходных записей, конкретные параметры
форматирования группируются в диалекты. Диалект — это подкласс
класса, имеющий набор специфических методов и единственный
метод. Создавая объекты или , программист может
определить строку или подкласс класса как параметр
диалекта. В дополнение, или вместо, параметра dialect, программист может
также определить отдельные параметры форматирования, у которых есть те же имена
как атрибуты, определенный ниже для класса .
Диалекты поддерживают следующие атрибуты:
-
Односимвольная строка, используемая для отделения полей. По
умолчанию .
-
Управляет тем, как сущности quotechar, появляющиеся внутри поля, должены
самостоятельно закавычиваться. Когда , символ удваивается. Когда
, escapechar — используется как префикс к quotechar. По
умолчанию он .При выводе, если doublequote и не установлен escapechar,
поднимается , если quotechar найден в поле.
-
Односимвольная строка используемая writer, чтобы экранировать delimiter,
если quoting установлен в и quotechar, если doublequote —
. При чтении escapechar удаляет какое-либо особое значение со
следующего символа. По умолчанию используется значение , которое
отключает экранирование.
-
Используемая строка используемая для завершения строки, произведенная . По
умолчанию используется значение .Примечание
В жёсто закодированы опознавательные символы или
как конец строки и игнорирует lineterminator. Это поведение может измениться в
будущем.
-
Одиносимвольная строка используемая для заковычивания полей, содержащих
специальные символы, такие как delimiter или quotechar, или которые содержат
символы новой строки. По умолчанию используется значение .
-
Контролирует, когда кавычки должны генерироваться writer и распознаваться
reader. Он может принимать любые константы (см. раздел
) и по умолчанию имеет значение .
-
При , пробелы непосредственно следующие за delimiter, игнорируются.
Значение по умолчанию — .
Указание разделителя¶
Иногда в качестве разделителя используются другие значения. В таком
случае должна быть возможность подсказать модулю, какой именно
разделитель использовать.
Например, если в файле используется разделитель (файл
sw_data2.csv):
hostname;vendor;model;location sw1;Cisco;3750;London sw2;Cisco;3850;Liverpool sw3;Cisco;3650;Liverpool sw4;Cisco;3650;London
Достаточно просто указать, какой разделитель используется в reader (файл
csv_read_delimiter.py):
import csv
with open('sw_data2.csv') as f
reader = csv.reader(f, delimiter=';')
for row in reader
print(row)
Запись¶
Аналогичным образом с помощью модуля csv можно и записать файл в формате
CSV (файл csv_write.py):
import csv
data = ,
'sw1', 'Cisco', '3750', 'London, Best str'],
'sw2', 'Cisco', '3850', 'Liverpool, Better str'],
'sw3', 'Cisco', '3650', 'Liverpool, Better str'],
'sw4', 'Cisco', '3650', 'London, Best str']]
with open('sw_data_new.csv', 'w') as f
writer = csv.writer(f)
for row in data
writer.writerow(row)
with open('sw_data_new.csv') as f
print(f.read())
В примере выше строки из списка сначала записываются в файл, а затем
содержимое файла выводится на стандартный поток вывода.
Вывод будет таким:
$ python csv_write.py hostname,vendor,model,location sw1,Cisco,3750,"London, Best str" sw2,Cisco,3850,"Liverpool, Better str" sw3,Cisco,3650,"Liverpool, Better str" sw4,Cisco,3650,"London, Best str"
Обратите внимание на интересную особенность: строки в последнем столбце
взяты в кавычки, а остальные значения — нет. Так получилось из-за того, что во всех строках последнего столбца есть
запятая
И кавычки указывают на то, что именно является целой строкой.
Когда запятая находится в кавычках, модуль csv не воспринимает её как
разделитель
Так получилось из-за того, что во всех строках последнего столбца есть
запятая. И кавычки указывают на то, что именно является целой строкой.
Когда запятая находится в кавычках, модуль csv не воспринимает её как
разделитель.
Иногда лучше, чтобы все строки были в кавычках. Конечно, в данном случае
достаточно простой пример, но когда в строках больше значений, то
кавычки позволяют указать, где начинается и заканчивается значение.
Модуль csv позволяет управлять этим. Для того, чтобы все строки
записывались в CSV-файл с кавычками, надо изменить скрипт таким образом
(файл csv_write_quoting.py):
import csv
data = ,
'sw1', 'Cisco', '3750', 'London, Best str'],
'sw2', 'Cisco', '3850', 'Liverpool, Better str'],
'sw3', 'Cisco', '3650', 'Liverpool, Better str'],
'sw4', 'Cisco', '3650', 'London, Best str']]
with open('sw_data_new.csv', 'w') as f
writer = csv.writer(f, quoting=csv.QUOTE_NONNUMERIC)
for row in data
writer.writerow(row)
with open('sw_data_new.csv') as f
print(f.read())
Теперь вывод будет таким:
$ python csv_write_quoting.py "hostname","vendor","model","location" "sw1","Cisco","3750","London, Best str" "sw2","Cisco","3850","Liverpool, Better str" "sw3","Cisco","3650","Liverpool, Better str" "sw4","Cisco","3650","London, Best str"
Теперь все значения с кавычками. И поскольку номер модели задан как
строка в изначальном списке, тут он тоже в кавычках.
Кроме метода writerow, поддерживается метод writerows. Ему можно
передать любой итерируемый объект.
Например, предыдущий пример можно записать таким образом (файл
csv_writerows.py):
import csv
data = ,
'sw1', 'Cisco', '3750', 'London, Best str'],
'sw2', 'Cisco', '3850', 'Liverpool, Better str'],
'sw3', 'Cisco', '3650', 'Liverpool, Better str'],
'sw4', 'Cisco', '3650', 'London, Best str']]
with open('sw_data_new.csv', 'w') as f
writer = csv.writer(f, quoting=csv.QUOTE_NONNUMERIC)
writer.writerows(data)
with open('sw_data_new.csv') as f
print(f.read())
Разбор CSV-файлов с pandas библиотекой
Конечно, библиотека CSV – не единственная. Чтение CSV-файлов также возможно используя . Настоятельно рекомендуется, если у вас много данных для анализа.
– это Python библиотека с открытым исходным кодом, которая предоставляет высокопроизводительные инструменты анализа данных и простые в использовании структуры данных. доступно везде, но является ключевой частью дистрибутива Anaconda и отлично работает в записных книжках Jupyter для обмена данными, кодом, результатами анализа, визуализациями и текстовым описанием.
Установка и ее зависимости в :
Как используется / для других случаев:
Мы не будем углубляться в особенности того, как работает или как его использовать. Для более подробной информации о том, как использовать для чтения и анализа больших наборов данных.
Чтение CSV-файлов используя
Чтобы продемонстрировать некоторые возможности с CSV, я создал немного более сложный файл для чтения под названием . Он содержит данные о сотрудниках компании:
Читать CSV в быстро и просто:
Вот и все: три строки кода, и только одна из них выполняет настоящую работу. открывает, анализирует и считывает предоставленный файл CSV и сохраняет данные в DataFrame. Печать результатов:
Вот несколько моментов, на которые стоит обратить внимание:
- Сначала распознал, что первая строка CSV содержала имена столбцов, и использовали их автоматически.
- Тем не менее, также использует целочисленные индексы с нуля в . Это потому, что мы не сказали, каким должен быть наш индекс.
- Кроме того, если вы посмотрите на типы данных наших столбцов, вы увидите, что столбцы – и правильно преобразованы в числа, но столбец все еще является . Это легко подтверждается в интерактивном режиме:
Давайте решать эти проблемы по по порядку. Чтобы использовать другой столбец в качестве индекса , добавьте необязательный параметр :
Теперь поле является нашим индексом:
Далее, давайте исправим тип данных поля . Вы можете принудительно считать данные как дату с помощью необязательного параметра , который определяется как список имен столбцов для обработки в качестве дат:
Обратите внимание на разницу в выводе:
Дата теперь правильно отформатирована, что легко подтверждается в интерактивном режиме:
Если ваши CSV-файлы не имеют имен столбцов в первой строке, вы можете использовать необязательный параметр для предоставления списка имен столбцов. Вы также можете использовать это, если хотите переопределить имена столбцов, указанные в первой строке. В этом случае вы также должны указать игнорировать существующие имена столбцов, используя необязательный параметр :
Обратите внимание, что, поскольку имена столбцов изменились, столбцы, указанные в необязательных параметрах и , также должны быть изменены. Теперь это приводит к следующему выводу:
Написание файлов CSV с
Конечно, если вы не можете получить свои данные снова, это не принесет вам большой пользы. Записать в CSV-файл так же просто, как и прочитать. Давайте запишем данные с новыми именами столбцов в новый CSV-файл:
Единственная разница между этим кодом и кодом чтения выше состоит в том, что вызов был заменен на имя файла. Новый CSV-файл выглядит следующим образом:
Способы преобразования
Далее рассмотрим, какими программами осуществляется конвертирование CSV в VCARD.
Способ 1: CSV to VCARD
CSV to VCARD представляет собой приложение с однооконным интерфейсом, которое было создано специально для конвертирования CSV в VCARD.
- Запускаем софт, для добавления файла CSV нажимаем на кнопку «Browse».
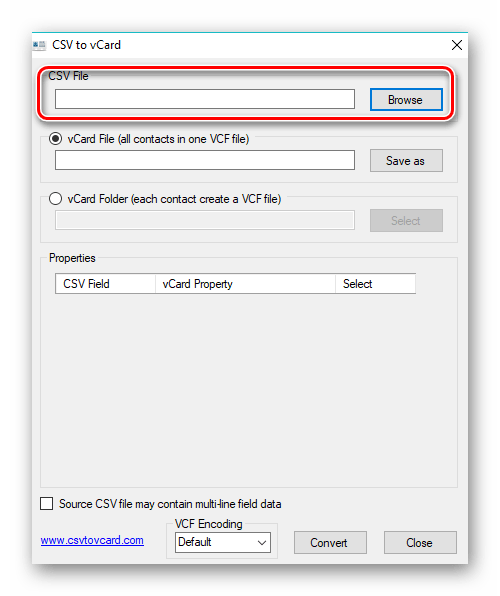
Открывается окошко «Проводника», где перемещаемся в необходимую папку, обозначаем файл, а затем жмем на «Открыть».
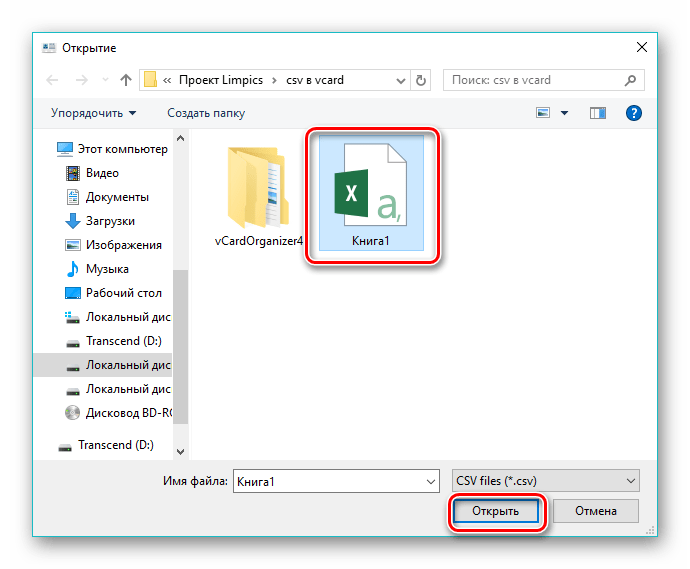
Объект импортируется в программу. Далее нужно определиться с выходной папкой, которая по умолчанию является той же, что и место хранения исходного файла. Для задания другой директории нужно щелкнуть по «Сохранить как».
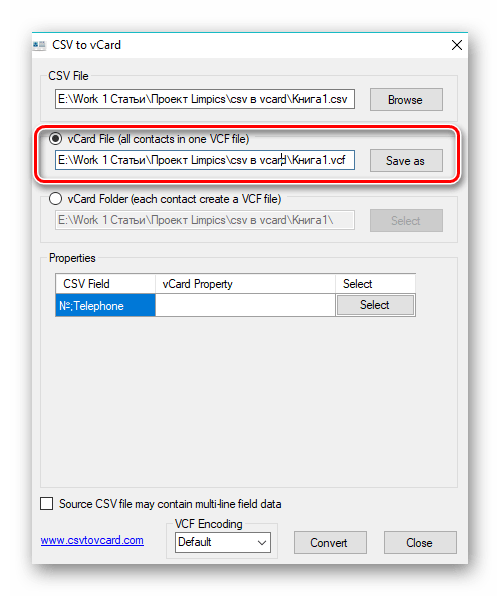
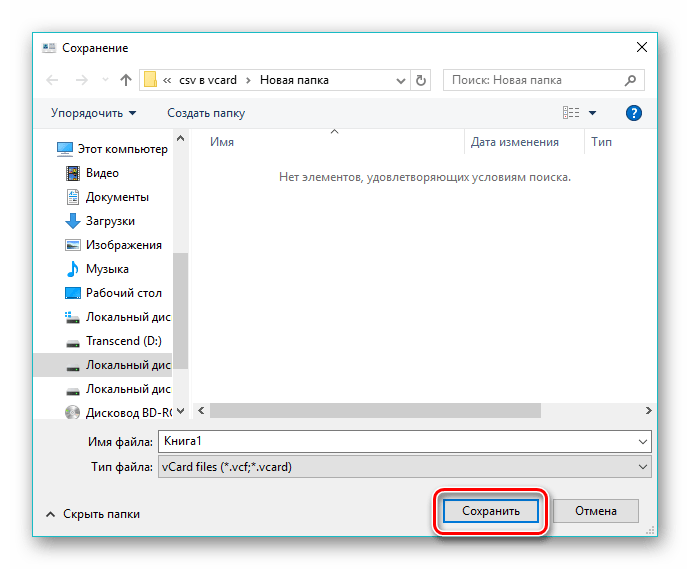
При этом открывается эксплорер, где выбираем желаемую папку и кликаем на «Сохранить». При надобности также можно отредактировать имя выходного файла.
Настраиваем соответствие полей искомого объекта с аналогичным в файле VCARD при помощи нажатия на «Select». В появившемся перечне выбираем подходящий пункт. При этом, если полей несколько, то для каждого из них необходимо будет выбрать свое значение. В данном случае указываем только одно — «Full Name», которому будут соответствовать данные из «№;Telephone».
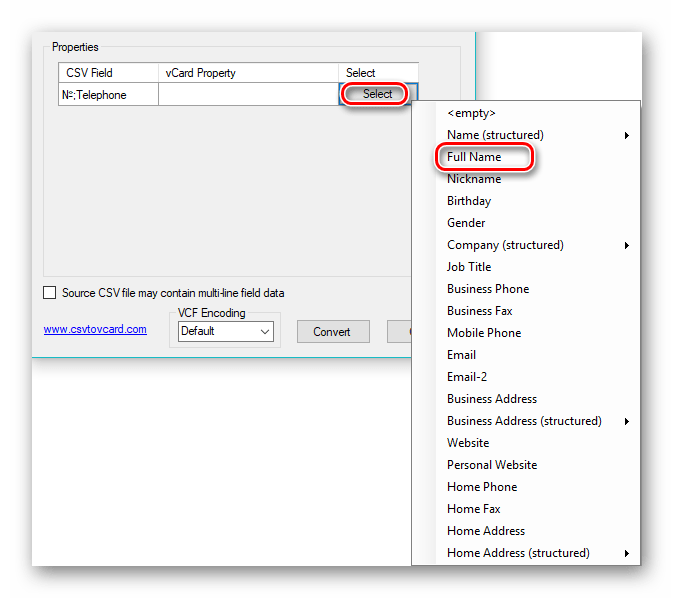
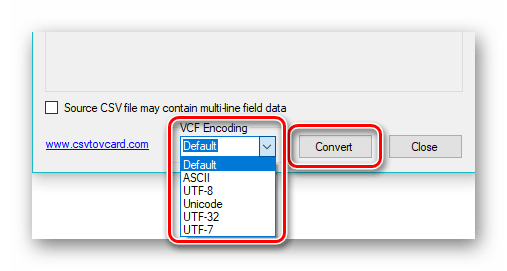
Определяем кодировку в поле «VCF Encoding». Выбираем «Default» и нажимаем на «Convert» для начала преобразования.
По завершении процесса преобразования выводится соответствующее сообщение.
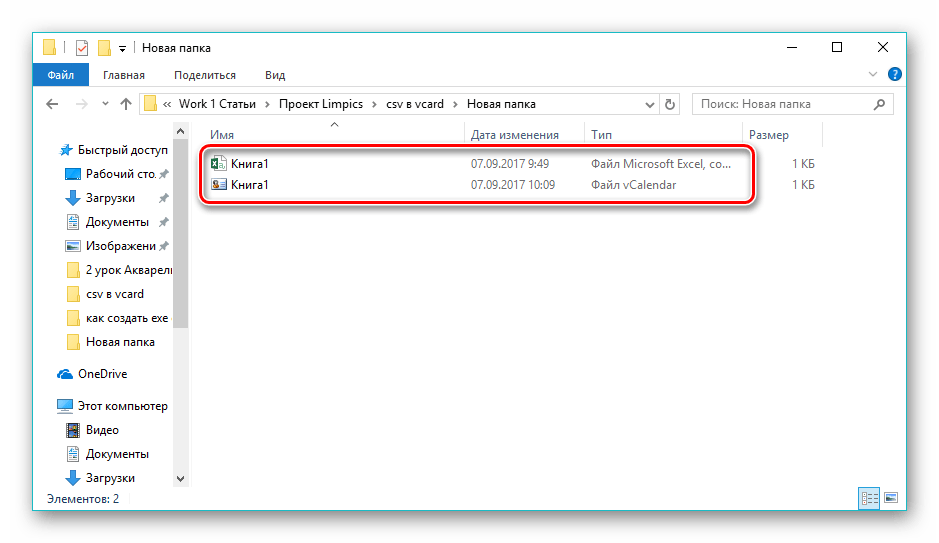
При помощи «Проводника» можно посмотреть сконвертированные файлы, перейдя в папку, которая была указана при настройке.
Способ 2: Microsoft Outlook
Microsoft Outlook является популярным почтовым клиентом, который поддерживает форматы CSV и VCARD.
- Открываем Аутлук и заходим в меню «Файл». Здесь нажимаем на «Открыть и экспортировать», а затем на «Импорт и экспорт».
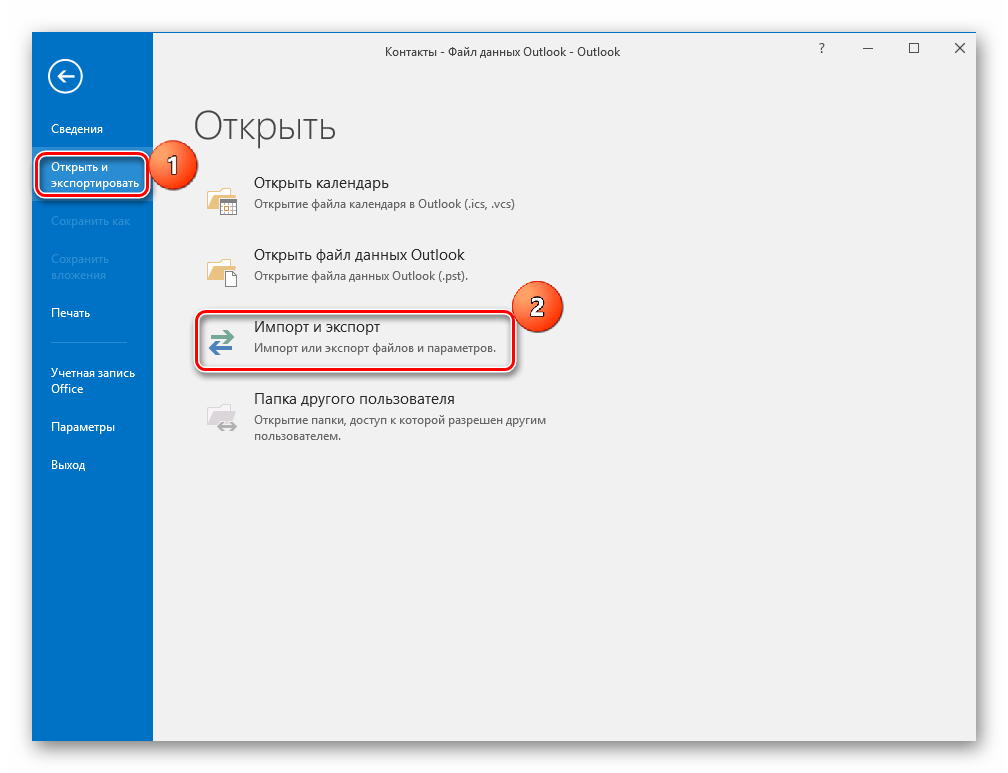
В результате открывается окно «Мастер импорта и экспорта», в котором выбираем пункт «Импорт из другой программы или файла» и кликаем «Далее».
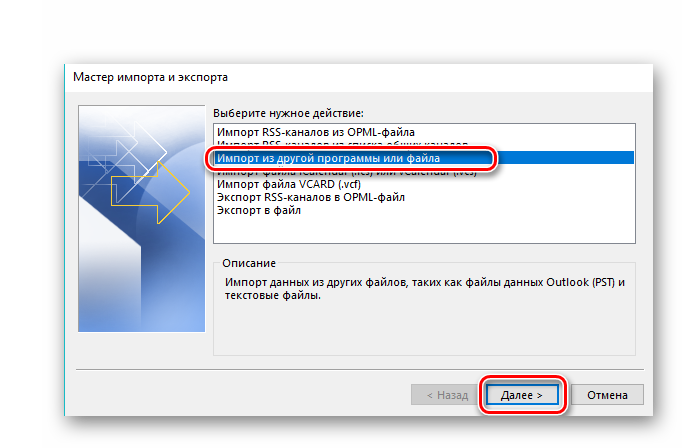
В поле «Выберите тип файла для импорта» обозначаем необходимый пункт «Значения, разделенные запятыми» и жмем «Далее».
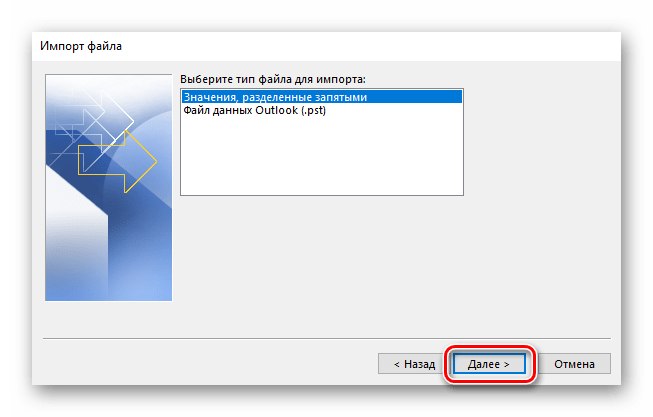
Затем нажимаем по кнопке «Обзор» для открытия исходного CSV файла.
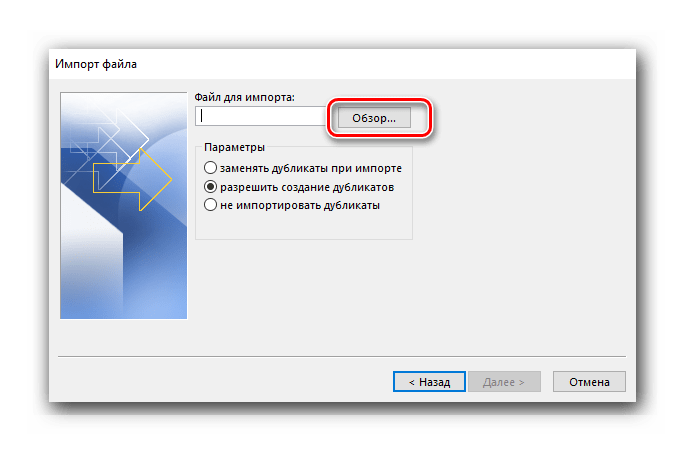
В результате открывается «Проводник», в котором двигаемся к нужной директории, выделяем объект и щелкаем «ОК».
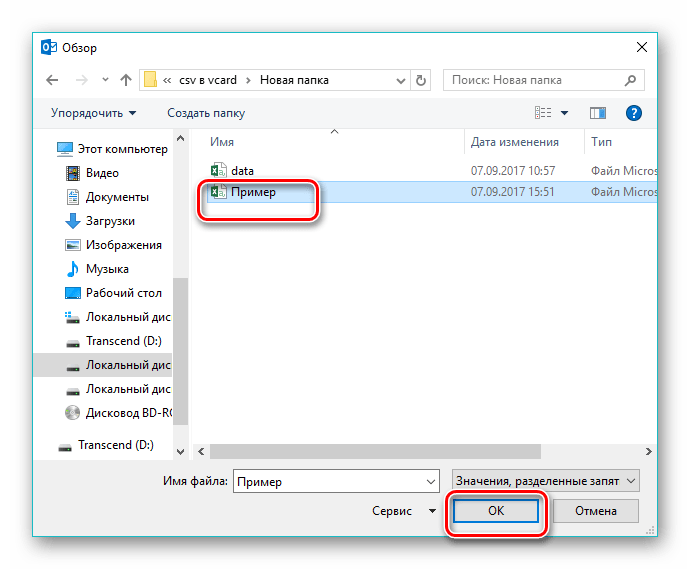
Файл добавляется в окно импорта, где в определённой строке отображается путь к нему. Здесь еще необходимо определить правила работы с дубликатами контактов. Доступны всего три варианта при обнаружении аналогичного контакта. В первом он будет заменяться, во втором будет создана копия, а в третьем – будет проигнорирован. Оставляем рекомендуемое значение «Разрешить создание дубликатов» и кликаем «Далее».
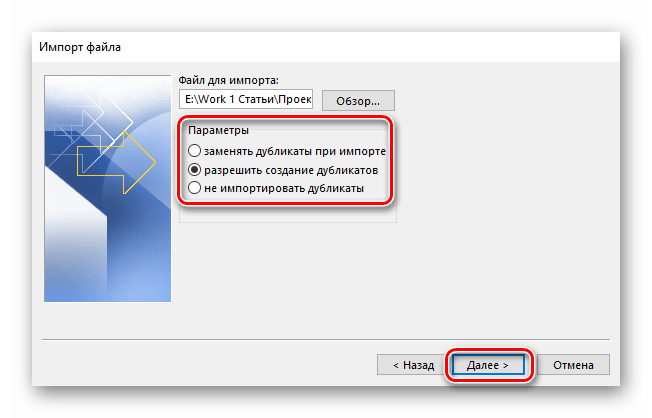
Выбираем папку «Контакты» в Outlook, где должны быть сохранены импортированные данные, после чего жмем на «Далее».
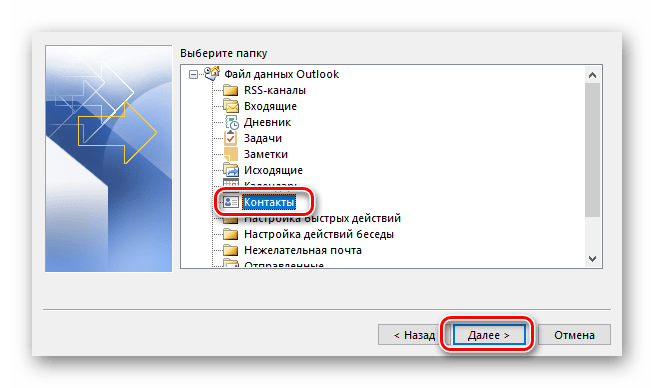
Возможно также задать соответствие полей, нажав одноименную кнопку. Это поможет избежать нестыковок данных при импорте. Подтверждаем импортирование, поставив галочку в поле «Импорт…» и нажимаем «Готово».
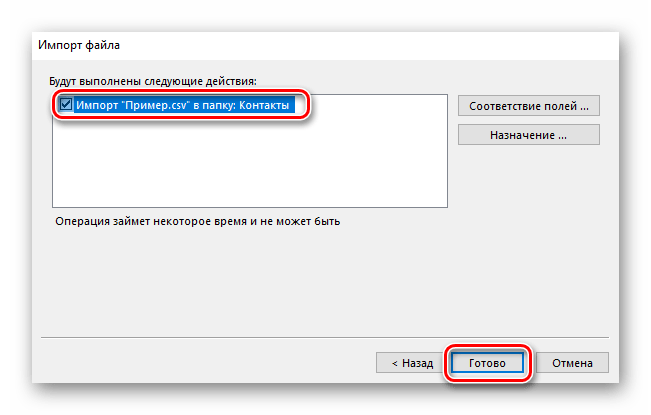
Исходный файл импортируется в приложение. Для того чтобы увидеть все контакты, необходимо щелкнуть по пиктограмме в виде людей в нижней части интерфейса.
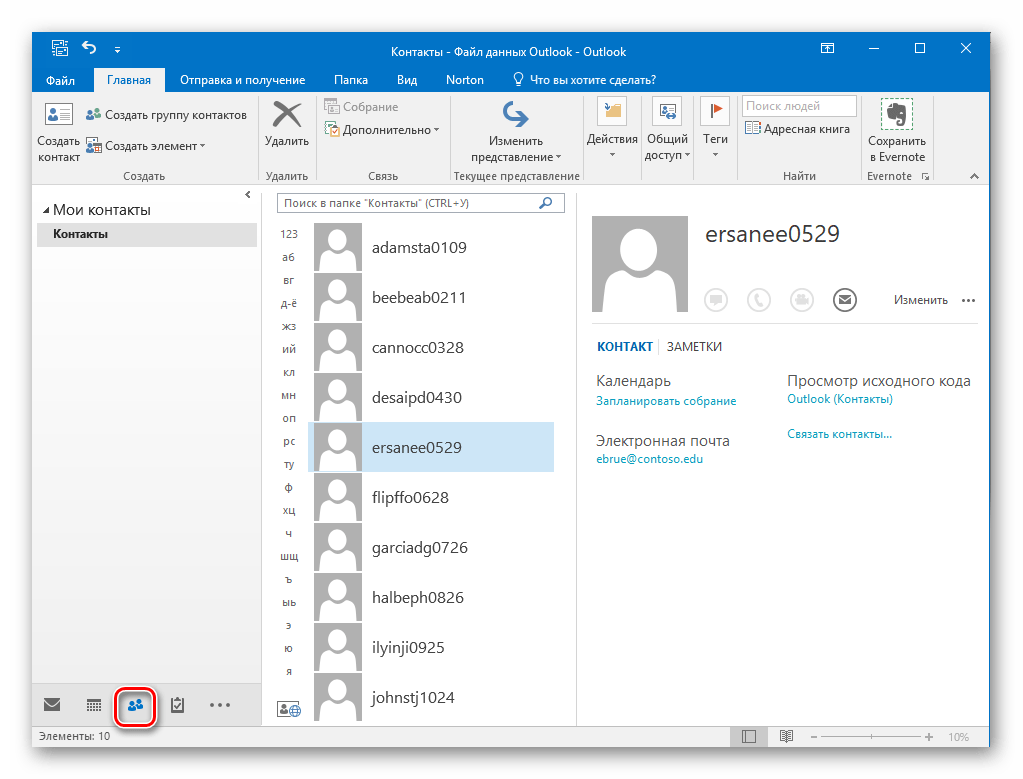
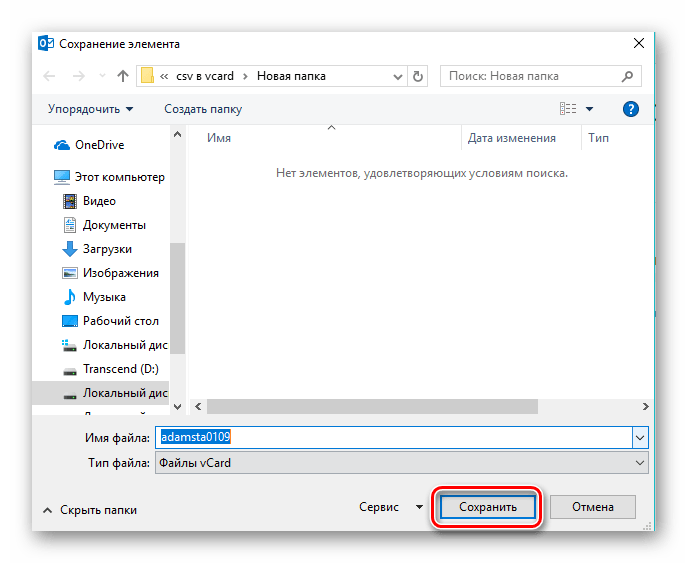
К сожалению, Аутлук позволяет сохранять в формате vCard только один контакт за раз. При этом, еще нужно помнить, что по умолчанию сохраняется контакт, который предварительно выделен. После этого заходим в меню «Файл», где жмем «Сохранить как».

Запускается обозреватель, в котором перемещаемся в желаемую директорию, при необходимости прописываем новое имя визитной карточки и щелкаем «Сохранить».
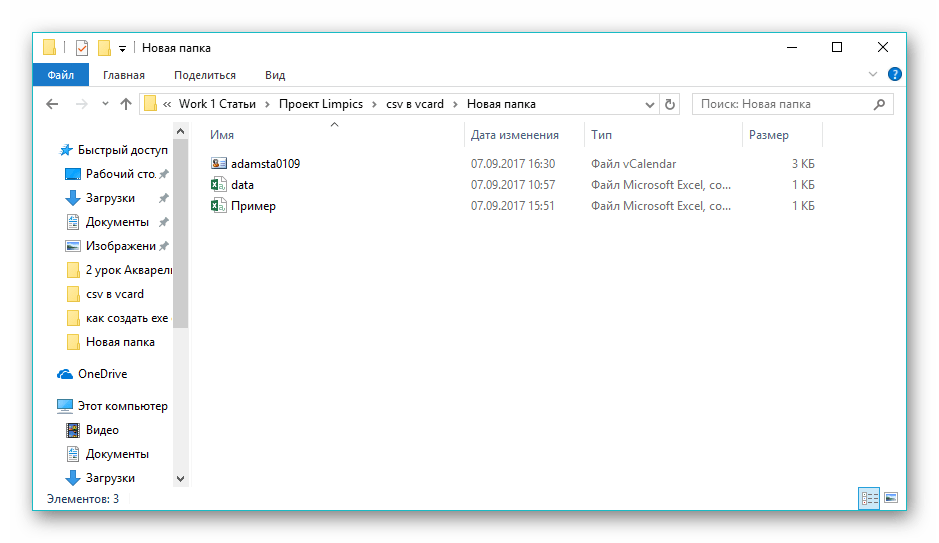
На этом процесс преобразования заканчивается. К сконвертированному файлу можно получить доступ с использованием «Проводника» Windows.
Таким образом, можно сделать вывод, что обе рассмотренные программы справляются с задачей конвертирования CSV в VCARD. При этом, наиболее удобно процедура реализована в CSV to VCARD, интерфейс которого прост и интуитивно понятен, несмотря на английский язык. Microsoft Outlook предоставляет более широкий функционал по обработке и импорту файлов CSV, но при этом сохранение в формат VCARD осуществляется только по одному контакту.
Опишите, что у вас не получилось.
Наши специалисты постараются ответить максимально быстро.
Запись файлов CSV
Мы также можем не только читать, но и писать любые новые и существующие файлы CSV. Запись файлов на Python осуществляется с помощью модуля csv.writer(). Он похож на модуль csv.reader() и также имеет два метода, то есть функцию записи или класс Dict Writer.
Он представляет две функции: writerow() и writerows(). Функция writerow() записывает только одну строку, а функция writerows() записывает более одной строки.
Диалекты
Они определяются как конструкция, которая позволяет создавать, хранить и повторно использовать различные параметры форматирования. Диалект поддерживает несколько атрибутов; наиболее часто используются:
- Dialect.delimiter: этот атрибут используется как разделительный символ между полями. Значение по умолчанию – запятая(,).
- Dialect.quotechar: этот атрибут используется для выделения полей, содержащих специальные символы, в кавычки.
- Dialect.lineterminator: используется для создания новых строк, значение по умолчанию – ‘\r\n’.
Запишем следующие данные в файл CSV.
data =
Пример –
import csv
with open('Python.csv', 'w') as csvfile:
fieldnames =
writer = csv.DictWriter(csvfile, fieldnames=fieldnames)
writer.writeheader()
writer.writerow({'Rank': 'B', 'first_name': 'Parker', 'last_name': 'Brian'})
writer.writerow({'Rank': 'A', 'first_name': 'Smith',
'last_name': 'Rodriguez'})
writer.writerow({'Rank': 'B', 'first_name': 'Jane', 'last_name': 'Oscar'})
writer.writerow({'Rank': 'B', 'first_name': 'Jane', 'last_name': 'Loive'})
print("Writing complete")
Выход:
Writing complete
Он возвращает файл с именем Python.csv, который содержит следующие данные:
first_name,last_name,Rank Parker,Brian,B Smith,Rodriguez,A Jane,Oscar,B Jane,Loive,B
Способ 4: Viewer от Groupdocs
Еще один метод открытия CSV при помощи браузера. Особенность этого онлайн-сервиса по сравнению с предыдущими ресурсами следующая: он конвертирует CSV в графический файл для просмотра и не поддерживает изменение кодировки. Однако если нужно просто узнать, что находится внутри документа, то он подойдет.
- Войдите на сайт Groupdocs в раздел с инструментом для просмотра всех поддерживаемых форматов документов. Ссылка на него представлена выше. Кликните левой кнопкой мыши в любом месте активного поля «Click or drop your file here».
Выберите документ в формате CSV через стандартный файловый менеджер «Проводник», найдя диск и каталог, где он находится.
Дождитесь обработки файла и загрузки страницы с его содержимым. Оно будет представлено в формате картинки. Сервис обрабатывает CSV именно таким образом.
При желании скопируйте изображение, нажав по нему правой кнопкой мыши и выбрав пункт контекстного меню «Сохранить изображение как…».
Укажите диск и папку для сохранения картинки и подтвердите действие. После скачивания файл переместится в нужную директорию по указанному пути.
Pandas dataframe to_csv () синтаксис
Синтаксис функции dataframe to_csv ():
def to_csv(
self,
path_or_buf=None,
sep=",",
na_rep="",
float_format=None,
columns=None,
header=True,
index=True,
index_label=None,
mode="w",
encoding=None,
compression="infer",
quoting=None,
quotechar='"',
line_terminator=None,
chunksize=None,
date_format=None,
doublequote=True,
escapechar=None,
decimal=".",
)
Некоторые из важных параметров:
- path_or_buf : Объект файла для записи данных CSV. Если этот аргумент не предоставлен, данные CSV возвращаются в виде строки.
- Сен : разделитель для данных CSV. Это должна быть строка длины 1, по умолчанию является запятой.
- na_rep : Строка, представляющая нулевые или отсутствующие значения, по умолчанию пустая строка.
- Колонны : последовательность, чтобы указать столбцы, чтобы включить в вывод CSV.
- Заголовок : Допустимые значения логические или список строки, по умолчанию верно. Если false, имена столбцов не записываются на выходе. Если список строки, он используется для записи имен столбцов. Длина списка строки должна быть такой же, как количество столбцов, написанных в файле CSV.
- индекс : Если true, индекс включен в данные CSV. Если false, значение индекса не записано на выходе CSV.
- index_label : Используется для указания имени столбца для индекса.
Чем открыть CSV файл на компьютере
Табличные процессоры – программы для работы с таблицами, которые делают процесс их просмотра на компьютере максимально комфортным. Предлагаем три эффективных варианта, с помощью которых можно запускать файлы CSV.
Microsoft Excel
Microsoft Excel – программа для просмотра таблиц. Входит в пакет Microsoft Office. Подойдёт любая версия – расширение CSV поддерживается всеми.
Для корректного отображения данных (сохранится структура) придётся настроить некоторые параметры:
- Перейдите в раздел «Открыть» («File»), нажмите на «Обзор».
- Выберите тип отображения «Все файлы», чтобы окно проводника отобразило искомый. Откройте объект.
- Если текст открылся без мастера текстов и отображается не так, как должен, перейдите в раздел «Данные», разверните опцию «Получить данные», перейдите в пункт «Из файла», выберите «Из текстового…». Найдите и откройте документ в формате CSV.
- Подберите разделитель, при котором содержимое будет отображаться правильно. В графе «Источник…» («Format») установите параметр «Юникод (UTF-8)». Нажмите на «Преобразовать данные».
- Кликните по кнопке «Закрыть и загрузить».
- Документ откроется в новом листе, результат можно сравнить с предыдущим.
Если приобретать Excel не хочется, можно воспользоваться бесплатными аналогами – например, LibreOffice или OpenOffice.
LibreOffice Calc
Табличный процессор Calc входит в пакет LibreOffice. Распространяется бесплатно, умеет работать с файлами формата CSV.
Для открытия документа следуйте такому алгоритму:
- Откройте LibreOffice, нажмите на «», выберите документ в формате CSV через проводник.
- Запустится инструмент «Импорт текста». Всё собрано в одном окне – установите вариант кодировки «Юникод (UTF-8)», укажите язык текста, настройте параметры разделителя, нажмите на «ОК».
- Содержимое откроется в Calc, можно просматривать и редактировать.
Существует ещё одно бесплатное полнофункциональное средство для работы с таблицами – о нём далее.
OpenOffice Calc
Calc из пакета OpenOffice мало чем отличается от предыдущих решений – после настройки дополнительных параметров любой документ, имеющий требуемое нам расширение, откроется без каких-либо проблем.
Работает так:
- Запустите OpenOffice, нажмите на «Open», выберите объект.
- Настройте тип данных, язык, параметры разделителя – всё в точности так, как в предыдущих решениях.
- Запустится Calc с обработанным документом.
OpenOffice бесплатен, а установочный пакет даже «легче», чем у LibreOffice.
daСклонение: склонение ФИО, должностей, чисел, прилагательных, существительных на языке 1С + ТестЦентр Промо
Функция предназначена для склонения выражений, которые часто требуется при формировании печатных форм договоров и прочих печатных форм. Функция склоняет по падежам ФИО, должности, числительные, валюты, единицы измерения, предметы. Также функция склоняет глаголы и прилагательные по числам и родам и существительные по числам. Имеется режим определения рода переданного выражения. Поддержка форматной строки для вывода результата. Функция не использует внешние библиотеки и веб-сервисы, написана на чистом языке 1С, и поэтому легко встраивается в любую конфигурацию или внешнюю обработку. Правила склонения оформлены в виде таблицы и могут быть легко изменены при необходимости.
1 стартмани
Рассмотрим загрузку CSV файла через утилиту bcp
При загрузке CSV файла, приведенного в примере, через утилиту bcp или операцией BULK INSERT мы можем получить несколько ошибок. Например, выполним команду:
В результате мы получим ошибку Недопустимое имя объекта «##multiline_csv»:
Создадим таблицу ##multiline_csv запросом:
После этого загрузим снова наш файл с помощью той же команды и получим результат
На первый взгляд, кажется, что команда успешно выполнилась и данные загрузились в БД
Обратим внимание, на сообщение 3 rows copied — это правильный результат. Но как записи сохранились в БД? Проверим результат запросом SELECT * FROM ##multiline_csv:

Первая строка с заголовком загрузилась верно. А на второй строке в поле column4 мы видим только «Это пример, хотя должны были увидеть Это пример «многострочного» примечания с двойными кавычками:
Как видим, результат неверный и такую проблему не решить на уровне bcp или BULK INSERT. Остается только править файл вручную и искать эти двойные многострочные значения избавляясь от многострочности или приводя все поля к двойным кавычкам.
Как структурированы csv файлы
Шаблоны CSV или файлы данных можно загрузить по ссылкам в верхней части инструмента «Загрузить данные». Первая строка шаблона или файла данных содержит заголовки столбцов. Каждая последующая строка соответствует записи в базе данных. Когда загружается шаблон CSV, он содержит только заголовки столбцов. Поскольку шаблоны используются для добавления новых записей, новые строки будут добавляться для каждой записи.
Когда документ данных CSV загружается, первая строка содержит заголовок столбца, а последующие строки содержат записи данных, которые уже существуют в базе данных. Записи в этих строках можно редактировать или удалять.
В документе CSV каждая строка содержит упорядоченную последовательность заголовков столбцов или значений, разделенных запятыми. Запятые используются для сохранения файловой структуры. Каждая запятая в первой строке (которая содержит заголовки столбцов) разделяет заголовок столбца и место в упорядоченной последовательности столбцов.
Запятые в последующих строках также поддерживают последовательность упорядоченных столбцов, поэтому первое значение в каждой последующей строке представляет значение в первом столбце, второе значение в каждой последующей строке представляет значение во втором столбце и так далее. В отличие от стандартной пунктуации предложений, после запятой не ставится пробел.
Большинство значений заключено в двойные кавычки. Исключением является односимвольное значение, например 1 или 0 (ноль). Заключение значения в двойные кавычки позволяет использовать в поле сложные значения, например, содержащие запятые, без нарушения структуры документа. Например, поле, содержащее ряд элементов, например избранные цвета, может иметь такое значение:
“красный, зеленый и синий”
Вы не будете знать об этих цитатах при просмотре файла данных в приложении для работы с электронными таблицами, но они появляются, когда file просматривается в текстовом редакторе.
Чтение файлов CSV
Python предоставляет различные функции для чтения файла CSV. Опишем несколько методов для чтения.
Использование функции csv.reader()
В Python модуль csv.reader() используется для чтения файла csv. Он берет каждую строку файла и составляет список всех столбцов.
Мы взяли текстовый файл с именем python.txt, в котором есть разделитель по умолчанию(,) со следующими данными:
name,department,birthday month Parker,Accounting,November Smith,IT,October
Пример:
import csv
with open('python.csv') as csv_file:
csv_reader = csv.reader(csv_file, delimiter=',')
line_count = 0
for row in csv_reader:
if line_count == 0:
print(f'Column names are {", ".join(row)}')
line_count += 1
Выход:
Column names are name, department, birthday month Parker works in the Accounting department, and was born in November. Smith works in the IT department, and was born in October. Processed 3 lines.
В приведенном выше коде мы открыли python.csv с помощью функции open(). Мы использовали функцию csv.reader() для чтения файла, который возвращает итеративный объект чтения. Объект чтения состоял из данных, и мы повторили цикл, используя цикл for, чтобы распечатать содержимое каждой строки.
Чтение CSV файла в PHP
Есть еще функция fgetcsv(), но она оказалась капризной и не всегда работает как нужно (может перепутать переносы строк)…
Вариант на базе функции str_getcsv():
## Читает CSV файл и возвращает данные в виде массива.
## @param string $file_path Путь до csv файла.
## string $col_delimiter Разделитель колонки (по умолчанию автоопределине)
## string $row_delimiter Разделитель строки (по умолчанию автоопределине)
## ver 6
function kama_parse_csv_file( $file_path, $file_encodings = , $col_delimiter = '', $row_delimiter = "" ){
if( ! file_exists($file_path) )
return false;
$cont = trim( file_get_contents( $file_path ) );
$encoded_cont = mb_convert_encoding( $cont, 'UTF-8', mb_detect_encoding($cont, $file_encodings) );
unset( $cont );
// определим разделитель
if( ! $row_delimiter ){
$row_delimiter = "\r\n";
if( false === strpos($encoded_cont, "\r\n") )
$row_delimiter = "\n";
}
$lines = explode( $row_delimiter, trim($encoded_cont) );
$lines = array_filter( $lines );
$lines = array_map( 'trim', $lines );
// авто-определим разделитель из двух возможных: ';' или ','.
// для расчета берем не больше 30 строк
if( ! $col_delimiter ){
$lines10 = array_slice( $lines, 0, 30 );
// если в строке нет одного из разделителей, то значит другой точно он...
foreach( $lines10 as $line ){
if( ! strpos( $line, ',') ) $col_delimiter = ';';
if( ! strpos( $line, ';') ) $col_delimiter = ',';
if( $col_delimiter ) break;
}
// если первый способ не дал результатов, то погружаемся в задачу и считаем кол разделителей в каждой строке.
// где больше одинаковых количеств найденного разделителя, тот и разделитель...
if( ! $col_delimiter ){
$delim_counts = array( ';'=>array(), ','=>array() );
foreach( $lines10 as $line ){
$delim_counts[] = substr_count( $line, ',' );
$delim_counts[] = substr_count( $line, ';' );
}
$delim_counts = array_map( 'array_filter', $delim_counts ); // уберем нули
// кол-во одинаковых значений массива - это потенциальный разделитель
$delim_counts = array_map( 'array_count_values', $delim_counts );
$delim_counts = array_map( 'max', $delim_counts ); // берем только макс. значения вхождений
if( $delim_counts === $delim_counts )
return array('Не удалось определить разделитель колонок.');
$col_delimiter = array_search( max($delim_counts), $delim_counts );
}
}
$data = [];
foreach( $lines as $key => $line ){
$data[] = str_getcsv( $line, $col_delimiter ); // linedata
unset( $lines );
}
return $data;
}
Использование:
$data = kama_parse_csv_file( '/path/to/file.csv' ); print_r( $data );




